Содержание статьи

Kernel general представляет собой вычислительное ядро, предназначенное для выполнения операций свертки и фильтрации на больших объемах данных. Его архитектура позволяет одновременно обрабатывать несколько потоков данных, что ускоряет выполнение алгоритмов машинного обучения и анализа изображений. Типичные ядра поддерживают операции с 32- и 64-битными числами с плавающей запятой и могут работать на CPU и GPU без необходимости переписывать код.
В основе работы Kernel general лежит концепция разделения задач на независимые блоки, которые затем выполняются параллельно. Для оптимального использования рекомендуется разбивать данные на фрагменты размером от 128×128 до 512×512 элементов, чтобы уменьшить задержки при доступе к памяти и снизить нагрузку на кэш процессора.
Настройка параметров ядра напрямую влияет на производительность: выбор шага свертки, размер фильтра и порядок операций могут менять время обработки до 3–5 раз. Для задач обработки изображений с высоким разрешением оптимально использовать ядра с поддержкой векторизации и SIMD-инструкций, что позволяет выполнять до 8 операций одновременно на каждом ядре.
Принцип работы ядра Kernel general в вычислениях

Ядро Kernel general выполняет вычисления путем применения функций свертки к блокам данных, разделенных на независимые потоки. Каждому потоку назначается конкретный участок памяти, что снижает конфликты доступа и минимизирует ожидание кэша. Оптимальный размер блока для CPU обычно составляет 256–512 элементов, для GPU – 1024–2048 элементов на поток.
Алгоритм работы ядра строится на последовательном считывании данных из оперативной памяти в локальные регистры, применении заданной функции и записи результата обратно. Для ускорения вычислений рекомендуется использовать векторные инструкции SIMD и распараллеливание по ядрам процессора. В вычислениях с плавающей запятой точность следует выбирать исходя из задачи: float32 подходит для нейросетей, float64 – для инженерных расчетов с высокой точностью.
Kernel general поддерживает динамическое распределение нагрузки: при изменении объема данных ядро перераспределяет блоки между потоками без остановки основного процесса. Для оптимизации времени выполнения важно заранее определять последовательность операций и минимизировать количество операций чтения и записи, так как доступ к памяти является узким местом при обработке массивов более 10 млн элементов.
При реализации вычислений ядро рекомендуется тестировать на различных конфигурациях аппаратуры, чтобы определить оптимальное количество потоков и размер блоков. Практическая рекомендация: при обработке изображений размером 4096×4096 пикселей использовать разбиение на блоки 512×512 и параллельное выполнение сверток по всем доступным ядрам GPU.
Типы данных и совместимость с различными платформами
Kernel general поддерживает несколько типов данных: целые числа (int8, int16, int32), числа с плавающей запятой (float16, float32, float64) и комплексные числа. Выбор типа данных напрямую влияет на скорость вычислений и потребление памяти. Для нейросетей рекомендуется использовать float16 или float32, так как они обеспечивают баланс между точностью и временем обработки. Для инженерных расчетов и моделирования физических процессов целесообразно использовать float64 для минимизации ошибок округления.
Совместимость ядра обеспечивается благодаря абстракции вычислительных потоков и поддержке инструкций SIMD для CPU и CUDA/OpenCL для GPU. Ядро можно запускать на архитектурах x86, ARM, а также на большинстве современных видеокарт с поддержкой параллельных вычислений. Рекомендуется проверять поддержку инструкций на конкретной платформе перед запуском ресурсоемких вычислений.
Оптимизация работы с разными платформами требует учета размера блока данных, доступного объема кэша и пропускной способности памяти. Например, на GPU NVIDIA для float32 оптимальный блок составляет 1024–2048 элементов, на CPU с AVX512 – 256–512 элементов. Использование неподдерживаемых типов данных вызывает автоматическое преобразование, которое может снижать производительность до 30%.
При распределении задач между платформами рекомендуется заранее тестировать производительность для каждого типа данных и использовать профилировщик ядра. Это позволяет выявить узкие места в обработке массивов, таких как длительное чтение из глобальной памяти GPU или частые обращения к системной памяти на CPU.
