Содержание статьи

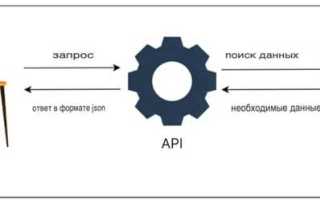
Выбор формата передачи данных в API напрямую влияет на совместимость клиентов, объём трафика, сложность валидации и скорость обработки запросов. JSON остаётся базовым вариантом для REST-интерфейсов благодаря нативной поддержке в браузерах и большинстве SDK, однако он не решает задачи строгой типизации и компактности. В системах с высокой частотой вызовов или ограниченным каналом связи это приводит к росту нагрузки и затрат на парсинг.
Для сценариев с формальными контрактами и долгим жизненным циклом API применяются XML с XSD или бинарные форматы вроде Protocol Buffers. Первый подходит для интеграций с корпоративными системами и строгими схемами, второй – для микросервисов и мобильных клиентов, где важны размер сообщений и контроль версий. Практика показывает: при переходе с JSON на Protobuf размер полезной нагрузки сокращается в 3–5 раз, но цена – необходимость генерации кода и более сложная отладка.
HTTP-форматы application/x-www-form-urlencoded и multipart/form-data применяются точечно: первый – для простых форм и OAuth-флоу, второй – для передачи файлов и смешанных наборов данных. При проектировании API важно явно ограничивать их использование, фиксировать допустимые поля и контролировать максимальные размеры, чтобы избежать неконтролируемых запросов и проблем с памятью.
Отдельного внимания требует согласование форматов через заголовки Content-Type и Accept. Явное указание версии формата, кодировки и типа сериализации снижает риск ошибок при обновлении клиентов. Для потоковой передачи логов и событий по HTTP целесообразно рассматривать NDJSON, а для компактного обмена без жёстких схем – MessagePack. Выбор должен опираться на сценарии использования, требования к контрактам и ограничения инфраструктуры.
JSON в API: типы данных, null-значения и представление дат
JSON поддерживает ограниченный набор типов: строка, число, логическое значение, объект, массив и null. Отсутствие целых и дробных чисел как отдельных сущностей приводит к проблемам точности: значения денежных сумм и счётчиков рекомендуется передавать либо в виде строк, либо в минимальных единицах (например, копейках), чтобы исключить ошибки округления на стороне клиента.
Использование null требует чёткого соглашения. Поле со значением null означает намеренное отсутствие данных, а отсутствие поля – его неприменимость или неизвестность. Смешивание этих подходов усложняет обработку и валидацию. Для публичных API предпочтительно фиксировать поведение в контракте: либо всегда возвращать поле с null, либо полностью исключать его из ответа при отсутствии значения.
Строки в JSON не имеют встроенной типизации, поэтому даты и время требуют строгого формата. На практике применяется ISO 8601 с указанием временной зоны, например 2025-03-18T14:32:00Z. Передача дат без зоны или в локальном времени приводит к расхождениям при обработке на клиентах и серверах, особенно в распределённых системах.
Для временных интервалов и меток времени допустима передача Unix timestamp, но только при явном указании единиц измерения. Использование секунд и миллисекунд вперемешку остаётся одной из частых причин ошибок. Если формат предполагает числовое представление времени, его следует закрепить в документации и не менять между версиями API.
Объекты и массивы в JSON не гарантируют порядок ключей, поэтому бизнес-логика не должна на него опираться. Для структурированных списков важно использовать массивы, а не объекты с динамическими ключами, чтобы клиенты могли корректно валидировать и сериализовать данные при обновлениях API.
XML в API: использование XSD-схем и проверка структуры
XML остаётся востребованным в API с формализованными контрактами, где структура сообщений должна быть однозначной и проверяемой. XSD-схемы позволяют описать модель данных на уровне элементов, атрибутов и их иерархии, включая строгие ограничения на типы, обязательность и допустимые значения. Это снижает риск приёма некорректных запросов и упрощает поддержку интеграций.
При проектировании схемы важно избегать избыточной вложенности и анонимных типов. Выделение повторно используемых complexType и simpleType упрощает сопровождение и снижает вероятность расхождений между версиями. Для строковых полей рекомендуется задавать pattern и maxLength, особенно для идентификаторов, кодов и форматированных значений.
