Содержание статьи

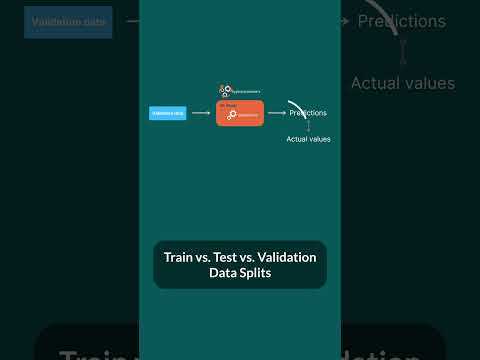
При обучении нейронных сетей в Keras важно заранее определить, какие данные будут использоваться для настройки весов, а какие – для контроля качества обучения. Параметр validation_split в методе model.fit() задаёт долю обучающего массива, которая автоматически отделяется под валидацию. Например, значение 0.2 означает, что 20% исходных данных не участвуют в обновлении весов и применяются только для расчёта метрик после каждой эпохи.
В отличие от ручного разбиения через NumPy или scikit-learn, validation_split работает внутри Keras и использует уже переданные в fit массивы. При этом разделение происходит по порядку данных: сначала формируется обучающая часть, затем валидационная. Это поведение напрямую влияет на результаты, если данные отсортированы по времени, классам или другим признакам, и требует осознанного применения перемешивания.
Параметр применим только при передаче данных в виде массивов или тензоров. При использовании tf.data.Dataset, генераторов или Sequence-объектов он игнорируется, и разработчику необходимо явно задавать validation_data. Понимание этих ограничений помогает избежать ситуаций, когда валидация формально указана, но фактически не используется.
Правильная настройка validation_split позволяет отслеживать переобучение, сравнивать динамику метрик и принимать решения о количестве эпох или настройке колбэков, таких как EarlyStopping. Этот механизм особенно полезен на этапах быстрого прототипирования моделей, когда требуется минимальное количество вспомогательного кода.
Validation split в Keras: что это и как работает
Параметр validation_split управляет автоматическим выделением части обучающих данных для проверки модели в процессе обучения. Он передаётся в метод model.fit() и принимает значение от 0 до 1, где число определяет долю данных, исключаемых из обучения. Например, при указании 0.1 каждая эпоха будет завершаться вычислением метрик на 10% исходного массива.
Keras выполняет разбиение детерминированно: валидационный набор формируется из последней части входных данных без случайного выбора. Перемешивание, активируемое параметром shuffle, применяется уже после выделения этой части. Поэтому при подаче отсортированных данных валидация может содержать только один сегмент распределения, что искажает оценку качества модели.
При использовании validation_split важно учитывать тип входных данных. Механизм поддерживается только для массивов и тензоров, передаваемых напрямую. Если обучение построено на генераторах или пайплайнах tf.data, параметр не оказывает влияния, и валидационные данные необходимо передавать явно через validation_data.
Данные, выделенные под валидацию, не участвуют в обратном распространении ошибки и не влияют на обновление весов. Они применяются исключительно для мониторинга значений функции потерь и метрик, что позволяет контролировать расхождение между обучением и проверкой на каждой эпохе.
Практика показывает, что validation_split удобен на этапе прототипирования и экспериментов с архитектурой модели. Для задач с временной зависимостью, сложной структурой данных или требованиями к строгому контролю состава выборок предпочтительнее выполнять разбиение заранее и передавать готовые наборы данных в явном виде.
Что означает параметр validation_split при вызове model.fit
Параметр validation_split в методе model.fit() задаёт долю входных данных, которая будет автоматически отделена от обучения и использована для проверки модели. Значение указывается в виде числа с плавающей точкой от 0 до 1. При validation_split=0.2 Keras использует 80% данных для обновления весов и 20% – для вычисления валидационных метрик после каждой эпохи.
Разбиение выполняется однократно перед началом обучения и основывается на порядке элементов во входных массивах. Валидационная выборка формируется из последней части данных, а не выбирается случайным образом. Параметр shuffle не влияет на состав валидации, так как перемешивание применяется только к обучающей части уже после отделения валидационного сегмента.
При указании validation_split не требуется вручную подготавливать отдельные массивы для проверки, однако это возможно только при передаче данных напрямую в виде NumPy-массивов или TensorFlow-тензоров. Если используется генератор данных или объект tf.data.Dataset, параметр будет проигнорирован, и проверочные данные необходимо передавать через validation_data.
Данные, выделенные с помощью validation_split, не участвуют в вычислении градиентов и не влияют на процесс оптимизации. Они используются исключительно для расчёта val_loss и валидационных метрик, которые затем применяются колбэками, такими как EarlyStopping или ModelCheckpoint.
