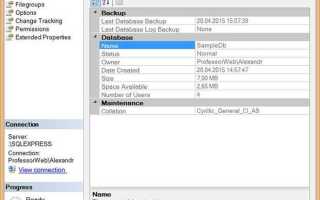
Работа с таблицами в SQL начинается с точного понимания структуры базы данных. Для большинства СУБД, включая MySQL, PostgreSQL и SQL Server, список таблиц можно получить с помощью команд SHOW TABLES или SELECT table_name FROM information_schema.tables. Это позволяет сразу определить, какие объекты доступны для анализа и дальнейшей работы.
При первом знакомстве с данными полезно просматривать ограниченное количество строк с помощью SELECT * FROM table_name LIMIT 10 или аналогичных операторов. Это позволяет оценить корректность данных и выявить потенциальные аномалии, не загружая всю таблицу. Дополнительно стоит проверять наличие ключей и связей между таблицами, что облегчает построение запросов с объединениями.
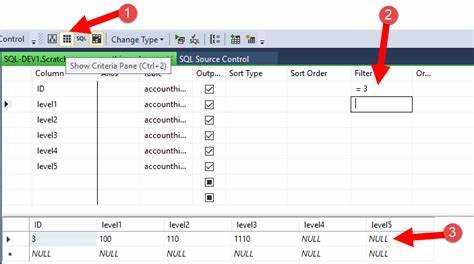
Практическая работа с таблицами включает сортировку и фильтрацию данных на этапе просмотра. Использование WHERE, ORDER BY и LIMIT помогает получать нужные срезы информации без излишней нагрузки на систему. Такой подход ускоряет анализ и обеспечивает точность дальнейших операций с данными.
Подключение к базе данных через командную строку и GUI
Для подключения к базе данных через командную строку в MySQL используется команда mysql -u username -p -h hostname database_name. После ввода пароля открывается интерактивная сессия, где можно выполнять SQL-запросы и проверять структуру таблиц. В PostgreSQL аналогичная операция выполняется через psql -U username -d database_name -h hostname, с возможностью сразу использовать команды \dt для просмотра списка таблиц.
При работе с GUI-инструментами, такими как DBeaver, pgAdmin или MySQL Workbench, подключение настраивается через создание нового подключения с указанием хоста, порта, имени пользователя, пароля и имени базы. После сохранения соединения появляется дерево объектов, где можно сразу видеть таблицы, их поля и связи. GUI позволяет просматривать данные без ручного написания запросов, а также применять фильтры и сортировку для быстрого анализа.
Для обеих форм подключения важно проверять права пользователя. Даже успешное соединение не гарантирует доступ к таблицам без соответствующих привилегий. Команды SHOW GRANTS в MySQL или \du в PostgreSQL позволяют убедиться в наличии прав на чтение таблиц и выполнение выборок.
Просмотр списка таблиц в выбранной базе данных
В PostgreSQL аналогичную задачу решает запрос к information_schema.tables: SELECT table_name FROM information_schema.tables WHERE table_schema=’public’. Это позволяет сразу получить таблицы конкретной схемы и исключить системные объекты. Для визуального контроля можно использовать команду \dt в интерактивной сессии psql.
При работе с GUI-инструментами, такими как DBeaver или MySQL Workbench, список таблиц отображается в дереве объектов базы данных. Рекомендуется сразу проверять количество записей в таблицах, чтобы оценить их размер и важность для анализа, используя SELECT COUNT(*) или встроенные показатели GUI.
Для больших баз данных полезно группировать таблицы по схемам или по функциональным группам. В SQL Server это достигается через запрос SELECT name FROM sys.tables с фильтрацией по схеме, что ускоряет навигацию и позволяет сосредоточиться на нужных объектах без перебора всех таблиц вручную.
Получение структуры таблицы с помощью DESCRIBE и SHOW COLUMNS
Команда DESCRIBE table_name в MySQL позволяет получить полное описание структуры таблицы, включая следующие элементы:
- Field – название столбца;
- Type – тип данных и размер поля;
- Null – разрешены ли значения NULL;
- Key – информация о первичных и уникальных ключах;
- Default – значение по умолчанию для столбца;
- Extra – дополнительные свойства, например, AUTO_INCREMENT.
- Можно использовать LIKE ‘prefix%’, чтобы получить только определённые поля;
- Применение WHERE позволяет быстро проверять ограничения и типы данных конкретных столбцов;
- Отображение через GUI предоставляет визуальную схему таблицы с подсветкой ключей и индексов.
Для больших таблиц рекомендуется сохранять результаты DESCRIBE или SHOW COLUMNS в отдельную таблицу или файл CSV. Это позволяет:
- Сравнивать структуры таблиц между базами данных;
- Отслеживать изменения схемы при обновлениях;
- Автоматизировать проверку совместимости типов данных при миграции.