Проверка XML по XSD должна выполняться синхронно при приёме запроса, до его передачи в прикладную логику. Это позволяет сразу возвращать детализированные ошибки с указанием проблемного элемента и правила схемы. Отказ от валидации на входе приводит к накоплению проверок в коде и усложняет тестирование API.
Для работы с необязательными данными следует чётко разграничивать отсутствие элемента и пустое значение. Использование nillable=»true» оправдано только при наличии бизнес-смысла у пустого значения; в остальных случаях элемент лучше опускать. Несогласованное применение xsi:nil затрудняет обработку ответов на стороне клиента.
Версионирование XSD требует дисциплины: любые несовместимые изменения должны сопровождаться новым пространством имён. Схемы следует публиковать и фиксировать, а не изменять «на месте», чтобы клиенты могли валидировать документы заранее и не зависеть от неявных изменений структуры.
application/x-www-form-urlencoded: передача параметров в HTTP-запросах
Формат application/x-www-form-urlencoded применяется для передачи параметров в теле HTTP-запроса в виде пар ключ=значение, объединённых символом &. Он используется в OAuth 2.0, формах авторизации и простых API-методах, где структура данных плоская и не требует вложенности.
Все значения кодируются по правилам URL encoding, что накладывает ограничения на типы данных и их представление:
- строки кодируются с заменой специальных символов (+ вместо пробелов, %XX для остальных)
- числа и логические значения передаются как строки без явной типизации
- массивы и объекты не поддерживаются стандартом и требуют соглашений
Если API принимает повторяющиеся параметры, необходимо заранее зафиксировать формат:
- ids=1&ids=2&ids=3 – повторяющиеся ключи
- ids[]=1&ids[]=2 – массивы с индексами
Отсутствие чёткого правила приводит к разной интерпретации на серверах и клиентах. Для публичных API предпочтительно выбирать один вариант и отклонять остальные.
Формат не подходит для передачи бинарных данных и больших объёмов информации. Максимальный размер запроса зависит от сервера и прокси, но на практике часто ограничен диапазоном 8–32 КБ. При превышении лимитов запросы могут отклоняться без детального описания причины.
Использование application/x-www-form-urlencoded оправдано только для простых операций. При появлении вложенных структур, списков объектов или файлов следует явно переходить на multipart/form-data или форматы сериализации вроде JSON, чтобы избежать неявных соглашений и ошибок парсинга.
multipart/form-data: загрузка файлов и смешанных данных
Формат multipart/form-data используется для передачи файлов вместе с текстовыми полями в одном HTTP-запросе. Тело запроса разбивается на части с уникальным boundary, каждая из которых содержит собственные заголовки, включая Content-Disposition и при необходимости Content-Type. Это позволяет серверу различать бинарные данные и параметры без неявных соглашений.
Для файлов следует всегда передавать корректный Content-Type, а не полагаться на расширение имени. Серверная логика должна проверять MIME-тип, размер и допустимые форматы до сохранения данных. Ограничения по размеру нужно фиксировать явно и возвращать понятные коды ошибок при превышении лимитов, так как прокси и веб-серверы часто обрывают соединение без пояснений.
Текстовые поля в multipart-запросе не имеют строгой типизации и приходят как строки. Если API принимает числовые значения, даты или флаги, их формат необходимо закреплять в контракте и валидировать отдельно. Смешивание логики разбора multipart и бизнес-проверок без явных правил приводит к ошибкам при обновлении клиентов.
Имена частей должны быть стабильными и документированными. Изменение названия поля файла или параметра считается несовместимым изменением и требует версии API. Для передачи нескольких файлов рекомендуется использовать повторяющиеся части с одинаковым именем, а не индексированные поля, чтобы упростить обработку на разных платформах.
Формат подходит только для сценариев загрузки и обновления ресурсов. Использование multipart/form-data для обычных CRUD-операций без файлов усложняет отладку и кэширование. В таких случаях предпочтительнее применять JSON, оставляя multipart исключительно для операций, где без него нельзя обойтись.