Настройка параметров ядра для конкретных задач
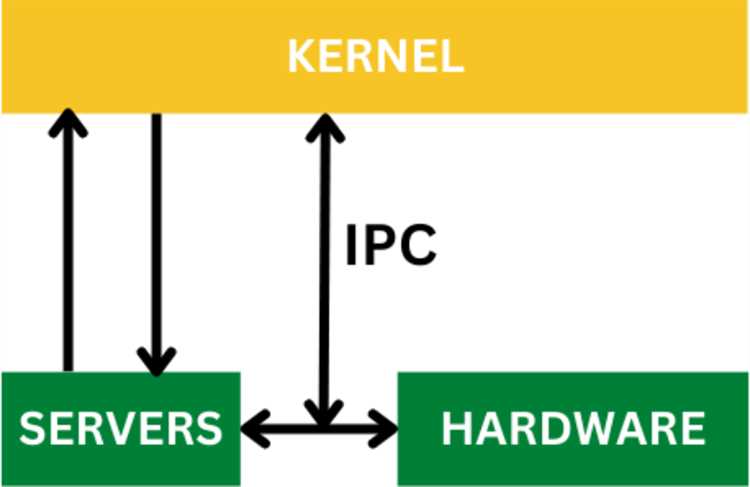
Настройка ядра Kernel general позволяет оптимизировать производительность для конкретных типов вычислений. Основные параметры, влияющие на работу:
- Размер блока данных: для CPU рекомендуется 256–512 элементов, для GPU – 1024–2048 элементов.
- Тип данных: float16 и float32 ускоряют обработку нейросетей, float64 необходим для высокоточных расчетов.
- Шаг свертки: уменьшение шага повышает точность фильтрации, но увеличивает время выполнения на 20–40%.
- Количество потоков: на GPU выбирается исходя из числа доступных ядер, на CPU – с учетом кэш-памяти и поддержки SIMD.
- Параметры кэширования: локальная буферизация блоков снижает обращения к основной памяти и уменьшает задержки.
Для практической настройки рекомендуется следующая последовательность действий:
- Определить тип задачи: свертка, фильтрация, матричные операции.
- Выбрать подходящий тип данных с учетом точности и объема памяти.
- Подобрать размер блоков и количество потоков для конкретного устройства.
- Включить локальное кэширование и минимизировать записи в глобальную память.
- Провести тесты производительности на небольших выборках и скорректировать параметры.
При обработке изображений размером свыше 4096×4096 пикселей рекомендуется использовать блоки 512×512 и распределять задачи равномерно между всеми доступными ядрами GPU для снижения времени выполнения до 25–30%.
Влияние Kernel general на скорость обработки данных
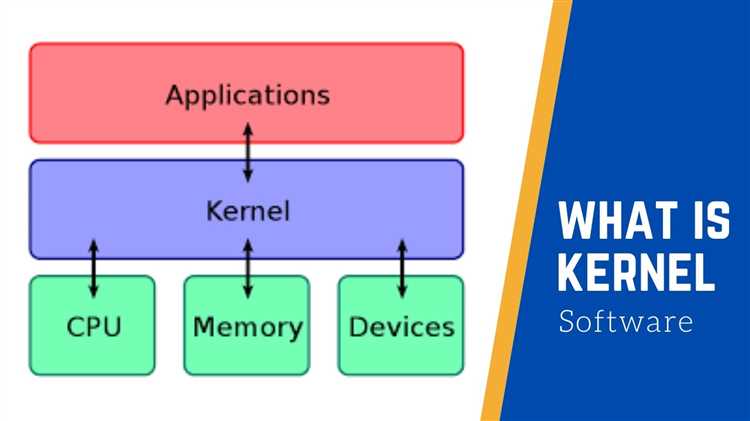
Скорость работы Kernel general зависит от параллельности вычислений, размера блоков данных и типа используемых инструкций. Основные факторы влияния:
- Параллельная обработка потоков: увеличение количества потоков до максимального числа ядер GPU или CPU сокращает время выполнения до 3–5 раз.
- Размер блоков: оптимальные блоки для GPU – 1024–2048 элементов, для CPU с AVX512 – 256–512 элементов. Несоответствующие размеры вызывают простаивание ядер и падение производительности.
- Тип данных: использование float16 на GPU ускоряет операции до 2 раз по сравнению с float32, но снижает точность.
- Доступ к памяти: частые обращения к глобальной памяти GPU или системной памяти CPU могут увеличивать время обработки массивов свыше 10 млн элементов на 40–50%.
- Кэширование и буферизация: предварительная загрузка блоков в локальный кэш уменьшает задержки и ускоряет свертки на 15–25%.
Для увеличения производительности рекомендуется:
- Разбивать данные на блоки, соответствующие кэш-памяти устройства.
- Использовать инструкции SIMD и векторизацию там, где это возможно.
- Проверять нагрузку на память и корректировать размер блоков для уменьшения простоев ядер.
- Тестировать различные комбинации числа потоков и типа данных, чтобы выбрать оптимальный вариант для конкретного оборудования.
Примеры применения Kernel general в реальных проектах
Kernel general активно используется в проектах машинного обучения для ускорения операций свертки в нейросетях. В проектах компьютерного зрения свертки размером 3×3 и 5×5 на GPU позволяют обрабатывать видео потоки 4K при 60 кадрах в секунду, минимизируя задержки.
В инженерных расчетах ядро применяют для численного моделирования физических процессов. Например, при расчетах гидродинамики с сеткой 1000×1000 элементов использование float64 и параллельных потоков снижает время симуляции с 8 часов до 1,5–2 часов на сервере с 8 ядрами и поддержкой AVX512.
В обработке больших массивов данных Kernel general используется для фильтрации сигналов и анализа временных рядов. Применение блоков размером 512–1024 элементов и буферизация потоков позволяет обрабатывать данные объемом до 50 млн элементов без перегрузки оперативной памяти.
Для оптимизации реальных проектов рекомендуется заранее выбирать тип данных, размер блоков и количество потоков. В задачах обработки изображений с высоким разрешением эффективнее распределять блоки равномерно по всем ядрам GPU, а в расчетных моделях использовать профилировщик для выявления узких мест в памяти и вычислениях.
Ошибки и ограничения при работе с Kernel general
Неправильный выбор типа данных может привести к потере точности или снижению производительности. Например, использование float64 на GPU без необходимости повышает нагрузку на память и снижает скорость до 40%, тогда как float16 может вызвать ошибки округления при сложных вычислениях.
Ошибки возникают также при несоответствии размера блоков возможностям устройства. Слишком маленькие блоки вызывают простаивание ядер, слишком большие – превышение кэш-памяти и увеличенные задержки при доступе к глобальной памяти.
При параллельной обработке потоков возможны конфликты доступа к общей памяти. Для минимизации рекомендуется заранее распределять блоки между потоками и использовать локальные буферы. Игнорирование этих рекомендаций приводит к снижению производительности до 30–35%.
Для стабильной работы Kernel general важно тестировать ядро на целевой платформе с реальными данными, использовать профилировщики и контролировать объемы кэширования. Это позволяет выявлять узкие места, предотвращать переполнение памяти и корректно распределять вычислительные ресурсы.
Вопрос-ответ:
Какие типы данных поддерживает Kernel general и как они влияют на вычисления?
Kernel general работает с целыми числами (int8, int16, int32), числами с плавающей запятой (float16, float32, float64) и комплексными числами. Выбор типа данных определяет точность и скорость обработки: float16 ускоряет операции в нейросетях, но снижает точность; float32 обеспечивает баланс между скоростью и точностью; float64 используется для инженерных расчетов с высокими требованиями к точности. Неправильный выбор может замедлить вычисления или привести к накоплению ошибок округления.
Почему размер блока данных в Kernel general влияет на производительность?
Производительность зависит от того, как блоки данных размещаются в кэше и распределяются по потокам. Слишком маленькие блоки вызывают простаивание ядер, так как часть вычислительных ресурсов простаивает, ожидая загрузки данных. Слишком большие блоки превышают доступный объем кэша, что приводит к частым обращениям к основной памяти и увеличению задержек. Для CPU с AVX512 оптимальный размер блока составляет 256–512 элементов, а для GPU – 1024–2048 элементов.
Как Kernel general используется в обработке изображений и видео?
В проектах компьютерного зрения ядро применяют для свертки и фильтрации изображений и видеопотоков. Например, для видео 4K с частотой 60 кадров в секунду Kernel general выполняет свертку размером 3×3 или 5×5 на GPU, распределяя блоки по доступным ядрам. Это позволяет быстро обрабатывать кадры без заметных задержек. Настройка размера блоков и количества потоков помогает сбалансировать загрузку памяти и ускорить вычисления.
Какие ограничения и ошибки встречаются при работе с Kernel general?
Чаще всего проблемы возникают из-за переполнения кэша при обработке массивов более 10 млн элементов, конфликта потоков при доступе к общей памяти и неверного выбора типа данных. Float64 на GPU без необходимости замедляет обработку, float16 может вызвать ошибки округления. Также неправильно подобранный размер блока может привести к простаиванию ядер или задержкам при обращении к памяти. Для стабильной работы рекомендуется тестировать ядро на конкретном устройстве и использовать локальные буферы для потоков.