Содержание статьи

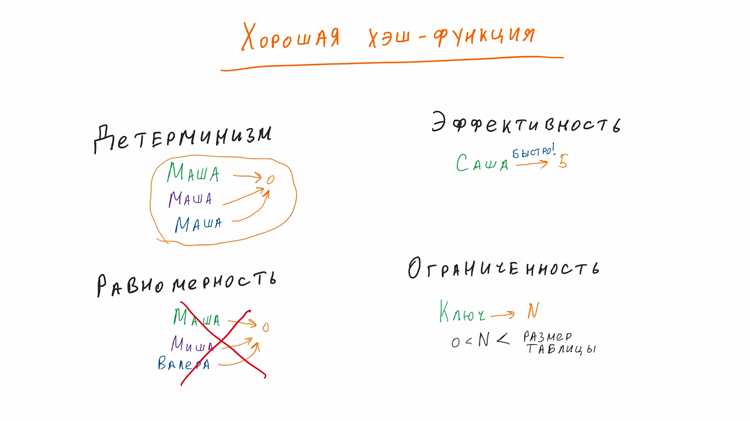
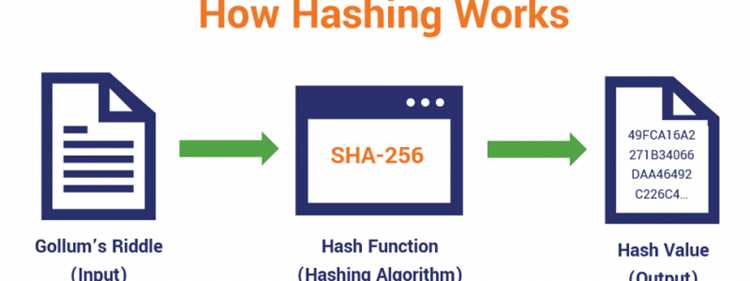
Хэш вычисляется из произвольного набора данных и превращает входную информацию в строку фиксированной длины. На практике это применяют для контроля целостности файлов, проверки совпадения паролей, сокращения данных для быстрого сравнения и сохранения ключей. Чтобы результат был предсказуемым и устойчивым, важно использовать алгоритмы с надёжной криптографической реализацией.
В прикладных задачах чаще всего применяются алгоритмы SHA-256, SHA-512, MD5, CRC32. MD5 и SHA-1 подходят для простого контроля целостности и проверки совпадения данных, но не удовлетворяют требованиям криптографической стойкости. Поэтому при работе с конфиденциальными данными используют SHA-256 и выше.
Перед вычислением хэша данные должны быть подготовлены: преобразованы в однородную кодировку, исключены лишние символы и пробелы, особенно если сравнение хэшей происходит на разных устройствах или программных платформах. Это снижает вероятность несовпадений при одинаковом содержимом и разной форме представления.
Для расчёта хэша можно применять стандартные утилиты командной строки, встроенные библиотеки популярных языков, а также специализированные программы, рекомендованные для крупных файлов и автоматизации. Конкретный инструмент выбирают исходя из задачи, объёма данных и требований к криптографической стойкости результата.
Выбор подходящего алгоритма хэширования для задачи
Алгоритм выбирают исходя из назначения: контроль целостности файлов, хранение паролей, проверка данных в сетевых системах, работа в ограниченных по ресурсу устройствах. Разные методы дают различную стойкость к подбору, коллизиям и времени вычисления.
Для проверки совпадения файлов используются MD5, SHA-1, SHA-256. С точки зрения криптографической устойчивости MD5 и SHA-1 уязвимы и подходят только для локального сравнения данных, где не предполагается внешняя атака. SHA-256 и выше применяют для защиты конфиденциальных данных и работы в системах аутентификации.
Если задача включает хранение паролей, требуется применение специализированных методов с замедлением вычислений: PBKDF2, bcrypt, Argon2. Они усложняют массовый перебор значений при атаке и уменьшают вероятность успешного подбора.