На практике рекомендуется выбирать значение validation_split в диапазоне от 0.1 до 0.3, ориентируясь на размер набора данных и устойчивость метрик. Для малых выборок автоматическое разбиение может приводить к нестабильным оценкам, поэтому в таких случаях предпочтительнее контролировать состав валидации вручную.
Как Keras выбирает данные для валидации при использовании validation_split

При задании параметра validation_split Keras формирует валидационную выборку на основе порядка входных данных. Из общего массива сначала вычисляется количество элементов, соответствующее указанной доле, после чего эти элементы отбираются из конца набора данных и резервируются для валидации.
Процедура разбиения выполняется до начала обучения и не содержит случайной составляющей. Даже если параметр shuffle=True, он применяется только к обучающей части данных и не влияет на состав валидационной выборки. Это означает, что при подаче данных, отсортированных по времени, метке класса или любому другому признаку, валидация будет представлять лишь один фрагмент распределения.
Если входные данные представлены несколькими массивами, например x и y, разбиение выполняется синхронно по первой размерности. Keras гарантирует, что соответствие между признаками и целевыми значениями сохраняется, а одинаковые индексы из обоих массивов попадают в одну и ту же часть выборки.
При использовании дополнительных входов, таких как массивы sample_weight, они также делятся по тому же принципу. Это позволяет корректно рассчитывать взвешенные метрики на валидации без дополнительной настройки со стороны пользователя.
Для корректной оценки качества модели рекомендуется предварительно перемешивать данные вручную, если порядок элементов не несёт смысловой нагрузки. В задачах с временной структурой или последовательными наблюдениями автоматическое выделение последних элементов под валидацию может быть оправдано, но требует осознанного контроля.
Влияние перемешивания данных (shuffle) на validation_split

Параметр shuffle в методе model.fit() часто воспринимается как способ случайного формирования обучающей и валидационной выборок, однако в сочетании с validation_split он выполняет иную задачу. Разделение данных на обучающую и валидационную части происходит до перемешивания, поэтому значение shuffle не влияет на состав валидации.
После выделения валидационной части перемешиванию подвергается только обучающий набор. Это поведение важно учитывать при подготовке данных, особенно если входные массивы имеют упорядоченную структуру. На практике это приводит к следующим последствиям:
- валидация всегда формируется из последних элементов входного массива;
- перемешивание не снижает риск смещения валидации при отсортированных данных;
- результаты валидации могут отражать локальные особенности данных, а не общее распределение.
Если данные были предварительно перемешаны вручную, параметр shuffle=True обеспечивает дополнительное перераспределение обучающих примеров между эпохами, что помогает стабилизировать процесс обучения. При этом валидационная часть остаётся неизменной на протяжении всех эпох.
В задачах с временной зависимостью или последовательными наблюдениями отключение перемешивания может быть оправдано. В таких случаях комбинация shuffle=False и validation_split позволяет использовать последние наблюдения как контрольный набор, имитируя проверку модели на будущих данных.
Для классификационных задач с дисбалансом классов рекомендуется выполнять стратифицированное перемешивание до передачи данных в model.fit(). Это позволяет избежать ситуации, когда валидация содержит непропорциональное распределение меток, на которое параметр shuffle уже не способен повлиять.
Ограничения validation_split при работе с генераторами и tf.data
Параметр validation_split применяется только при передаче данных в model.fit() в виде массивов NumPy или тензоров TensorFlow. При использовании Python-генераторов, объектов keras.utils.Sequence или пайплайнов tf.data.Dataset этот параметр игнорируется, так как Keras не имеет доступа к полному объёму данных для предварительного разбиения.
Генераторы и датасеты tf.data выдают данные пакетами, часто в потоковом режиме. В таких условиях невозможно заранее определить количество элементов и корректно выделить фиксированную долю для валидации. По этой причине попытка указать validation_split не приводит к ошибке, но и не влияет на процесс обучения.
Для корректной валидации при работе с потоковыми источниками данных необходимо явно передавать проверочный набор через параметр validation_data. В случае tf.data.Dataset это обычно реализуется созданием двух независимых датасетов: один для обучения, второй для валидации, каждый со своей логикой загрузки и предобработки.
Если данные загружаются из одного источника, рекомендуется выполнять разбиение на уровне датасета с использованием методов take() и skip(), либо формировать отдельные генераторы для обучения и проверки. Такой подход обеспечивает полный контроль над составом выборок и предотвращает утечку данных между ними.
