Содержание статьи

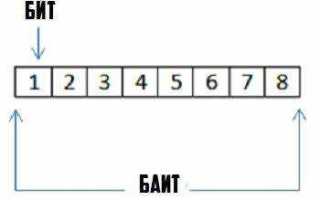
Ограничение в 255 байт встречается в полях заголовков, сетевых структурах и параметрах некоторых СУБД. Чтобы исключить искажения строк, важно учитывать, как кодировка распределяет байтовый объём между символами. В ASCII используется фиксированная длина – 1 байт на знак, поэтому доступно ровно 255 символов.
В UTF-8 ситуация меняется: латиница занимает 1 байт, кириллица – 2 байта, а некоторые юникодные группы – 3 или 4 байта. Из-за этого количество доступных символов может снижаться до 60–120, в зависимости от набора. В UTF-16 каждый знак требует минимум 2 байта, что уменьшает вместимость до примерно 120–127 символов.
При подготовке строк для API, бинарных структур или полей фиксированной длины стоит заранее просчитывать фактический байтовый объём. Это помогает формировать данные без неожиданных сокращений и исключить ошибки при сериализации.
Сколько символов поместится в 255 байт в ASCII

Стандартный ASCII использует фиксированное распределение – 1 байт на каждый знак. При лимите в 255 байт строка будет содержать ровно 255 символов без исключений. В расчёт входят буквы, цифры, знаки пунктуации и управляющие коды от 0 до 127.
Если требуется точное соблюдение байтового ограничения, ASCII остаётся самым предсказуемым вариантом. При формировании идентификаторов, ключей и технических строк можно заранее задать максимальную длину в символах, так как она полностью совпадает с байтовым объёмом. Это исключает необходимость проверки на многобайтовые последовательности.
При переходе от ASCII к расширенным наборам, таким как Windows-1251 или UTF-8, объём начинает зависеть от конкретных символов. Поэтому если важна строгая фиксация длины, применение чистого ASCII остаётся надёжным способом контролировать количество байтов.
Подсчёт количества UTF-8 символов в 255 байтах для разных групп знаков

UTF-8 распределяет байты по символам неравномерно: латиница занимает 1 байт, кириллица и большинство европейских знаков – 2 байта, ряд азиатских символов – 3 байта, отдельные эмодзи и редкие юникодные позиции – 4 байта. Поэтому фактическое количество символов в пределах 255 байт зависит от набора, который используется в строке.
Если строка состоит только из латиницы, поместится 255 символов. Для кириллицы диапазон уменьшается до 127 знаков, так как каждый занимает 2 байта. При использовании кодовых точек, требующих 3 байта, вместимость снижается до 85 символов. Эмодзи и сложные иероглифы, кодируемые в 4 байта, сокращают объём до 63 символов.
При работе с API, конфигурационными файлами и параметрами фиксированной длины полезно заранее проверить строку через подсчёт байтов, а не визуальную длину. Это позволяет корректно вписать текст в ограничение и избежать усечения при сериализации или передаче данных.
Ограничение размера строки в 255 байт и поведение кириллицы в UTF-8
В UTF-8 кириллические символы занимают 2 байта, поэтому при лимите в 255 байт максимальная длина строки составляет 127 знаков. Один оставшийся байт нередко резервируется под завершающий ноль в структурах C-типов, что снижает доступный объём до 254 байт и уменьшает вместимость до 127 символов без изменения структуры данных.
Если строка содержит смесь кириллицы, латиницы и спецсимволов, число символов сокращается нерегулярно. Латинские буквы занимают 1 байт, что позволяет частично компенсировать объём. Например, фраза, где половина знаков – кириллица, а половина – латиница, помещается примерно в 170–180 байтов, оставляя запас под дополнительные элементы строки.
Для точной проверки стоит использовать подсчёт байтов перед записью данных. Простые методы: iconv в Linux, функции byteLength в JavaScript или преобразование строки в массив байтов в Python. Такой подход помогает избежать усечения строки при работе с полями фиксированной длины и сетевыми пакетами.
Количество символов в 255 байтах при использовании UTF-16LE

UTF-16LE выделяет 2 байта на большинство символов, поэтому при лимите в 255 байт доступно только 254 байта под содержимое. Это даёт максимум 127 символов, если строка не содержит суррогатных пар. Для знаков, кодирующихся через пару 16-битных единиц, объём уменьшается вдвое.
В таблице приведены расчёты для основных групп символов с учётом фактического распределения байтов:
| Группа символов | Байт на символ | Максимум в 255 байтах |
|---|---|---|
| Базовые буквы и цифры (BMP) | 2 | 127 |
| Суррогатные пары (эмодзи, часть иероглифов) | 4 | 63 |
| Смешанная строка (80% BMP + 20% пары) | ≈2.4 | ≈105 |
При подготовке строк для бинарных структур или полей с жёстким ограничением стоит заранее проверять наличие суррогатных пар, так как они существенно сокращают доступный объём. Это помогает корректно рассчитывать длину строки и избегать обрезания при записи.
Сравнение заполнения 255 байт в UTF-16BE и UTF-32

