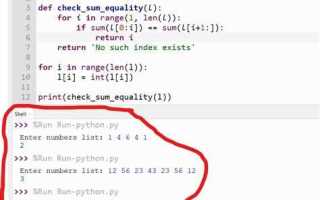
Подсчёт уникальных элементов в списке – практическая задача, с которой сталкиваются при анализе данных, обработке логов, очистке пользовательского ввода и оптимизации алгоритмов. В Python результат зависит не только от выбранного инструмента, но и от требований к типам данных, сохранению порядка и объёму входного списка. Например, для списка из миллиона элементов разница между set и collections.Counter может выражаться в сотнях миллисекунд и десятках мегабайт памяти.
Важно заранее определить, что именно считается уникальностью. В Python 1 и 1.0 считаются равными при сравнении, а True эквивалентен 1, что напрямую влияет на результат. Кроме того, неизменяемые и хешируемые типы (числа, строки, кортежи) можно обрабатывать стандартными средствами, тогда как списки и словари требуют альтернативных подходов.
На практике чаще всего используют преобразование списка в set, так как это самый короткий и быстрый способ получить количество уникальных значений. Однако он полностью игнорирует порядок элементов и не позволяет сразу узнать частоту повторений. Если требуется сохранить последовательность или подсчитать количество вхождений каждого элемента, стоит использовать Counter или ручную фильтрацию через словарь.
Выбор метода напрямую влияет на читаемость кода и его масштабируемость. Для небольших списков разница незаметна, но при обработке потоков данных или больших массивов неправильный подход может стать узким местом. Поэтому в статье рассматриваются конкретные способы подсчёта уникальных элементов с указанием ограничений, производительности и типичных ошибок.
htmlЧто считается уникальным элементом в списке Python

В Python уникальность элемента определяется результатом операций сравнения и хеширования. Для большинства стандартных типов используется логика __eq__ и __hash__: если два объекта равны при сравнении и имеют одинаковый хеш, они считаются одним уникальным значением. Это правило напрямую влияет на итог подсчёта при использовании set или ключей словаря.
Числовые типы имеют общую модель сравнения. Значения 1, 1.0 и True равны друг другу, так как bool является подклассом int. При подсчёте уникальных элементов такие значения схлопываются в один элемент, что часто становится источником логических ошибок при анализе данных.
| Элементы в списке | Считаются уникальными | Причина |
|---|---|---|
| 1 и 1.0 | Нет | Равны по значению и хешу |
| 1 и True | Нет | True эквивалентен 1 |
| «1» и 1 | Да | Разные типы и хеши |
| (1, 2) и (1, 2) | Нет | Неизменяемые и равные кортежи |
| [1, 2] и [1, 2] | Нельзя сравнить напрямую | Списки не хешируемы |
Изменяемые типы данных, такие как списки и словари, не могут быть уникальными элементами при стандартном подсчёте, так как они не поддерживают хеширование. Для таких случаев требуется преобразование в неизменяемую форму или ручная логика сравнения.
При работе с пользовательскими классами уникальность полностью зависит от реализации методов __eq__ и __hash__. Если они не согласованы, один и тот же объект может ошибочно учитываться как несколько уникальных значений. Поэтому перед подсчётом уникальных элементов важно понимать, какие типы данных находятся в списке и как именно Python определяет их равенство.
Подсчёт уникальных эементов с помощью встроенной функции set()
Функция set() создаёт множество, в котором каждый элемент присутствует только один раз. При передаче списка Python автоматически отбрасывает все дубликаты на основе хеша и операции равенства. Для подсчёта количества уникальных элементов достаточно применить len(set(список)), что выполняется за линейное время O(n) при среднем случае.
Множество работает только с хешируемыми объектами. Числа, строки, кортежи и frozenset обрабатываются без ограничений, тогда как списки и словари вызовут ошибку TypeError. Если в исходном списке присутствуют изменяемые структуры, их необходимо предварительно преобразовать в неизменяемую форму, иначе использование set() невозможно.
Следует учитывать модель сравнения Python. Значения 1, 1.0 и True будут сведены к одному элементу множества, так как они равны и имеют одинаковый хеш. При работе с данными, где тип имеет значение, рекомендуется явно приводить элементы к нужному типу перед созданием множества.
Использование set() эффективно по скорости, но требует дополнительной памяти, так как создаётся отдельная структура данных. Для списка из миллиона целых чисел объём множества может превышать размер исходного списка в 1.5–2 раза. Это важно учитывать в задачах с ограниченной памятью.