При масштабных наборах данных, где используется кеширование, параллельная загрузка и префетчинг, явное управление валидацией становится обязательным. В этих сценариях validation_split не подходит и должен рассматриваться только как инструмент для работы с небольшими, полностью загруженными в память массивами.
Различия между validation_split и передачей validation_data
В Keras предусмотрены два способа задания валидационных данных: автоматическое разбиение через validation_split и явная передача проверочного набора через validation_data. Эти механизмы решают схожую задачу, но отличаются по уровню контроля и области применения.
validation_split работает только с массивами и тензорами, уже переданными в model.fit(). Keras самостоятельно отделяет часть данных для валидации на основе их порядка, без случайного выбора. Пользователь не управляет конкретным составом валидационной выборки, что ограничивает применение в задачах со сложной структурой данных.
Передача validation_data предполагает явное указание входных и целевых данных для проверки. Этот способ поддерживается для массивов, генераторов и объектов tf.data.Dataset, позволяет точно контролировать источник и состав валидации и предотвращает неявные смещения.
| Критерий | validation_split | validation_data |
|---|---|---|
| Типы поддерживаемых данных | Массивы и тензоры | Массивы, генераторы, tf.data |
| Контроль состава валидации | Отсутствует | Полный |
| Способ формирования | Последняя часть данных | Явно заданный набор |
| Подходит для сложных пайплайнов | Нет | Да |
На практике validation_split удобен для быстрого обучения моделей на простых наборах данных, когда порядок элементов не имеет значения. validation_data предпочтителен в промышленных сценариях, при работе с потоковыми источниками, временными рядами и при необходимости строгого контроля экспериментов.
Типичные ошибки при использовании validation_split и способы их избежать

Одна из распространённых ошибок – использование validation_split с данными, отсортированными по меткам, времени или другому признаку. Поскольку валидация формируется из последней части массива, модель проверяется на ограниченном сегменте распределения. Решение заключается в предварительном перемешивании данных или в ручном формировании валидационного набора.
Часто параметр указывают при обучении на генераторах или tf.data.Dataset, предполагая, что Keras выполнит разбиение автоматически. В этом случае validation_split не применяется, а валидация фактически отсутствует. Для устранения проблемы необходимо передавать проверочные данные через validation_data или создавать отдельный датасет для валидации.
Ещё одна ошибка связана с выбором слишком большой доли валидации при небольшом объёме данных. При значениях выше 0.3 обучающая выборка может оказаться недостаточной для стабильного обновления весов. Рекомендуется соотносить размер валидации с общим числом наблюдений и анализировать разброс метрик между эпохами.
Иногда предполагается, что параметр shuffle влияет на состав валидационной выборки. Это приводит к ложному ощущению случайности разбиения. На практике перемешивается только обучающая часть, поэтому порядок входных данных должен контролироваться заранее.
Вопрос-ответ:
Почему validation_split всегда берёт данные из конца массива, а не случайно?
Keras реализует validation_split как простое детерминированное разбиение входных массивов по индексу. Сначала вычисляется размер валидационной части, затем последние элементы массива резервируются под проверку. Случайный отбор не используется, так как разбиение выполняется до этапа обучения, а параметр shuffle применяется только к обучающей части после этого шага.
Можно ли использовать validation_split при обучении модели на tf.data.Dataset?
Нет. При передаче tf.data.Dataset параметр validation_split игнорируется. Dataset не предоставляет Keras информации о полном размере и порядке элементов, поэтому автоматическое отделение части данных невозможно. Для валидации требуется заранее сформировать отдельный Dataset и передать его через validation_data.
Как validation_split влияет на работу EarlyStopping?
Колбэк EarlyStopping ориентируется на значения val_loss или других валидационных метрик, рассчитанных именно на данных, выделенных через validation_split. Если валидационная часть содержит смещённый или узкий сегмент данных, остановка обучения может сработать слишком рано или, наоборот, не сработать вовсе. Качество валидации напрямую определяет поведение этого колбэка.
Что произойдёт, если задать validation_split и validation_data одновременно?
Если указан validation_data, параметр validation_split не используется. Keras отдаёт приоритет явно переданным валидационным данным и полностью игнорирует автоматическое разбиение. Это позволяет избежать неоднозначностей, но требует внимательности при чтении кода обучения.
Подходит ли validation_split для задач с дисбалансом классов?
Чаще всего нет. Так как разбиение выполняется без стратификации, валидационная выборка может содержать непропорциональное количество классов. Это приводит к искажённым метрикам и затрудняет анализ обучения. Для таких задач лучше заранее сформировать валидационный набор с контролем распределения меток.