Содержание статьи

Регулярные выражения в JavaScript позволяют находить, проверять и модифицировать текстовые данные без написания громоздких циклов и условий. Они применяются не только для поиска простых совпадений, но и для проверки форматов email, номеров телефонов, дат и сложных шаблонов URL.
JavaScript поддерживает два способа создания регулярных выражений: через литералы /шаблон/флаги и конструктор RegExp(«шаблон», «флаги»). Литеральный синтаксис удобен для фиксированных строк, а конструктор позволяет динамически формировать шаблоны на основе переменных. Выбор способа влияет на производительность и читаемость кода.
Флаги регулярных выражений управляют их поведением: g ищет все совпадения, i игнорирует регистр, m учитывает многострочные строки. Правильное применение флагов позволяет сократить количество вызовов методов и ускоряет обработку больших массивов данных.
Для работы с совпадениями в JavaScript используют методы test() и exec() для проверки и извлечения данных, а также match(), matchAll(), replace() и split() для трансформации строк. Выбор метода зависит от того, нужно ли получить все совпадения, заменить их или разделить текст по шаблону.
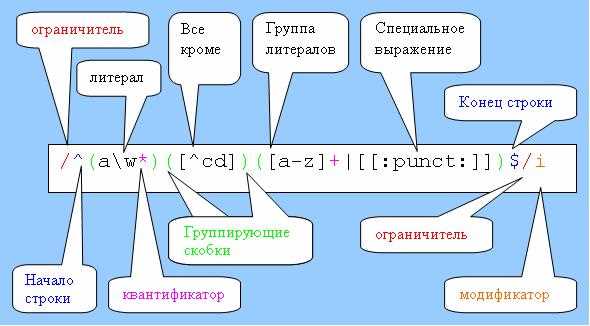
При работе с регулярными выражениями важно экранировать специальные символы: ., *, +, ?, ^, $, [, ], (, ), {, }, |, \. Неправильное экранирование приводит к неожиданным совпадениям или ошибкам синтаксиса, особенно при динамическом формировании шаблонов из пользовательского ввода.
Создание регулярных выражений через литералы и конструктор RegExp

Регулярные выражения в JavaScript можно создавать через литералы /шаблон/флаги или конструктор RegExp(«шаблон», «флаги»). Литеральный синтаксис оптимален для статических строк и компилируется один раз при загрузке скрипта, что снижает нагрузку на интерпретатор при повторных вызовах.
Конструктор RegExp необходим для динамических шаблонов. Например, при формировании регулярного выражения на основе переменной: new RegExp(userInput, «gi»). В этом случае важно экранировать специальные символы, чтобы предотвратить ошибки и некорректные совпадения.
При выборе между литералом и конструктором учитывают контекст использования: для повторяющихся и неизменных проверок предпочтительнее литералы, а для пользовательского ввода или составных шаблонов – конструктор. Это повышает производительность и снижает вероятность ошибок при динамическом создании регулярного выражения.
Регулярные выражения, созданные через литералы, поддерживают все стандартные флаги: g для глобального поиска, i для игнорирования регистра и m для многострочного анализа. Конструктор также принимает эти флаги, но их нужно передавать как строку, что важно при программной генерации шаблонов.
При использовании конструктора следует учитывать особенности экранирования: обратная косая черта \ в строках должна дублироваться, например new RegExp(«\\d+», «g»), иначе шаблон будет интерпретирован неверно. Это отличие критично при обработке числовых шаблонов, email или сложных форматов данных.
Использование флагов для поиска и модификации текста

Флаги регулярных выражений управляют способом поиска и обработки совпадений. g позволяет найти все совпадения в строке, а не только первое. Это важно при подсчете повторений или при массовой замене текста через replace().
i игнорирует регистр символов. Например, шаблон /example/i совпадет с «Example», «EXAMPLE» и «eXaMpLe». Такой флаг сокращает необходимость дублировать шаблоны для разных регистров.
m учитывает многострочные строки, превращая ^ и $ в маркеры начала и конца каждой строки, а не всей строки целиком. Этот флаг эффективен при проверке логов или текстов с переносами строк.
Флаг u активирует поддержку Unicode, позволяя корректно обрабатывать символы за пределами базовой латиницы, например эмодзи или символы других алфавитов. Без него сложные символы могут разрываться на отдельные байты при проверке совпадений.
Флаг s позволяет точке . совпадать с символом новой строки. Это критично при работе с многострочными текстами, где шаблоны должны охватывать блоки текста целиком.
Комбинируя флаги, можно создавать гибкие регулярные выражения, например /^user\d+$/gim, которые ищут все строки, начинающиеся с «user», игнорируют регистр и учитывают многострочный текст. Правильное сочетание флагов сокращает сложность кода и повышает точность поиска.
Методы test() и exec(): проверка и извлечение совпадений

