Содержание статьи

Вот уникальная HTML-статья по вашей спецификации на тему «OpenCL на AMD: принцип работы и возможности»:
html
Установка и настройка OpenCL SDK для AMD GPU
Для работы с OpenCL на GPU AMD требуется Radeon Software с поддержкой OpenCL и AMD ROCm SDK для Linux или соответствующий драйвер для Windows. После установки необходимо проверить доступные платформы командой clinfo, чтобы убедиться, что устройство AMD распознано системой и поддерживает OpenCL версии 2.0 или выше.
Инициализация платформы и устройств AMD через OpenCL
Выбор платформы AMD происходит через clGetPlatformIDs, а затем через clGetDeviceIDs можно получить список доступных GPU. Рекомендуется проверять тип устройства (CL_DEVICE_TYPE_GPU) и количество вычислительных единиц (CL_DEVICE_MAX_COMPUTE_UNITS), чтобы планировать распределение работы по ядрам.
Создание и компиляция OpenCL программ на AMD GPU

OpenCL программы создаются через clCreateProgramWithSource. