Содержание статьи

GPFS (General Parallel File System) – распределённая файловая система, разработанная IBM для работы с большими объёмами данных и параллельных нагрузок. Сегодня она известна под названием IBM Spectrum Scale, но в технической среде по-прежнему используется исходное обозначение. GPFS позволяет нескольким серверам одновременно обращаться к одному файловому пространству, сохраняя согласованность данных на уровне блоков и метаданных.
Ключевая особенность GPFS – разделение ролей между узлами кластера: одни серверы обрабатывают клиентские запросы, другие управляют метаданными и размещением данных на дисках. Такая модель применяется в системах, где объём хранилища измеряется сотнями терабайт или петабайтами, а число одновременных операций чтения и записи достигает десятков тысяч. GPFS поддерживает POSIX-совместимый доступ, снапшоты, репликацию и политики размещения данных.
На практике GPFS используют в высокопроизводительных вычислениях (HPC), аналитических платформах, системах машинного обучения и в корпоративных центрах обработки данных. Например, в вычислительных кластерах она обеспечивает общий доступ к наборам данных для расчётных задач, а в бизнес-среде – единое файловое пространство для виртуализации, резервного копирования и архивов. При выборе GPFS важно учитывать требования к сети (InfiniBand или 10/25/40+ GbE), отказоустойчивости и лицензированию.
GPFS целесообразно внедрять, когда стандартные сетевые файловые системы перестают справляться с ростом нагрузки или объёма данных. Перед развёртыванием рекомендуется спроектировать кластер с учётом ролей узлов, заранее определить политики хранения и протестировать сценарии отказов. Такой подход позволяет избежать проблем с масштабированием и управлением хранилищем на поздних этапах эксплуатации.
GPFS: что это такое и где применяется
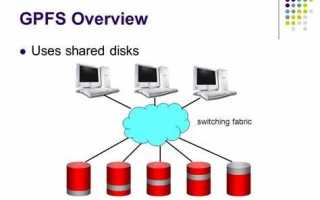
GPFS (General Parallel File System) – кластерная файловая система, ориентированная на одновременную работу большого числа узлов с единым файловым пространством. Она предназначена для сценариев, где требуется параллельный доступ к данным, высокая пропускная способность и контроль над размещением файлов на уровне блоков. GPFS работает поверх локальных дисков, SAN-хранилищ и сетевых массивов, объединяя их в логическое пространство.
В основе GPFS лежит модель разделения данных и метаданных. Метаданные управляются выделенными узлами, что снижает конкуренцию при обращении к каталогам и файлам. Клиентские узлы получают прямой доступ к данным, минуя промежуточные серверы, что особенно важно при работе с крупными файлами и потоковыми нагрузками.
GPFS применяется в средах, где стандартные сетевые файловые системы не справляются с объёмом операций и масштабом хранения:
- вычислительные кластеры для научных и инженерных расчётов;
- платформы обработки больших данных и аналитики;
- инфраструктуры машинного обучения с общими датасетами;
- корпоративные хранилища для виртуализации и контейнеров;
- архивные системы с политиками миграции данных.
GPFS оправдана в проектах, где требуется единое файловое пространство для десятков и сотен серверов, строгая согласованность данных и гибкое управление жизненным циклом файлов. В небольших инфраструктурах её использование избыточно, но при росте объёма данных и параллельных задач она становится базовым компонентом хранения.
Архитектура GPFS: как устроено распределённое хранилище данных
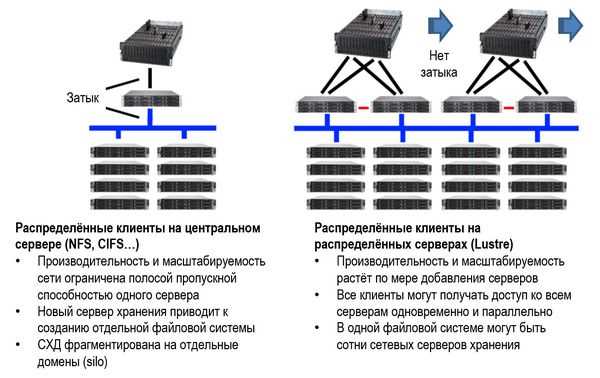
Ключевым элементом являются узлы управления метаданными. Они отвечают за каталоги, атрибуты файлов, блокировки и распределение пространства. Для повышения устойчивости метаданные реплицируются между несколькими узлами, что позволяет продолжать работу при отказе одного из них. На практике рекомендуется выделять отдельные серверы под метаданные и оснащать их быстрыми накопителями и низколатентной сетью.