Метод test() проверяет, соответствует ли строка регулярному выражению, и возвращает true или false. Он подходит для быстрого фильтра входных данных, например проверки формата email или наличия цифр в пароле.
Метод exec() извлекает первое совпадение и возвращает массив с информацией о совпадении, включая позиции и группы захвата. Если совпадений нет, возвращается null. Это удобно для детального анализа текста и извлечения конкретных данных.
Рекомендации по использованию:
- Для проверки соответствия используйте test(), когда не требуется информация о позиции совпадения.
- Для извлечения данных и групп захвата применяйте exec().
- При глобальном поиске exec() можно вызывать в цикле, используя свойство lastIndex регулярного выражения, чтобы получать все совпадения.
- Не используйте test() для подсчета совпадений в строке с флагом g, так как метод изменяет lastIndex и может давать непредсказуемые результаты.
- Для сложных шаблонов с группами захвата exec() обеспечивает точное извлечение всех подшаблонов без дополнительной обработки строки.
Пример цикла для всех совпадений через exec():
- Создайте регулярное выражение с флагом g.
- Вызовите exec() в цикле, пока не вернется null.
- Используйте массив с совпадением и свойство index для работы с позициями в строке.
Такой подход позволяет контролировать процесс поиска и извлекать данные без использования дополнительных методов или регулярных повторов проверок.
Замена текста с помощью replace() и групп захвата
Метод replace() позволяет изменять части строки, соответствующие регулярному выражению. Он поддерживает как простую замену текста, так и динамическую подстановку через функции обратного вызова.
Группы захвата, обозначаемые скобками (…), позволяют выделять части совпадений и использовать их в замене через ссылки $1, $2 и т.д. Это удобно для перестановки слов, форматирования дат или исправления структурированных данных.
Рекомендации по использованию:
- Используйте флаг g, если нужно заменить все совпадения, а не только первое.
- Для динамической замены передавайте функции в replace(). Функция получает совпадение, группы захвата и индекс, что позволяет строить результат на основе исходного текста.
- При работе с датами или числовыми форматами группы захвата упрощают перестановку элементов, например: «2026-02-03».replace(/(\d{4})-(\d{2})-(\d{2})/, «$3.$2.$1»).
- Старайтесь давать группам осмысленные позиции, чтобы ссылки $1, $2 были читаемыми и легко отслеживались при изменении шаблона.
- При сложных шаблонах с несколькими альтернативами используйте именованные группы (?<имя>…) для повышения читаемости и точности замены через $имя.
Правильное использование replace() с группами захвата позволяет полностью контролировать трансформацию текста и избегать ошибок при массовой обработке строк или данных из внешних источников.
Разделение строк через split() с шаблонами RegExp

Метод split() позволяет разбивать строку на массив по заданному разделителю. Использование регулярных выражений вместо простых строк дает возможность учитывать сложные или переменные шаблоны, такие как пробелы, запятые с пробелами, точки с запятой или комбинации символов.
Примеры практических шаблонов:
- /\s*,\s*/ – разделяет строку по запятым с учетом пробелов вокруг.
- /\r?\n/ – разделение текста на строки независимо от формата переноса строки (Windows или Unix).
- /[-;|]/ – позволяет использовать несколько символов-разделителей одновременно.
Рекомендации по применению:
- Используйте флаг g не требуется, так как split() автоматически обрабатывает все совпадения регулярного выражения.
- Если нужно сохранить разделители в результате, оборачивайте их в захватывающие скобки (…). Они попадут в массив как отдельные элементы.
- Для обработки больших текстов проверяйте шаблон на совпадения перед вызовом split(), чтобы избежать пустых элементов или лишних разрывов массива.
- При работе с динамическими разделителями используйте конструктор RegExp, чтобы подставлять шаблоны из переменных.
Разделение строк с помощью регулярных выражений упрощает обработку CSV, логов, пользовательского ввода и других текстовых данных, где разделители могут быть нестандартными или изменяться динамически.
Поиск всех совпадений через match() и matchAll()