В UTF-16BE каждый символ базовой многоязычной плоскости занимает 2 байта, а суррогатные пары – 4 байта. При лимите 255 байт доступно максимум 127 символов без суррогатных пар и около 63 при их наличии. Символы латиницы и кириллицы полностью помещаются в 2 байта, что упрощает подсчёт и прогнозирование длины строки.
UTF-32 использует фиксированные 4 байта на каждый символ. В 255 байт можно поместить только 63 знака, причём остаток в 3 байта остаётся неиспользованным. Это ограничение делает UTF-32 менее экономным при работе с короткими строками и ограниченным пространством.
Для выбора между UTF-16BE и UTF-32 при ограничении в 255 байт важно учитывать состав символов: если преобладают BMP-знаки, UTF-16BE позволяет вместить почти вдвое больше символов, а UTF-32 целесообразен только при необходимости работы с большим количеством суррогатных пар без дополнительной логики подсчёта байтов.
Подсчёт длины JSON-текста при лимите 255 байт с учётом экранирования

В JSON каждый специальный символ, такой как кавычки, обратная косая черта или управляющие коды, кодируется с помощью экранирования. Например, знак » превращается в \», что увеличивает объём строки на 1 байт при использовании UTF-8 для латиницы и на 2 байта для кириллицы. Это сокращает количество доступных символов в пределах 255 байт.
Если строка содержит смесь латиницы и кириллицы, а также специальные символы, практический объём можно рассчитать так: количество исходных байтов + суммарное количество дополнительных байтов на экранирование. Например, 120 кириллических символов (по 2 байта каждый) и 15 экранируемых знаков потребуют 240 + 15 = 255 байт, максимально используя лимит.
Для точного контроля длины JSON-строк рекомендуется применять функции подсчёта байтов после экранирования, например, JSON.stringify в JavaScript с последующим измерением byteLength строки, или encode в Python. Такой подход предотвращает усечение текста при передаче данных в API и записи в поля фиксированной длины.
Как определить точное число символов в 255 байтах через утилиты и редакторы

Для корректного расчёта количества символов в 255 байтах важно учитывать кодировку и возможное экранирование. На практике это можно сделать с помощью стандартных утилит и редакторов:
- Linux/Unix: команды wc -c и iconv позволяют подсчитать количество байтов после преобразования строки в нужную кодировку. Пример:
echo "текст" | iconv -f UTF-8 -t UTF-8 | wc -c. - Python: метод encode возвращает байтовое представление строки, например:
len("текст".encode("utf-8")). - JavaScript: функция new TextEncoder().encode(str).length позволяет получить точное число байтов в UTF-8.
- Текстовые редакторы: VS Code и Notepad++ показывают длину файла в байтах, а при выделении фрагмента можно проверить объём выбранной части.
Рекомендации по использованию:
- Сначала преобразуйте строку в нужную кодировку, учитывая UTF-8, UTF-16LE/BE или ASCII.
- Подсчитайте фактический размер в байтах, включая экранирование и специальные символы.
- Сравните результат с лимитом 255 байт и скорректируйте длину строки, если требуется.
Такой подход позволяет избежать усечения текста, сохранить корректность JSON-данных и обеспечить точное заполнение полей фиксированной длины.
Вопрос-ответ:
Сколько символов кириллицы помещается в 255 байт при кодировке UTF-8?
Кириллические символы в UTF-8 занимают по 2 байта. При лимите в 255 байт можно разместить до 127 символов. Если учитывать завершающий нулевой байт в некоторых структурах, количество символов сокращается до 127 или меньше. При смешении кириллицы и латиницы вместимость изменяется, так как латинские буквы занимают только 1 байт.
Почему в ASCII 255 байт соответствует ровно 255 символам?
ASCII использует фиксированное распределение — 1 байт на каждый символ, включая буквы, цифры и знаки пунктуации. Поэтому 255 байт соответствует 255 символам без исключений. Эта особенность делает ASCII предсказуемым для полей фиксированной длины и идентификаторов.
Как подсчитать количество символов в 255 байтах при смешанных кодировках?
Для точного подсчёта следует преобразовать строку в нужную кодировку и измерить её размер в байтах. В Linux можно использовать iconv и wc -c, в Python — len(str.encode(«utf-8»)), а в JavaScript — new TextEncoder().encode(str).length. Такой подход учитывает многобайтовые символы и экранирование.
Сколько символов помещается в 255 байт при использовании UTF-16LE и UTF-32?
UTF-16LE использует 2 байта на большинство символов BMP, что позволяет разместить до 127 знаков в 255 байтах. Суррогатные пары для редких символов занимают 4 байта, уменьшая вместимость до 63 символов. UTF-32 фиксирует 4 байта на каждый символ, поэтому в 255 байт помещается только 63 знака, остаток в 3 байта остаётся неиспользованным.
Как экранирование символов влияет на вместимость JSON-строки в 255 байт?
Каждый экранируемый символ в JSON, например кавычки или обратная косая черта, увеличивает объём строки на 1–2 байта в UTF-8. Поэтому строка с экранированными символами в 255 байт вмещает меньше символов, чем чистый текст. Для точного расчёта используют функции подсчёта байтов после экранирования, например JSON.stringify в JavaScript или encode в Python.