Физическое хранение данных организуется через набор storage pools, объединяющих диски с разными характеристиками. Это даёт возможность размещать активные данные на SSD или NVMe, а редко используемые – на HDD или ленточных библиотеках. GPFS поддерживает политики автоматического перемещения файлов между пулами на основе размера, времени доступа и других атрибутов.
Для координации доступа используется распределённый механизм блокировок, работающий на уровне файлов и диапазонов блоков. Он минимизирует конфликты при параллельных операциях и позволяет масштабировать кластер до сотен узлов. При проектировании архитектуры важно заранее определить количество узлов, роли серверов и схему резервирования, чтобы избежать перегрузки управляющих компонентов при росте нагрузки.
Механизм параллельного доступа к файлам в GPFS

Параллельный доступ в GPFS реализован за счёт прямого обращения клиентских узлов к блокам данных без проксирования через центральный сервер. Каждый узел кластера монтирует файловую систему локально и выполняет операции чтения и записи напрямую с устройств хранения, что позволяет задействовать суммарную пропускную способность всех дисков и сетевых каналов.
Согласование операций обеспечивается распределённой системой блокировок. GPFS использует блокировки на уровне файлов и диапазонов блоков, что даёт возможность нескольким приложениям работать с разными участками одного файла одновременно. При этом метаданные и состояние блокировок координируются выделенными узлами, что снижает количество конфликтов при интенсивных параллельных операциях.
Для работы с крупными файлами GPFS применяет механизм striping – разбиение данных на фрагменты, распределённые по нескольким дискам и узлам хранения. Это особенно востребовано в расчётных задачах и аналитике, где один файл может считываться десятками процессов. Размер полос и схема распределения настраиваются на этапе проектирования хранилища под конкретные нагрузки.
В сценариях с большим числом мелких операций рекомендуется оптимизировать работу с метаданными: выделять отдельные узлы под их обслуживание и использовать быстрые накопители. Для приложений с предсказуемыми шаблонами доступа целесообразно применять предварительное чтение и кэширование на стороне клиентов, снижая нагрузку на сеть и управляющие компоненты.
При внедрении GPFS важно тестировать параллельный доступ под реальными рабочими нагрузками. Это позволяет подобрать параметры блокировок, размеры полос и сетевую конфигурацию, обеспечивая стабильную работу кластера при росте числа одновременных пользователей и процессов.
Требования к аппаратной инфраструктуре для развёртывания GPFS

Аппаратная платформа для GPFS проектируется с учётом кластерной модели и параллельных нагрузок. Минимальная конфигурация предполагает наличие нескольких серверов, объединённых в кластер, где каждый узел выполняет роль клиента, сервера хранения или управляющего компонента. Для стабильной работы важно, чтобы все узлы использовали совместимые версии процессоров, сетевых адаптеров и контроллеров хранения.
Серверы метаданных предъявляют повышенные требования к производительности. Рекомендуется использовать многоядерные процессоры, не менее 64 ГБ оперативной памяти и быстрые накопители на базе SSD или NVMe. Это снижает задержки при работе с каталогами и блокировками. Для отказоустойчивости такие узлы разворачиваются в количестве не менее двух с репликацией метаданных.
Подсистема хранения должна поддерживать параллельный доступ и масштабирование. GPFS работает как с локальными дисками, так и с SAN-массивами. Для активных данных целесообразно формировать отдельные пулы на SSD, а для массивов большого объёма – использовать HDD с увеличенным числом шпинделей. Контроллеры хранения должны обеспечивать одновременную работу с несколькими путями доступа.