Регулярная проверка структуры таблицы помогает избежать ошибок при выборках и объединениях, особенно когда таблица содержит более 50 столбцов или сложные ключи.
Выбор первых строк таблицы для быстрой проверки данных
Для первичного анализа таблицы важно ограничивать количество возвращаемых строк. В MySQL и PostgreSQL используется оператор LIMIT:
- SELECT * FROM table_name LIMIT 10; – отображает первые 10 записей таблицы;
- Для PostgreSQL можно применять FETCH FIRST 10 ROWS ONLY в SQL-стандарте;
- В SQL Server используется SELECT TOP 10 * FROM table_name.
Выбор первых строк помогает выявить:
- Типы данных и формат записей;
- Наличие пустых или некорректных значений;
- Соответствие реальных данных документации или структуре таблицы.
При проверке таблиц с большим количеством строк рекомендуется сочетать LIMIT с сортировкой и фильтрацией:
- Использовать ORDER BY для просмотра актуальных или последних данных;
- Применять WHERE для выбора записей по критериям, например WHERE status=’active’;
- Комбинировать LIMIT и OFFSET для последовательного анализа блоков данных без перегрузки памяти.
Регулярная практика проверки первых строк позволяет оперативно выявлять аномалии и формировать понимание структуры таблицы перед сложными выборками и объединениями.
Фильтрация и сортировка при просмотре таблицы
Фильтрация данных позволяет быстро выделять нужные записи без загрузки всей таблицы. Основные методы включают использование оператора WHERE с условиями по столбцам, например:
| Пример | Описание |
|---|---|
| SELECT * FROM orders WHERE status=’completed’; | Выбирает только завершённые заказы. |
| SELECT * FROM employees WHERE hire_date > ‘2025-01-01’; | Отбирает сотрудников, принятых после 1 января 2025 года. |
| SELECT * FROM products WHERE price BETWEEN 100 AND 500; | Показывает товары с ценой от 100 до 500 единиц. |
Сортировка упрощает анализ данных, особенно при больших таблицах. Для этого используется ORDER BY:
| Пример | Описание |
|---|---|
| SELECT * FROM sales ORDER BY sale_date DESC; | Отображает продажи в порядке от последних к ранним. |
| SELECT * FROM customers ORDER BY last_name ASC, first_name ASC; | Сортирует клиентов по фамилии и имени по возрастанию. |
Рекомендуется комбинировать фильтрацию и сортировку для точного выбора данных:
| Пример | Описание |
|---|---|
| SELECT * FROM orders WHERE status=’pending’ ORDER BY order_date ASC LIMIT 20; | Показывает первые 20 ожидающих заказов, отсортированных по дате. |
| SELECT * FROM products WHERE stock < 50 ORDER BY stock ASC; | Отображает товары с низким запасом, начиная с самых маленьких остатков. |
Такой подход ускоряет проверку таблиц и позволяет оперативно выявлять ключевые записи для анализа или корректировки данных.
Просмотр связанных таблиц через ключи и связи
Для анализа связанных таблиц необходимо понимать структуру ключей. Первичные ключи (PRIMARY KEY) идентифицируют уникальные записи, а внешние ключи (FOREIGN KEY) связывают таблицы. В MySQL структура ключей отображается через SHOW CREATE TABLE table_name или SHOW KEYS FROM table_name, что позволяет увидеть, какие столбцы участвуют в связях.
В PostgreSQL аналогично используется information_schema.table_constraints и information_schema.key_column_usage для определения зависимостей:
- Определение внешнего ключа: SELECT constraint_name, table_name, column_name, foreign_table_name, foreign_column_name FROM information_schema.key_column_usage;
- Анализ, какие таблицы ссылаются на конкретную таблицу, помогает строить объединения (JOIN) и проверять целостность данных.
Для быстрого просмотра связанных таблиц через GUI в DBeaver, pgAdmin или MySQL Workbench можно открыть схему таблицы и перейти в раздел Relationships или References. Это позволяет визуально отследить связи, определить тип JOIN и сразу понять, какие столбцы участвуют в объединениях.
При работе с большим количеством связанных таблиц рекомендуется:
- Составлять схему зависимостей с названиями первичных и внешних ключей;
- Проверять наличие индексов на внешних ключах для ускорения выборок и объединений;
- Использовать выборку только связанных столбцов, чтобы минимизировать нагрузку на сервер при JOIN больших таблиц.
Эти методы позволяют оперативно выявлять зависимости, избегать ошибок при объединениях и строить корректные запросы для анализа данных.