Методы match() и matchAll() позволяют находить все совпадения регулярного выражения в строке, но используются в разных сценариях.
Метод match() возвращает массив совпадений, если используется флаг g, или массив с информацией о первом совпадении и группах захвата, если флаг не указан. Этот метод удобен для быстрых проверок и подсчета количества совпадений.
Метод matchAll() возвращает итератор всех совпадений с подробной информацией о каждой группе захвата, индексе и исходной строке. Он эффективен для построчного анализа текста или работы с динамическими шаблонами, где важно получать полный контекст совпадений.
Рекомендации по использованию:
- Для подсчета количества совпадений используйте match() с флагом g.
- Для извлечения данных из нескольких групп захвата применяйте matchAll(), особенно если требуется работать с каждой группой отдельно.
- Итератор matchAll() позволяет использовать цикл for…of без создания большого массива, что экономит память при работе с большими текстами.
- При использовании matchAll() всегда указывайте флаг g, иначе метод выбросит исключение.
- Для динамических регулярных выражений с переменными используйте конструктор RegExp совместно с matchAll(), чтобы корректно обрабатывать пользовательский ввод.
Выбор между match() и matchAll() зависит от цели: быстрый подсчет и простые совпадения – match(), детальный разбор с группами захвата – matchAll().
Экранирование специальных символов и предотвращение ошибок

Регулярные выражения используют специальные символы, такие как ., *, +, ?, ^, $, [, ], (, ), {, }, |, \, которые имеют особое значение в шаблоне. Неправильное использование этих символов приводит к некорректным совпадениям или синтаксическим ошибкам.
Для безопасного поиска буквальных символов их нужно экранировать обратной косой чертой \. Например, чтобы найти точку в тексте, шаблон должен выглядеть как /\./, иначе . совпадет с любым символом.
Таблица экранирования основных символов:
| Символ | Назначение | Экранирование |
|---|---|---|
| . | Любой символ | \. |
| * | 0 и более повторений предыдущего символа | \* |
| + | 1 и более повторений предыдущего символа | \+ |
| ? | 0 или 1 повторение | \? |
| ^ | Начало строки | \^ |
| $ | Конец строки | \$ |
| [ ] | Символьный класс | \[ \] |
| ( ) | Группировка | \( \) |
| { } | Квантификатор | \{ \} |
| | | Логическое «или» | \| |
| \ | Экранирование | \\ |
При динамическом создании регулярного выражения из переменных используйте функцию для экранирования всех специальных символов, чтобы избежать ошибок и некорректных совпадений.
Правильное экранирование особенно важно для пользовательского ввода, путей файлов, URL и любых данных, содержащих символы с особым значением в регулярных выражениях. Это снижает вероятность синтаксических ошибок и непредсказуемого поведения методов поиска или замены.
Вопрос-ответ:
Чем отличается создание регулярного выражения через литерал и через конструктор RegExp?
Литерал регулярного выражения оформляется как /шаблон/флаги и компилируется один раз при загрузке скрипта, что ускоряет многократные проверки. Конструктор RegExp используется для динамических шаблонов, например, при создании регулярного выражения из переменной. При этом специальные символы внутри строки нужно экранировать двойной обратной косой чертой, иначе шаблон будет некорректным.
Как правильно использовать флаг g при поиске совпадений?
Флаг g активирует глобальный поиск, позволяя методам вроде replace() или match() обрабатывать все совпадения в строке, а не только первое. При работе с exec() флаг g позволяет циклически извлекать все совпадения, используя свойство lastIndex регулярного выражения. Без флага g методы, возвращающие массив, ограничиваются первым совпадением.
В чем разница между методами test() и exec()?
Метод test() возвращает true или false, проверяя наличие хотя бы одного совпадения в строке. Он подходит для быстрых проверок, например, соответствует ли введенный email шаблону. Exec() возвращает массив с подробной информацией о совпадении, включая группы захвата и индекс. Это позволяет извлекать части текста или работать с позициями совпадений в строке.
Как использовать группы захвата для перестановки элементов строки?
Группы захвата обозначаются скобками (), и к ним можно обращаться через $1, $2 и так далее в методе replace(). Например, дата «2026-02-03» может быть преобразована в «03.02.2026» с помощью шаблона /(\d{4})-(\d{2})-(\d{2})/ и замены «$3.$2.$1». Для сложных шаблонов лучше использовать именованные группы, что повышает читаемость и снижает вероятность ошибки при редактировании шаблона.
Какие ошибки возникают при отсутствии экранирования специальных символов и как их избежать?
Если не экранировать символы . * + ? ^ $ [ ] ( ) { } | , регулярное выражение будет искать совпадения неправильно или вызовет синтаксическую ошибку. Чтобы избежать этого, каждое использование этих символов как буквального знака должно сопровождаться обратной косой чертой, например, точка ищется как .. При динамическом создании шаблонов из пользовательских данных рекомендуется автоматическое экранирование всех специальных символов перед формированием RegExp.