Содержание статьи

В Python двоичные данные часто представлены в виде строк, полученных из файлов, сетевых протоколов, пользовательского ввода или результатов побитовых операций. Для дальнейших вычислений такие строки требуется преобразовать в целое число, соблюдая строгие правила формата: допустимы только символы 0 и 1, а также корректная интерпретация знака и основания системы счисления.
Язык Python предоставляет встроенные инструменты для перевода двоичной строки в число, включая функцию int() с указанием основания 2. Этот механизм поддерживает как строки без префикса, так и значения с обозначением 0b, однако при некорректных данных приводит к исключению ValueError. Поэтому перед преобразованием важно понимать, какие форматы допустимы и как контролировать ошибки.
Помимо стандартных средств, в практике программирования встречаются ситуации, когда требуется ручной разбор двоичной строки: например, при анализе битовых флагов, учебных задачах или ограничениях на использование встроенных функций. В таких случаях применяются циклы, операции сдвига и сложения, позволяющие точно управлять процессом перевода.
Отдельного внимания заслуживает работа с длинными двоичными строками. Python не ограничивает размер целых чисел, но длина входной строки влияет на время обработки и потребление памяти. При разработке прикладных решений важно учитывать источник данных, возможные ошибки формата и необходимость предварительной проверки строки перед преобразованием.
Преобразование двоичной строки в целое число с помощью функции int()
В Python основной способ перевода двоичной строки в целое число – использование встроенной функции int() с явным указанием основания системы счисления. Для двоичных данных вторым аргументом передаётся значение 2, что однозначно задаёт интерпретацию входной строки.
Базовый синтаксис преобразования выглядит следующим образом:
value = int("101101", 2)В результате строка интерпретируется как двоичное число, и переменная value получает десятичное значение 45. Такой подход корректно обрабатывает строки произвольной длины, ограниченной только доступной памятью.
Функция int() принимает несколько допустимых форматов двоичных строк:
- строки без префикса, содержащие только символы 0 и 1;
- строки с префиксом 0b или 0B;
- значения с ведущими нулями, например «000101».
Примеры корректных вызовов:
int("0b1101", 2)
int("1101", 2)
int("0001101", 2)Во всех случаях результат будет идентичным. При этом наличие префикса 0b не отменяет необходимость указывать основание, если строка передаётся как текст.
При обнаружении недопустимых символов функция генерирует исключение ValueError. К типичным причинам ошибки относятся:
- наличие пробелов внутри строки;
- использование символов, отличных от 0 и 1;
- пустая строка.
Для прикладного кода рекомендуется оборачивать вызов int() в конструкцию try/except, если источник строки не контролируется напрямую. Это позволяет корректно реагировать на некорректный ввод без остановки программы.
Обработка двоичных строк с префиксом 0b при преобразовании
Если двоичная строка содержит префикс 0b или 0B, функция int() корректно обработает её при передаче основания 2:
int("0b101011", 2)Результатом будет целое число 43. При этом сам префикс не участвует в вычислении значения и используется только как маркер формата.
Важно различать поведение функции int() при разных вариантах вызова:
| Входная строка | Вызов | Результат |
|---|---|---|
| 0b1101 | int(«0b1101», 2) | 13 |
| 0b1101 | int(«0b1101») | 13 |
| 1101 | int(«1101») | 1101 |
Если основание не указано явно, Python автоматически распознаёт префикс 0b и выполняет преобразование. Однако для строк без префикса такое поведение отсутствует, и значение интерпретируется как десятичное.
В прикладных сценариях часто встречаются смешанные форматы данных. Чтобы обеспечить стабильное поведение, рекомендуется:
- всегда указывать основание 2 при работе с двоичными строками;
- нормализовать входные данные, удаляя префикс с помощью lstrip(«0b») или среза;
- избегать неявного преобразования без указания основания.
Пример безопасной обработки строки с возможным префиксом:
binary_str = binary_str.lower()
value = int(binary_str, 2)Такой подход снижает риск логических ошибок при работе с различными источниками двоичных данных и упрощает поддержку кода.