Использование ограничений выборки для больших таблиц
При работе с таблицами, содержащими сотни тысяч и миллионы записей, необходимо ограничивать выборку, чтобы ускорить анализ и избежать перегрузки памяти. В MySQL и PostgreSQL для этого используется LIMIT или FETCH FIRST:
- SELECT * FROM orders LIMIT 100; – отображает первые 100 строк таблицы;
- Для PostgreSQL допустимо SELECT * FROM orders FETCH FIRST 100 ROWS ONLY;
- В SQL Server используется SELECT TOP 100 * FROM orders.
Комбинация ограничений выборки с фильтрацией и сортировкой позволяет выбирать релевантные данные без перегрузки системы:
- WHERE фильтрует записи по критериям, например status=’active’;
- ORDER BY позволяет отсортировать результаты по дате или приоритету;
- OFFSET используется для постраничного просмотра больших таблиц, например LIMIT 100 OFFSET 200, что возвращает строки с 201 по 300.
Для регулярного анализа больших таблиц рекомендуется сохранять выборку в промежуточные таблицы или представления (CREATE VIEW), чтобы не повторять тяжёлые запросы каждый раз. Также полезно проверять наличие индексов на столбцах, участвующих в фильтрах и сортировке, чтобы снизить время выполнения выборки.
Использование этих методов позволяет получать контрольные срезы данных, выявлять аномалии и корректно планировать сложные запросы без перегрузки базы данных.
Вопрос-ответ:
Как быстро получить список всех таблиц в базе данных MySQL?
Для MySQL достаточно использовать команду SHOW TABLES в выбранной базе данных. Она возвращает все таблицы, доступные пользователю. Если нужно отобрать только определённые таблицы, можно добавить фильтр с помощью LIKE, например: SHOW TABLES LIKE ‘user%’ для таблиц, имена которых начинаются с «user».
Чем отличается DESCRIBE от SHOW COLUMNS при просмотре структуры таблицы?
Обе команды показывают информацию о столбцах таблицы, включая имена, типы данных, ограничения и наличие ключей. DESCRIBE чаще используется в MySQL для быстрого просмотра, а SHOW COLUMNS позволяет добавлять фильтры по имени столбца с помощью LIKE и выводит аналогичную информацию. В практических задачах выбор команды зависит от необходимости фильтрации или интеграции в скрипт.
Как выбрать только несколько первых строк большой таблицы, чтобы проверить данные?
Для ограниченной выборки в MySQL и PostgreSQL используют оператор LIMIT: SELECT * FROM table_name LIMIT 10; — возвращает первые 10 строк. В SQL Server применяют SELECT TOP 10 * FROM table_name. Если нужно просматривать следующие блоки данных, добавляют OFFSET, например LIMIT 10 OFFSET 10, чтобы получить строки с 11 по 20.
Как определить связи между таблицами через внешние ключи?
В MySQL информацию о внешних ключах можно получить через SHOW CREATE TABLE table_name или SHOW KEYS FROM table_name. В PostgreSQL используются таблицы information_schema.table_constraints и information_schema.key_column_usage, где можно узнать, какие столбцы ссылаются на другие таблицы. GUI-инструменты, такие как DBeaver или pgAdmin, позволяют визуально отобразить эти связи в виде схемы.
Как фильтровать и сортировать данные при просмотре таблицы, чтобы не загружать всю таблицу?
Для фильтрации используют WHERE, например SELECT * FROM orders WHERE status=’completed’. Для сортировки применяют ORDER BY: ORDER BY order_date DESC покажет последние записи первыми. Ограничение количества строк с LIMIT позволяет просматривать только нужное количество записей. Сочетание этих операторов помогает анализировать данные точечно без перегрузки системы.
Как узнать структуру таблицы в PostgreSQL без просмотра всех данных?
В PostgreSQL можно использовать системные представления information_schema.columns для получения информации о столбцах таблицы. Пример запроса: SELECT column_name, data_type, is_nullable, column_default FROM information_schema.columns WHERE table_name=’table_name’; Этот метод показывает имена колонок, типы данных, возможность NULL и значения по умолчанию, позволяя изучить структуру таблицы без извлечения всех строк.
Можно ли быстро проверить данные в большой таблице, не загружая её полностью?
Да, для этого используют ограничение выборки. В MySQL и PostgreSQL применяется LIMIT, например: SELECT * FROM orders LIMIT 20; — возвращает первые 20 записей. Также можно добавить фильтры через WHERE, чтобы просмотреть только определённые группы записей, и сортировку через ORDER BY для упорядочивания данных по дате или другому столбцу. Такой подход позволяет изучать содержимое таблицы без перегрузки сервера.