При планировании инфраструктуры следует учитывать будущий рост. Запас по вычислительным ресурсам, портам коммутаторов и слотам хранения позволяет добавлять узлы без перестройки архитектуры. Такой подход упрощает сопровождение GPFS и снижает риски при расширении кластера.
Сценарии использования GPFS в высокопроизводительных вычислениях
В средах высокопроизводительных вычислений GPFS используется как общее файловое пространство для вычислительных узлов, выполняющих параллельные задачи. Файловая система обеспечивает одновременный доступ тысяч процессов к входным данным и результатам расчётов без необходимости копирования файлов между серверами, что упрощает организацию вычислительных пайплайнов.
Наиболее распространённый сценарий – запуск MPI-приложений, где каждый процесс читает и записывает собственные фрагменты данных. GPFS поддерживает параллельную запись в один файл за счёт блокировок диапазонов, что востребовано в моделировании, численных расчётах и обработке сигналов. Для таких задач рекомендуется настраивать striping с учётом размера блоков, используемых приложением.
| Сценарий | Назначение GPFS |
|---|---|
| Численное моделирование | Хранение входных сеток и результатов расчётов для тысяч потоков |
| Анализ научных данных | Параллельное чтение крупных файлов измерений и симуляций |
| Машинное обучение | Общий доступ к датасетам для обучения моделей на кластере GPU |
В вычислительных центрах GPFS часто применяется как единое хранилище для временных и постоянных данных. Быстрые пулы на SSD используются для scratch-пространства, а медленные – для долговременного хранения результатов. Политики перемещения файлов позволяют автоматически освобождать быстрые ресурсы после завершения расчётов.
Применение GPFS в корпоративных центрах обработки данных
В корпоративных ЦОД GPFS используется как основа для построения масштабируемого файлового хранилища с единым пространством имён. Это позволяет объединять разнородные серверы и массивы хранения в одну логическую систему, доступную для бизнес-приложений, аналитических платформ и сервисов виртуализации. Такой подход упрощает управление данными и снижает количество изолированных хранилищ.
Частый сценарий – размещение GPFS под инфраструктуру виртуальных машин и контейнеров. Файловая система обеспечивает одновременный доступ гипервизоров к образам виртуальных дисков и шаблонам, сохраняя согласованность данных при миграции нагрузок между серверами. Для таких задач рекомендуется использовать отдельные пулы хранения на SSD и выделенные узлы для обслуживания метаданных.
GPFS применяется и в системах резервного копирования и корпоративных архивах. За счёт поддержки снапшотов и политик управления жизненным циклом файлов можно организовать хранение активных данных, их копий и архивов в рамках одной платформы. Это упрощает восстановление информации и снижает нагрузку на внешние системы бэкапа.
Для аналитических и отчётных систем GPFS выступает центральным репозиторием, где данные доступны одновременно BI-инструментам, ETL-процессам и приложениям. При проектировании такого хранилища важно учитывать профиль доступа и изолировать аналитические нагрузки от транзакционных, распределяя их по разным пулам и сетевым сегментам.
В корпоративной среде GPFS оправдана при росте объёма данных и числе потребителей. Рекомендуется закладывать резерв по вычислительным ресурсам и сети, а также заранее определить политики размещения и удаления данных. Это упрощает эксплуатацию и позволяет адаптировать ЦОД к новым нагрузкам без перестройки архитектуры.
Интеграция GPFS с системами резервного копирования и архивирования
GPFS предоставляет встроенные механизмы, упрощающие взаимодействие с системами резервного копирования и долговременного хранения. За счёт снапшотов файловой системы можно фиксировать состояние данных без остановки приложений, что важно для кластеров с круглосуточной нагрузкой. Снапшоты используются как источник для последующего копирования, снижая риск несогласованных резервных копий.
Для архивирования GPFS поддерживает политики управления жизненным циклом файлов. Они позволяют автоматически переносить данные между пулами хранения в зависимости от времени доступа, размера и других атрибутов. Это даёт возможность организовать многоуровневое хранение, где активные данные остаются на быстрых носителях, а редко используемые – перемещаются в архив.
- настройка регулярных снапшотов для каталогов с критичными данными;
- использование выделенных узлов для операций резервного копирования;
- разделение пулов хранения под рабочие данные и архивы;
- ограничение нагрузки бэкапа на основную сеть кластера.
GPFS может интегрироваться с корпоративными системами резервного копирования через стандартные интерфейсы файлового доступа. При больших объёмах данных рекомендуется выполнять копирование параллельно с нескольких узлов, распределяя нагрузку по кластеру. Такой подход сокращает окна резервного копирования и упрощает масштабирование.
При проектировании архивной схемы важно заранее определить сроки хранения и правила удаления файлов. Использование политик GPFS позволяет автоматизировать эти процессы и избежать накопления устаревших данных, сохраняя контроль над объёмом хранилища и затратами на инфраструктуру.
Администрирование GPFS: типовые задачи и инструменты управления
Администрирование GPFS сосредоточено на поддержании стабильной работы кластера и контроле над распределённым хранилищем. Основные операции выполняются через командную строку, где администратор управляет узлами, пулами хранения и файловыми системами. Практика показывает, что централизованный доступ к управляющим утилитам упрощает сопровождение кластеров с десятками серверов.
Важной частью администрирования является настройка политик хранения. GPFS позволяет описывать правила размещения и миграции файлов с помощью встроенного языка политик. С его помощью можно автоматически перемещать данные между пулами, освобождать пространство и поддерживать заданную структуру хранения без ручного вмешательства.
Для мониторинга используются встроенные средства сбора статистики и журналирования. Они позволяют отслеживать загрузку узлов, объёмы операций чтения и записи, состояние сетевых каналов. В крупных инсталляциях рекомендуется интегрировать GPFS с внешними системами мониторинга, чтобы получать уведомления о сбоях и деградации производительности.
При эксплуатации GPFS важно документировать изменения и регулярно тестировать сценарии отказов. Плановое обслуживание, обновление версий и проверка резервных копий снижают вероятность простоев. Такой подход делает управление распределённым хранилищем предсказуемым и контролируемым.
Вопрос-ответ:
Чем GPFS отличается от обычных сетевых файловых систем вроде NFS или SMB?
GPFS работает как кластерная файловая система, где все узлы имеют равноправный доступ к данным и метаданным. В отличие от NFS или SMB, здесь нет одного сервера, через который проходит весь ввод-вывод. Узлы обращаются к данным напрямую, а согласование выполняется распределённо, что позволяет обслуживать параллельные нагрузки с тысячами операций чтения и записи.
Подходит ли GPFS для хранения виртуальных машин и контейнеров?
GPFS применяется в инфраструктурах виртуализации, где несколько гипервизоров используют общее файловое пространство. Она поддерживает одновременный доступ к образам дисков и корректную работу при миграции виртуальных машин. Для таких сценариев обычно выделяют быстрые пулы хранения и отдельные узлы под метаданные.
Как GPFS ведёт себя при отказе одного из серверов кластера?
При отказе узла GPFS продолжает работу за счёт репликации метаданных и распределённого управления блокировками. Данные остаются доступными с других серверов, если они физически сохранены на доступных устройствах хранения. Для этого кластер проектируют с избыточными сетями и несколькими узлами управления.
Можно ли использовать GPFS для архивного хранения больших объёмов данных?
GPFS поддерживает многоуровневое хранение и политики перемещения файлов. Это позволяет держать редко используемые данные на медленных носителях или внешних архивах, а активные — на быстрых дисках. Такой подход применяется в научных и корпоративных хранилищах с длительными сроками хранения.
Насколько сложна эксплуатация GPFS по сравнению с локальными файловыми системами?
GPFS требует отдельного администрирования и понимания кластерной архитектуры. Администратор управляет узлами, пулами хранения, снапшотами и политиками через специализированные утилиты. При этом в крупных средах она снижает ручную работу за счёт централизованного управления данными.