Метод не сохраняет порядок элементов. Если порядок важен, set() подходит только для быстрого подсчёта, но не для дальнейшей обработки последовательности. В таких случаях множество используют исключительно как промежуточный инструмент, не возвращая его в итоговый результат.
Использование collections.Counter для подсчёта уникальных значений
В отличие от set(), Counter сохраняет данные о каждом элементе, что удобно для аналитических задач. Например, можно мгновенно определить, какие значения встречаются один раз, а какие – тысячи раз, без дополнительной обработки. Это особенно полезно при анализе логов, текстов или пользовательского ввода.
Ограничения по типам данных такие же, как у словаря: элементы должны быть хешируемыми. Числа, строки и кортежи работают корректно, а списки и словари приведут к ошибке. Если требуется учитывать сложные структуры, их необходимо преобразовать в неизменяемый вид до передачи в Counter.
С точки зрения производительности Counter имеет временную сложность O(n), но потребляет больше памяти, чем set(), так как хранит счётчик для каждого уникального значения. Для больших наборов данных это оправдано только в случаях, когда частоты действительно используются в дальнейшей логике.
Дополнительное преимущество Counter – наличие готовых методов, таких как most_common(), позволяющих быстро извлекать наиболее частые элементы. Если задача выходит за рамки простого подсчёта уникальных значений, использование collections.Counter снижает количество кода и вероятность ошибок.
Подсчёт уникальных элементов без преобразования списка в set
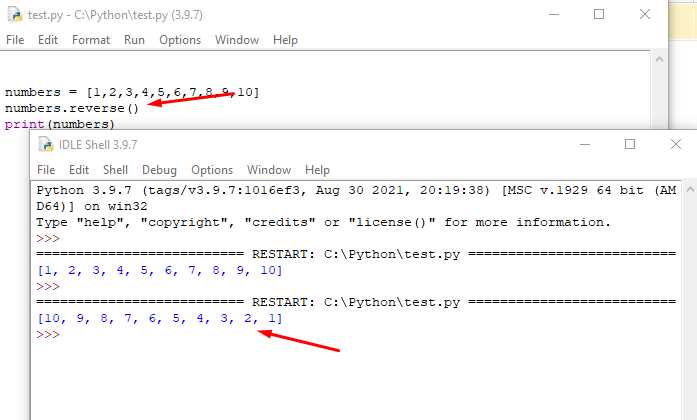
Отказ от использования set() оправдан, когда требуется сохранить порядок элементов, обработать не хешируемые типы или реализовать собственные правила сравнения. В таких случаях подсчёт уникальных значений выполняется вручную, чаще всего с помощью словаря или последовательной проверки.
Наиболее практичный вариант – пошаговый обход списка с накоплением уже встреченных элементов. Такой подход позволяет гибко управлять логикой уникальности и подходит для сложных структур данных.
- Использование словаря с элементами в роли ключей и фиктивными значениями
- Проверка наличия элемента перед добавлением нового значения
- Подсчёт количества уникальных элементов через размер словаря
Словарь сохраняет порядок добавления элементов, начиная с Python 3.7, поэтому результат будет соответствовать исходной последовательности. Временная сложность такого алгоритма составляет O(n), что сопоставимо с set(), но потребление памяти немного выше из-за хранения значений.
Если элементы списка не поддерживают хеширование, применяется последовательное сравнение с уже найденными уникальными значениями. Этот метод универсален, но имеет квадратичную сложность O(n²), поэтому подходит только для небольших списков.
- Создание пустого списка для уникальных элементов
- Последовательное сравнение каждого нового элемента с уже добавленными
- Добавление элемента только при отсутствии совпадений
Такой подход позволяет учитывать пользовательскую логику сравнения, например сравнение по части структуры или нормализованному значению. Он применяется там, где стандартные механизмы Python неприменимы или дают некорректный результат.
Как учитывать порядок элементов при подсчёте уникальных значений

При стандартном использовании set() порядок элементов теряется, так как множество не хранит информацию о последовательности добавления. Если порядок появления уникальных значений имеет значение, необходимо выбирать другие структуры данных или комбинировать инструменты.
Наиболее надёжный способ – использовать словарь, который сохраняет порядок вставки элементов. При последовательном обходе списка первый встреченный элемент фиксируется, а повторные игнорируются, что позволяет получить корректный счётчик уникальных значений без искажения последовательности.
- Инициализировать пустой словарь
- Добавлять элемент только при его отсутствии в словаре
- Использовать размер словаря как количество уникальных значений
Аналогичное поведение можно получить с помощью collections.OrderedDict, однако начиная с Python 3.7 его использование избыточно, так как обычный словарь уже гарантирует сохранение порядка. Это особенно важно учитывать при работе с современными версиями интерпретатора.