Protocol Buffers: бинарные сообщения и совместимость контрактов
Protocol Buffers применяются в API, где критичны размер сообщений и строгая типизация. Данные сериализуются в бинарный формат, что снижает объём передаваемой нагрузки и ускоряет разбор по сравнению с текстовыми представлениями. Контракт описывается в .proto-файлах, на основе которых генерируется код для клиентов и серверов.
Каждому полю в сообщении присваивается числовой тег, используемый при сериализации. Эти теги являются частью контракта и не должны изменяться после публикации API. Удаление поля допустимо только с резервированием его номера, иначе старые клиенты могут некорректно интерпретировать новые сообщения.
Protocol Buffers поддерживают прямую и обратную совместимость при соблюдении правил эволюции схемы. Добавление новых необязательных полей не нарушает работу существующих клиентов, так как неизвестные поля игнорируются при десериализации. Изменение типа поля или его семантики считается несовместимым и требует новой версии API.
Типы данных в Protobuf строго определены: отдельные варианты для целых чисел, фиксированной длины и плавающей точки. Для денежных значений рекомендуется использовать int64 в минимальных единицах или собственные сообщения, чтобы избежать проблем с точностью. Строки кодируются в UTF-8, что упрощает межплатформенное взаимодействие.
Отладка бинарных сообщений сложнее, чем у JSON или XML, поэтому в API имеет смысл предусматривать дополнительные инструменты: логирование декодированных структур, тестовые эндпоинты с текстовым представлением или параллельную поддержку JSON для диагностики. Использование Protocol Buffers оправдано при большом количестве запросов и длительном жизненном цикле контрактов.
MessagePack: компактная сериализация для клиент-серверного обмена
MessagePack представляет собой бинарный формат сериализации, сохраняющий модель данных JSON, но кодирующий её в более плотном виде. Он поддерживает строки, числа, логические значения, массивы, словари и бинарные блоки без необходимости описания схемы, что упрощает внедрение в существующие API.
За счёт бинарного кодирования MessagePack снижает размер полезной нагрузки и объём передаваемого трафика. Типы данных кодируются однозначно, без строковых преобразований, что уменьшает нагрузку на парсер по сравнению с текстовыми форматами.
| Характеристика | JSON | MessagePack |
|---|---|---|
| Тип представления | Текстовый | Бинарный |
| Размер сообщений | Больше из-за строк и ключей | Меньше за счёт компактного кодирования |
| Поддержка схемы | Отсутствует | Отсутствует |
Отсутствие схемы означает, что валидация структуры и типов должна выполняться на уровне приложения. Для публичных API рекомендуется фиксировать контракт в документации и тестах, так как клиенты не могут автоматически проверить корректность сообщения до его разбора.
MessagePack удобен для мобильных клиентов, игровых серверов и внутренних сервисов, где важен баланс между компактностью и простотой. При использовании по HTTP следует явно указывать Content-Type: application/msgpack и обеспечивать корректную обработку неизвестных полей, так как формат допускает расширение структуры без явного версионирования.
NDJSON: потоковая передача наборов данных по HTTP
Формат применяется в сценариях, где объём данных заранее неизвестен или слишком велик для единого ответа. Типовые случаи использования:
- экспорт логов и событий в реальном времени
- постраничная выгрузка аналитических данных
- инкрементальная передача результатов длительных операций
При работе с NDJSON сервер должен отправлять данные по мере готовности, используя chunked transfer encoding. Клиентская сторона обязана читать поток последовательно и не пытаться десериализовать его целиком, иначе теряется смысл формата и возрастает потребление памяти.
Каждая строка должна завершаться символом \n, включая последнюю. Передача пустых строк или комментариев недопустима, так как большинство парсеров трактуют их как ошибку. Для HTTP-заголовков рекомендуется указывать Content-Type: application/x-ndjson или application/ndjson для явного обозначения формата.
NDJSON не поддерживает вложенные структуры между объектами, поэтому состояние и метаданные потока следует передавать либо в начальном объекте, либо через HTTP-заголовки. Изменение схемы объектов внутри одного потока недопустимо и должно приводить к завершению соединения или новой версии эндпоинта.