Ниже представлена таблица для быстрого выбора алгоритма в зависимости от назначения:
| Задача | Рекомендуемый алгоритм |
|---|---|
| Контроль целостности локальных файлов | MD5, SHA-1 |
| Защита данных и проверка в сетевых системах | SHA-256, SHA-512 |
| Хранение паролей | PBKDF2, bcrypt, Argon2 |
| Ограниченные вычислительные ресурсы | SHA-1, SHA-256 |
Подготовка данных к вычислению хэша и нормализация ввода
Перед вычислением хэша важно привести данные к единому виду. Различия в кодировке, дополнительных пробелах или переносах строк приводят к разным значениям, даже если смысловая часть совпадает. Для текстовых данных рекомендуется использовать UTF-8, так как эта кодировка поддерживается большинством библиотек и утилит.
При обработке строк следует удалить лишние пробелы в начале и конце, скрытые символы, различающиеся в разных операционных системах переносы строк (\n, \r\n). Такой подход полезен при сравнении данных, полученных из разных источников, где форматирование может отличаться.
Файлы перед хешированием необходимо убедиться, что их содержимое неизменено. Нельзя использовать редактирование через программы, которые могут менять метаданные. В случае двоичных данных проверяется контрольное совпадение размера и точное побитовое соответствие содержимого.
Если хеш используется в автоматизированных процессах, формат нормализации необходимо описывать в документации: выбранная кодировка, правила обработки пробелов, допустимые переносы строк, наличие или отсутствие завершающего символа. Это помогает исключить разные трактовки исходных данных между программами.
Вычисление хэша в командной строке с использованием стандартных утилит
Если требуется получить хэш строки, а не файла, на большинстве систем можно использовать передачу данных через стандартный поток. Пример для Linux: echo -n «text» | sha256sum. Флаг -n исключает перевод строки, который изменит результат.
Для автоматизации можно создавать контрольные списки. Например, команда sha256sum *.bin > checksums.txt сохраняет контрольные значения всех файлов в каталоге, что применяется для регулярной проверки содержимого в рабочих хранилищах.
Создание хэша в Python с использованием hashlib
В стандартной библиотеке Python модуль hashlib обеспечивает доступ к алгоритмам SHA-256, SHA-512, MD5 и другим. Работа строится на создании объекта алгоритма, подаче данных и получении результата в виде шестнадцатеричной строки.
Пример хэширования строки:
- Импортировать модуль: import hashlib
- Создать объект: h = hashlib.sha256()
- Передать данные: h.update(b»input»)
- Получить строку результата: h.hexdigest()
Для больших файлов используется построчное чтение без загрузки всего содержимого в память:
- Открыть файл в двоичном режиме.
- Считать фрагмент фиксированного размера.
- Передавать его в update() до достижения конца файла.
- Сформировать результат через hexdigest().
Для получения хэша в различных форматах можно использовать методы digest() и hexdigest(). Первый возвращает двоичные данные, второй – удобную для хранения и сравнения текстовую форму.
Если требуется использовать определённый алгоритм по имени, применяется функция hashlib.new(), например: hashlib.new(«sha512»). Это помогает в ситуациях, когда алгоритм задаётся настройками или параметрами конфигурации.
Генерация хэша файлов большого размера и контроль целостности
При обработке крупных файлов нельзя загружать содержимое целиком в память. Оптимальный способ – читать данные по блокам фиксированного размера, обновляя объект хэш-функции при каждом чтении. Такой подход уменьшает нагрузку на оперативную память и подходит для архивов, образов дисков и мультимедийных данных.
Для проверки целостности создаётся файл со справочными значениями. В него записывают результат вычисления хэша и имя файла. При последующей проверке выполняется повторное вычисление и сравнение с сохранённым значением. Несовпадение означает изменение содержимого или повреждение данных.
В командной строке процесс выполняется через утилиты sha256sum или sha512sum с передачей имени файла. Для автоматизации можно оформить проверку в виде скрипта, который перебирает записи в списке контрольных значений и сверяет их с текущими данными на диске.