Если элементы не являются хешируемыми, порядок сохраняют с помощью вспомогательного списка, в который добавляются только новые значения после проверки на наличие. Такой подход универсален, но имеет более высокую вычислительную сложность.
- Последовательно обходить исходный список
- Сравнивать текущий элемент с ранее сохранёнными
- Фиксировать элемент при первом появлении
Для больших наборов данных приоритетом остаётся словарь, так как он сочетает сохранение порядка с линейной сложностью O(n). Ручная проверка подходит только в ситуациях, где стандартные механизмы Python неприменимы.
Сравнение способов подсчёта уникальных элементов по скорости и памяти

Преобразование списка в set() остаётся самым быстрым способом подсчёта уникальных элементов. При линейной сложности O(n) и минимальном количестве операций Python эффективно обрабатывает даже миллионы значений. Цена этой скорости – дополнительная память под структуру множества и потеря порядка элементов.
Использование collections.Counter также имеет сложность O(n), но требует больше памяти, так как для каждого уникального значения хранится счётчик. Разница становится заметной на больших объёмах данных: при одинаковом входном списке Counter может потреблять на 30–50% больше памяти, чем set(). Этот вариант оправдан только тогда, когда частоты используются в дальнейшей логике.
Подсчёт через словарь без преобразования в множество по скорости сопоставим с set(), так как операции проверки ключей выполняются за амортизированное O(1). Дополнительным преимуществом является сохранение порядка элементов, однако память расходуется немного больше из-за хранения значений словаря.
Последовательное сравнение элементов с использованием списка для хранения уникальных значений имеет квадратичную сложность O(n²). Уже при нескольких десятках тысяч элементов такой подход становится неприемлемым по времени, хотя потребление памяти минимально. Его применение оправдано только для небольших наборов данных или не хешируемых объектов.
При выборе метода ключевыми факторами остаются объём входного списка, требования к порядку и необходимость учитывать частоты. Для чистого подсчёта лучше использовать set(), для анализа распределения – Counter, для сохранения последовательности – словарь, а ручную проверку оставлять как крайний вариант.
Вопрос-ответ:
Почему len(set(список)) иногда возвращает меньше элементов, чем ожидается?
Чаще всего причина связана с моделью сравнения Python. Значения 1, 1.0 и True считаются равными, так как имеют одинаковое числовое значение и хеш. При создании множества такие элементы объединяются. Если нужно различать их, данные следует заранее приводить к одному типу или хранить вместе с типовой меткой.
Можно ли посчитать уникальные элементы, если в списке есть словари или списки?
Напрямую нельзя, потому что такие объекты не поддерживают хеширование. Один из вариантов — преобразовать вложенные структуры в кортежи или сериализовать их в строки. Альтернативный путь — сравнивать элементы вручную, последовательно проверяя совпадения, но этот способ подходит только для небольших списков.
Чем подсчёт через Counter отличается от использования set?
Counter хранит не только сами уникальные значения, но и количество их повторений. Это удобно, когда нужно узнать частоту каждого элемента. Set ограничивается удалением дубликатов. По памяти Counter расходует больше ресурсов, так как для каждого ключа хранится числовой счётчик.
Как посчитать уникальные элементы и сохранить порядок их появления?
Для этого используют словарь, добавляя элементы по мере обхода списка и пропуская повторные. В Python 3.7 и выше словарь сохраняет порядок вставки, поэтому первый встреченный элемент остаётся на своём месте. Количество уникальных значений определяется по размеру словаря.
Какой способ лучше подходит для списка из нескольких миллионов элементов?
Если требуется только количество уникальных значений, быстрее всего работает set. Он обрабатывает данные за линейное время и не выполняет лишних операций. Если нужны частоты, стоит выбрать Counter, принимая во внимание больший расход памяти. Ручное сравнение элементов для таких объёмов не подходит из-за резкого роста времени выполнения.
Почему при подсчёте уникальных элементов строки с одинаковым текстом считаются одним значением, даже если созданы в разных местах кода?
В Python строки сравниваются по содержимому, а не по месту создания объекта. Если две строки содержат одинаковую последовательность символов, операция сравнения возвращает равенство, а их хеш совпадает. При использовании set или ключей словаря такие строки объединяются в один элемент. Если требуется различать их по источнику или контексту, нужно хранить дополнительную информацию, например кортеж из строки и идентификатора.