Content-Type и Accept: выбор формата ответа и согласование версий
Заголовок Content-Type определяет фактический формат тела HTTP-запроса или ответа и должен точно соответствовать сериализации данных. Неверное значение приводит к ошибкам парсинга даже при корректной структуре сообщения. Сервер обязан отклонять запросы с неподдерживаемым Content-Type, а не пытаться угадать формат по содержимому.
Accept используется клиентом для указания допустимых форматов ответа. Если API поддерживает несколько представлений одного ресурса, сервер должен выбирать формат на основе Accept, а при отсутствии подходящего варианта возвращать код 406 Not Acceptable. Игнорирование этого заголовка лишает возможности управлять форматом без изменения URL.
Для согласования версий полезно применять vendor-specific media types, например application/vnd.example.v2+json. Такой подход позволяет изменять структуру ответа без дублирования эндпоинтов и явного добавления версии в путь запроса. Версия становится частью контракта формата, а не маршрутизации.
Альтернативный вариант – передача версии через параметр media type, например application/json; version=2. Он требует строгой обработки на сервере и одинаковой реализации у всех клиентов, иначе возможны расхождения в интерпретации заголовков прокси и кэширующими слоями.
Для ответов по умолчанию следует фиксировать один формат и явно документировать его. Молчаливое переключение форматов при изменении заголовков клиента считается несовместимым изменением. Контроль Content-Type и Accept на границе API снижает количество скрытых ошибок и упрощает поддержку нескольких клиентов с разными требованиями.
Вопрос-ответ:
Почему API не всегда ограничиваются JSON и когда это создаёт проблемы?
JSON удобен для большинства клиентских приложений, но он передаёт все значения в текстовом виде и не имеет строгой схемы. Это приводит к ошибкам типизации, разночтениям в датах и росту трафика при большом числе запросов. В сервисах с высокой нагрузкой или жёсткими контрактами такие ограничения становятся источником багов и лишних проверок.
Как правильно различать отсутствие поля и значение null в ответах API?
Отсутствие поля обычно означает, что параметр неприменим или не запрошен, а null — что значение известно и пусто. Если API использует оба варианта без правил, клиенты начинают трактовать данные по-разному. Практика показывает, что лучше выбрать один подход и закрепить его в контракте, чем допускать смешение.
Зачем использовать XSD при работе с XML, если данные всё равно проверяются в коде?
XSD позволяет отсеивать некорректные запросы ещё до выполнения прикладной логики. Это снижает количество проверок в коде и упрощает диагностику ошибок, так как клиент получает описание нарушений структуры, а не общее сообщение об отказе.
Можно ли применять multipart/form-data для обычных POST-запросов без файлов?
Технически можно, но это усложняет разбор запросов, логирование и кэширование. Формат предназначен для передачи бинарных данных вместе с параметрами. Если файлов нет, использование JSON или application/x-www-form-urlencoded делает контракт понятнее и снижает риск ошибок при обновлении клиентов.
Как согласовывать формат и версию ответа API без добавления версии в URL?
Для этого применяются заголовки Accept и vendor-specific media types, где версия включается в тип данных. Клиент явно указывает, какой формат он ожидает, а сервер возвращает подходящее представление или сообщает об отсутствии поддержки. Такой подход позволяет развивать API без дублирования эндпоинтов.
Почему при использовании NDJSON нельзя просто прочитать весь ответ целиком, как обычный JSON?
NDJSON передаётся как поток отдельных JSON-объектов, разделённых переводами строки. Сервер может отправлять данные частями по мере их появления, не зная финальный размер ответа. Если клиент пытается дождаться конца потока и разобрать его целиком, теряется смысл формата и резко растёт потребление памяти при больших объёмах данных.
В каких случаях Protocol Buffers создают сложности по сравнению с текстовыми форматами?
Бинарные сообщения сложно читать без специальных инструментов, поэтому отладка и анализ логов требуют дополнительной подготовки. Любое изменение схемы требует пересборки клиентов, а нарушение правил совместимости приводит к ошибкам на стороне потребителей. Такие особенности делают формат менее удобным для публичных API и разовых интеграций.