Сравнение полученного хэша со справочным значением

Сравнение хэшей выполняется для подтверждения идентичности данных. Процесс включает вычисление хэша текущего файла и сопоставление с заранее сохранённым контрольным значением. Несовпадение указывает на изменение или повреждение данных.
Рекомендованные шаги:
- Выберите алгоритм хэширования, соответствующий справочному значению.
- Вычислите хэш текущего файла или строки.
- Приведите обе строки хэшей к единому формату: одинаковая кодировка, нижний регистр, отсутствие лишних символов.
- Сравните значения побайтово или через стандартные функции сравнения строк.
- При несовпадении зафиксируйте событие для дальнейшего анализа.
Для автоматизации сравнения удобно использовать списки справочных значений. Пример структуры:
- file_name.txt – 3a7bd3e2360a…
- backup.iso – e4d909c290d0…
В скриптах и командной строке сравнение выполняется простым сопоставлением, либо с помощью утилит типа diff или встроенных функций Python (==), что позволяет оперативно выявлять расхождения.
Использование хэша в процессе аутентификации или проверки данных

Хэши применяют для проверки подлинности паролей, токенов и файлов без хранения исходных данных в открытом виде. При аутентификации пользователя в базе сохраняют хэш пароля, а при входе вычисляют хэш введённого значения и сравнивают с сохранённым.
Для паролей используют алгоритмы с замедлением вычислений, такие как bcrypt, PBKDF2, Argon2. Они увеличивают время генерации хэша, что снижает вероятность успешного подбора при атаках методом перебора.
При проверке целостности файлов и данных хэш сравнивают с контрольным значением, полученным от надёжного источника. Совпадение гарантирует отсутствие изменений; несовпадение сигнализирует о возможной подмене, повреждении или ошибках передачи.
Для сетевых протоколов хэш используют совместно с солью или дополнительными ключами, чтобы исключить возможность подделки. Например, HMAC применяет секретный ключ вместе с хэш-функцией для защиты сообщений от изменения и подделки в канале передачи данных.
Вопрос-ответ:
Какие алгоритмы хэширования подходят для проверки целостности файлов?
Для проверки файлов чаще всего используют MD5 и SHA-1 для локального контроля, когда нет угрозы внешней атаки. Для задач, где важна стойкость к подделке или работа с конфиденциальными данными, применяют SHA-256 и SHA-512, так как они обеспечивают более надёжное хэширование и меньше подвержены коллизиям.
Как правильно подготовить текстовые данные перед вычислением хэша?
Необходимо привести все данные к единой кодировке, предпочтительно UTF-8, удалить лишние пробелы в начале и конце строк, а также нормализовать переносы строк (\n и \r\n). Это важно, чтобы одинаковые по смыслу данные не выдавали разные значения хэша из-за различий в формате.
Можно ли вычислять хэш больших файлов без загрузки их целиком в память?
Да, для больших файлов используют метод поэтапного чтения блоками фиксированного размера, например 64 КБ или 1 МБ. Каждый блок передаётся в функцию update() хэш-объекта, после чего формируется итоговый хэш через hexdigest(). Такой подход снижает нагрузку на оперативную память и позволяет работать с файлами десятков гигабайт.
Как использовать хэш для проверки паролей в приложениях?
Пароли никогда не хранят в открытом виде. Вместо этого сохраняют хэш, полученный через алгоритмы с замедлением вычислений, например bcrypt, PBKDF2 или Argon2. При вводе пароля система вычисляет хэш введённого значения и сравнивает его с сохранённым. Совпадение подтверждает корректность пароля, несовпадение — отказ в доступе.
Какие утилиты позволяют быстро вычислить хэш в командной строке?
На Linux и macOS используют md5sum, sha1sum, sha256sum, sha512sum. На Windows в PowerShell применяют Get-FileHash с указанием алгоритма, например Get-FileHash C:\file.zip -Algorithm SHA256. Для строк можно передавать данные через стандартный поток, исключая лишние символы, чтобы получить корректный результат.