Содержание статьи

Пробелы в строках Python часто становятся источником логических ошибок: некорректные сравнения, сбои при валидации данных, проблемы при разборе CSV, JSON или пользовательского ввода. Строка «user « и «user» визуально выглядят одинаково, но интерпретируются интерпретатором как разные значения. Поэтому контроль и удаление пробельных символов – обязательная часть работы с текстовыми данными.
В Python пробелами считаются не только обычные символы » «, но и табуляция \t, переводы строки \n, возврат каретки \r и другие пробельные Unicode-символы. Методы стандартного типа str позволяют обрабатывать такие случаи без сторонних библиотек, если понимать, какие именно символы они затрагивают и в каких ситуациях применимы.
Задачи очистки строк бывают разными: удалить пробелы по краям, убрать все пробелы внутри строки, сократить несколько пробелов между словами до одного или нормализовать ввод из форм и файлов. Для каждой из них в Python существует отдельный инструмент, и неправильный выбор метода может привести к потере данных или искажению структуры текста.
В статье разобраны прикладные способы удаления пробелов в строках Python с примерами, ограничениями и пояснениями, чтобы можно было сразу применять их в реальных сценариях: от обработки пользовательского ввода до подготовки данных для хранения и сравнения.
Удаление пробелов в начале и конце строки с помощью strip()
Метод strip() применяется, когда требуется удалить пробельные символы только по краям строки, не затрагивая содержимое между символами. Он возвращает новую строку, поэтому исходное значение не изменяется. Это важно учитывать при обработке данных, полученных из файлов, HTTP-запросов и форм ввода.
По умолчанию strip() удаляет все стандартные пробельные символы: пробел, табуляцию (\t), перевод строки (\n), возврат каретки (\r) и другие символы категории whitespace в Unicode. Это делает метод универсальным для очистки строк, поступающих из разных источников.
text = " \tPython\n"
clean = text.strip()
# clean == "Python"Метод можно ограничить конкретным набором символов, передав их аргументом. В этом случае будут удаляться только указанные символы, а не все пробельные. Аргумент интерпретируется как набор, а не как подстрока.
value = "---data---"
result = value.strip("-")
# result == "data"strip() следует использовать перед сравнением строк, сохранением значений в базу данных и проверкой пользовательского ввода. Он не подходит для удаления пробелов внутри строки, поэтому попытка применить его для нормализации текста с несколькими словами не даст ожидаемого результата.
Очистка только начальных пробелов методом lstrip()
Метод lstrip() удаляет пробельные символы исключительно в начале строки, сохраняя все символы справа без изменений. Он полезен в ситуациях, где ведущие пробелы мешают обработке данных, но структура строки после первого значимого символа должна остаться нетронутой.
По умолчанию lstrip() работает со всем набором пробельных символов Unicode. Это позволяет корректно очищать строки, полученные из файлов, логов или консольного ввода, где в начале часто встречаются табуляции и переводы строк.
line = "\t error: file not found"
clean = line.lstrip()
# clean == "error: file not found"Метод поддерживает аргумент с набором символов для удаления. В этом случае будут удаляться только указанные символы, пока они встречаются в начале строки.
path = "///api/v1/users"
result = path.lstrip("/")
# result == "api/v1/users"Типовые сценарии применения lstrip():
- обработка строк с фиксированным отступом в логах и конфигурационных файлах;
- очистка данных, где ведущие пробелы используются как визуальное форматирование;
- нормализация пользовательского ввода перед разбором команд;
- удаление служебных символов в начале строк при парсинге текста.
Важно учитывать, что lstrip() не удаляет символы в середине или в конце строки. Если в аргументе передан набор символов, метод не ищет их как последовательность, а проверяет каждый символ по отдельности, начиная с левого края.
Удаление только конечных пробелов методом rstrip()
Метод rstrip() предназначен для удаления пробельных символов с правой стороны строки. Он используется в ситуациях, где лишние символы в конце строки мешают сравнению значений, формированию отчетов или корректной записи данных, при этом начальная часть строки должна оставаться неизменной.
Без аргументов rstrip() удаляет все пробельные символы Unicode: пробелы, табуляции (\t), переводы строк (\n), возвраты каретки (\r) и другие символы, относящиеся к категории whitespace. Это особенно полезно при чтении строк из текстовых файлов, где символ переноса строки присутствует в конце почти каждой записи.
row = "status=ok \n"
clean = row.rstrip()
# clean == "status=ok"Метод поддерживает передачу набора символов для удаления. В этом случае rstrip() будет убирать только указанные символы, пока они располагаются в конце строки.
filename = "report.txt..."
result = filename.rstrip(".")