Проверка корректности двоичной строки перед переводом в число
Перед преобразованием двоичной строки в целое число необходимо убедиться, что входные данные соответствуют ожидаемому формату. Даже один недопустимый символ приводит к исключению ValueError, поэтому проверка особенно важна при работе с пользовательским вводом и внешними источниками данных.
Минимальные требования к корректной двоичной строке включают:
- непустое значение;
- отсутствие пробелов и управляющих символов;
- использование только символов 0 и 1 либо допустимого префикса 0b.
Для базовой проверки удобно применять строковые методы. Например, после удаления возможного префикса можно проверить состав символов:
clean = binary_str[2:] if binary_str.startswith(("0b", "0B")) else binary_str
clean.isdigit() and set(clean) <= {"0", "1"}Метод isdigit() отсеивает буквы и специальные символы, а проверка множества гарантирует отсутствие цифр, отличных от двоичных.
При необходимости более строгого контроля используется регулярное выражение:
import re
bool(re.fullmatch(r"(0b)?[01]+", binary_str))Такой вариант позволяет за один шаг проверить и структуру строки, и допустимость символов.
Альтернативный подход – попытка преобразования с перехватом исключения. Он подходит для ситуаций, когда дополнительная логика не требуется:
try:
value = int(binary_str, 2)
except ValueError:
value = NoneРучной перевод двоичной строки в число с использованием цикла

Ручной перевод двоичной строки применяется в случаях, когда запрещено использовать встроенную функцию int() или требуется полный контроль над алгоритмом преобразования. Основа метода – последовательная обработка каждого бита с накоплением результата.
Алгоритм опирается на позиционную природу двоичной системы счисления. При обходе строки слева направо текущее значение умножается на 2, после чего к нему прибавляется числовое значение очередного символа:
result = 0
for bit in "101101":
result = result * 2 + int(bit)После завершения цикла переменная result содержит десятичное представление двоичного числа. Такой подход одинаково корректно работает для строк любой длины.
Перед выполнением цикла необходимо исключить наличие префикса 0b, так как он не участвует в вычислении:
binary_str = binary_str[2:] if binary_str.startswith(("0b", "0B")) else binary_strАльтернативный вариант использует обратный обход строки и степень двойки, соответствующую позиции бита:
result = 0
power = 0
for bit in reversed("101101"):
if bit == "1":
result += 2 power
power += 1Этот способ наглядно демонстрирует связь между индексом символа и весом разряда, но требует дополнительной переменной.
Ручная реализация полезна для учебных задач, анализа битовых последовательностей и встроенных систем, где важно понимать каждую операцию преобразования и управлять логикой обработки на уровне отдельных символов.
Преобразование длинных двоичных строк и возможные ограничения
Python поддерживает целые числа произвольной разрядности, поэтому формального ограничения на длину двоичной строки не существует. Преобразование строки из тысяч и десятков тысяч бит корректно выполняется как встроенной функцией int(), так и при ручной обработке. Ограничения в таких случаях связаны не с типом данных, а с ресурсами среды выполнения.
Основная нагрузка при работе с длинными двоичными строками приходится на память и время вычислений. При вызове int(binary_str, 2) интерпретатор выделяет память под большое целое число и выполняет арифметические операции над ним. Чем больше длина строки, тем заметнее задержка, особенно при массовых преобразованиях в циклах.
При чтении двоичных данных из файлов и сетевых источников рекомендуется избегать промежуточных копий строк. Лучше сразу обрабатывать данные в одном представлении, без лишних преобразований и конкатенаций, так как каждая операция со строкой создаёт новый объект в памяти.
Для ручного перевода длинных последовательностей важно учитывать стоимость операций возведения в степень. Алгоритмы с накоплением результата через умножение на 2 и сложение требуют меньше вычислений, чем подходы с вычислением 2 n для каждого разряда.
Если двоичная строка используется только для анализа отдельных битов, а не для получения числового значения целиком, целесообразно отказаться от полного преобразования и работать напрямую со строкой или байтовым представлением. Это снижает нагрузку и упрощает обработку данных большого объёма.
Типичные ошибки при переводе двоичной строки в число и их устранение
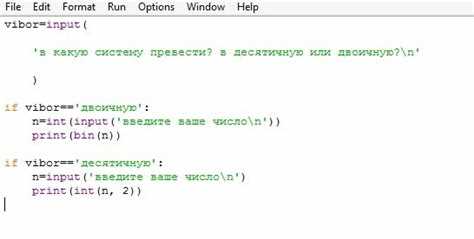
Наиболее частая ошибка при преобразовании двоичной строки – передача данных с недопустимыми символами. Пробелы, символы перевода строки и цифры, отличные от 0 и 1, приводят к выбросу исключения ValueError. Перед вызовом int() строку следует очищать с помощью strip() и проверять состав символов.
Другая распространённая проблема связана с отсутствием указания основания системы счисления. Вызов int(«1011») интерпретирует строку как десятичное число и возвращает 1011, а не 11. Для двоичных данных аргумент 2 должен передаваться явно, если строка не содержит префикс 0b.
Ошибки также возникают при некорректной обработке префикса. Попытка вручную удалить 0b без проверки начала строки может привести к искажению данных. Использовать следует только точное условие startswith((«0b», «0B»)), а не замену всех вхождений символов.
Пустая строка или значение None нередко передаются в функцию преобразования при сбоях ввода. Такие случаи не обрабатываются автоматически и требуют предварительной проверки длины строки и типа данных.
При ручной реализации перевода часто допускается ошибка умножения результата после добавления бита, а не до него. Правильный порядок операций – сначала умножение текущего значения на 2, затем прибавление разряда. Нарушение этой последовательности приводит к неверному числу даже при корректных входных данных.
Вопрос-ответ:
Почему int(«1010») возвращает 1010, а не 10?
Если вторым аргументом не указать основание системы счисления, функция int() трактует строку как десятичное число. Поэтому строка «1010» воспринимается как обычное целое значение. Для корректного перевода двоичной строки требуется вызвать int(«1010», 2) или использовать формат с префиксом 0b.
Можно ли передавать в int() двоичную строку с префиксом 0b?
Да, строка с префиксом 0b корректно обрабатывается. Если указать основание 2, префикс будет проигнорирован. Если основание не передавать, Python сам распознает формат по префиксу и выполнит преобразование. Для стабильного поведения в коде чаще используют явное указание основания.
Как проверить двоичную строку, чтобы не получить ValueError?
Перед преобразованием стоит убедиться, что строка не пустая и содержит только допустимые символы. Практика показывает, что удобно сначала удалить возможный префикс 0b, затем проверить, что каждый символ равен «0» или «1». Альтернативный вариант — попытка преобразования в блоке try/except без предварительных проверок.
Есть ли ограничения на длину двоичной строки при переводе в число?
Фиксированного лимита на длину двоичной строки нет, так как Python работает с целыми числами произвольного размера. Ограничения проявляются через потребление памяти и время обработки. При работе с очень длинными последовательностями заметную нагрузку создают массовые преобразования в циклах.
Зачем выполнять ручной перевод двоичной строки, если есть int()?
Ручная реализация используется в учебных задачах, при анализе битов или в средах с ограниченным набором функций. Такой подход помогает контролировать каждую операцию, убирать префиксы, отслеживать порядок обработки разрядов и лучше понимать, как формируется числовое значение.
Почему при чтении двоичной строки из файла преобразование иногда завершается ошибкой?
При чтении данных из файла строка часто содержит символ перевода строки \n или пробелы в начале и конце. Эти символы визуально не заметны, но делают строку некорректной для преобразования. Перед вызовом int() строку следует обработать методом strip(), а при необходимости дополнительно проверить состав символов.
Что выбрать для большого количества преобразований: int() или собственный цикл?
Для массового перевода двоичных строк встроенная функция int() даёт предсказуемый результат и меньше кода. Собственный цикл оправдан, когда требуется нестандартная логика обработки битов или частичное вычисление значения. Если задача сводится только к получению числа, использование int(binary_str, 2) упрощает поддержку и снижает вероятность ошибок.