# result == "report.txt"rstrip() не затрагивает пробелы и символы внутри строки. При использовании аргумента следует учитывать, что удаляется любой символ из переданного набора, а не конкретная последовательность. Это важно при работе с расширениями файлов, маркерами форматирования и служебными символами в конце строк.
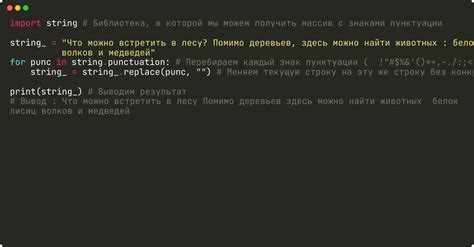
Полное удаление всех пробелов в строке через replace()
Метод replace() применяется, когда необходимо убрать все пробелы внутри строки, включая начальные, конечные и расположенные между символами. В отличие от методов семейства strip, он обрабатывает всю строку целиком, а не только её края.
Для удаления обычных пробелов используется замена символа » « на пустую строку. Результатом становится новая строка без пробелов, что удобно при нормализации идентификаторов, кодов, номеров документов и других значений, где разделители недопустимы.
text = "12 34 56 78"
clean = text.replace(" ", "")
# clean == "12345678"Следует учитывать, что replace() работает только с теми символами, которые указаны явно. Табуляции, переводы строки и другие пробельные символы не будут удалены без дополнительной обработки.
data = "A\tB C\nD"
result = data.replace(" ", "")
# result == "A\tBC\nD"Для полной очистки строки от разных типов пробельных символов требуется последовательное применение replace() или использование других инструментов. Метод подходит в случаях, когда точно известно, какие символы нужно удалить, и структура строки после очистки не должна содержать разделителей.
Удаление лишних пробелов между словами с помощью split() и join()
Связка методов split() и join() используется для нормализации текста, когда между словами встречается разное количество пробелов. Такой подход сохраняет сами слова, но приводит разделители к единому виду.
Вызов split() без аргументов разбивает строку по любым пробельным символам и автоматически игнорирует их повторения. Это означает, что последовательности из нескольких пробелов, табуляций или переводов строки не попадают в результат.
text = "Python – это язык"
parts = text.split()
# parts == ["Python", "–", "это", "язык"]После разбиения список элементов объединяется обратно в строку с помощью join(), где в качестве разделителя указывается одиночный пробел.
normalized = " ".join(parts)
# normalized == "Python – это язык"Работа с пробелами и табуляцией при помощи регулярных выражений

Регулярные выражения применяются, когда стандартные методы строк не покрывают требования к обработке пробельных символов. Модуль re позволяет точно управлять тем, какие виды пробелов удаляются и в каких позициях строки.
Для работы с пробелами и табуляцией чаще всего используется шаблон \s, который соответствует любому пробельному символу Unicode: пробелу, табуляции, переводу строки, возврату каретки и другим аналогам.
import re
text = "A\t B C\nD"
clean = re.sub(r"\s+", " ", text)
clean == "A B C D"Регулярные выражения позволяют решать более узкие задачи:
- удаление пробелов и табуляции только в начале строки с помощью r»^\s+»;
- очистка только конца строки шаблоном r»\s+$»;
- полное удаление всех пробельных символов через r»\s+» с заменой на пустую строку;
- замена табуляций на фиксированное количество пробелов для выравнивания текста.
result = re.sub(r"\s+$", "", "data\t \n")
# result == "data"Использование регулярных выражений оправдано при сложной очистке данных, но требует аккуратного подбора шаблонов. Неправильное выражение может удалить значимые разделители, особенно при работе с форматированным текстом или кодом.
Удаление пробелов в строках при обработке пользовательского ввода
Пользовательский ввод почти всегда содержит лишние пробелы: случайные нажатия клавиши пробела, копирование данных из внешних источников, автозаполнение форм. Если такие строки использовать без очистки, возникают ошибки при сравнении, проверке условий и сохранении данных.
Первым шагом обработки ввода обычно становится удаление пробелов по краям строки с помощью strip(). Это позволяет убрать невидимые символы, которые часто попадают в начало и конец значения при вводе.
user_input = input().strip()Для полей, где пробелы внутри недопустимы, применяется replace(). Такой подход используют при вводе номеров, кодов, идентификаторов и токенов.
code = input().replace(" ", "")Если ввод представляет собой текст с несколькими словами, целесообразно нормализовать количество пробелов между ними через split() и join(). Это делает данные пригодными для поиска и сравнения.
Типовые сценарии очистки пользовательского ввода:
| Тип данных | Проблема | Решение |
|---|---|---|
| Логин | Пробелы в начале и конце | strip() |
| Номер телефона | Пробелы между цифрами | replace(» «, «») |
| ФИО | Несколько пробелов между словами | » «.join(split()) |
| Команда | Табуляции и переносы строк | strip() или re.sub() |
Очистку следует выполнять до валидации и логической обработки данных. Это снижает количество ошибок и упрощает дальнейшую работу со строками независимо от источника ввода.
Типичные ошибки при удалении пробелов и способы их избежать
Одна из распространённых ошибок – ожидание, что strip() удалит пробелы внутри строки. Этот метод работает только с началом и концом, поэтому строка «a b» останется без изменений. Для обработки внутреннего содержимого следует применять replace(), split() и join() или регулярные выражения.
Часто игнорируется тот факт, что методы строк не изменяют исходный объект. Вызов text.strip() без присваивания результата приводит к сохранению строки с пробелами. Всегда необходимо работать с возвращаемым значением.
Ошибка возникает и при использовании аргументов strip(), lstrip() и rstrip(). Переданный параметр воспринимается как набор символов, а не как цельная подстрока. Например, вызов rstrip(«.txt») может удалить буквы t и x в конце строки, если они совпадают с набором символов.
Замена пробелов через replace(» «, «») нередко применяется без учёта табуляций и переводов строки. В результате часть пробельных символов остаётся в данных. При работе с вводом из файлов и форм следует учитывать весь спектр whitespace.
Чрезмерное удаление пробелов также приводит к проблемам. Полная очистка строки разрушает структуру текста, если пробелы выполняют роль разделителей. Перед выбором метода важно определить, какие пробелы являются служебными, а какие несут смысловую нагрузку.
Вопрос-ответ:
Почему strip() не убирает пробелы между словами?
Метод strip() обрабатывает только начало и конец строки. Его задача — удалить пробельные символы, которые находятся по краям. Пробелы между словами считаются частью содержимого строки и остаются без изменений. Для работы с ними подходят split() и join() либо замена через replace().
Как удалить пробелы и табуляцию из строки, считанной из файла?
Строки из файлов часто содержат символы \n и \t. Если нужно убрать их по краям, достаточно rstrip() или strip(). Если требуется очистить строку полностью, включая табуляцию внутри, можно использовать регулярное выражение с шаблоном \s+ или выполнить несколько замен через replace().
Почему после вызова lstrip() строка остаётся прежней?
Методы строк в Python не изменяют объект на месте. lstrip() возвращает новую строку, а исходная остаётся без изменений. Если результат не присвоен переменной, визуально кажется, что метод не сработал.
Можно ли удалить только несколько пробелов подряд, оставив один?
Да, для этого удобно использовать split() без аргументов и затем соединить элементы через join() с одиночным пробелом. Такой подход убирает повторяющиеся пробельные символы и сохраняет читаемую структуру текста.
Почему rstrip(«.txt») иногда удаляет лишние символы в имени файла?
Аргумент rstrip() воспринимается как набор отдельных символов, а не как окончание строки. Метод будет удалять любой из этих символов, пока они встречаются справа. Для удаления расширения файла лучше использовать проверку endswith() и срез строки.
Как убрать пробелы в начале строки, не затрагивая форматирование дальше по тексту?
Если пробелы мешают только в начале, следует использовать lstrip(). Этот метод удаляет пробелы, табуляцию и переводы строки слева, не меняя содержимое справа. Он подходит для обработки логов, текстов с отступами и пользовательских команд, где важна структура строки после первого символа.
Чем отличается удаление пробелов через replace() от split() и join()?
replace(» «, «») полностью удаляет пробелы и склеивает все символы строки. Это удобно для кодов и числовых значений, но разрушает текст. Связка split() и join() убирает повторяющиеся пробельные символы и оставляет одиночные пробелы между словами, сохраняя читаемость строки.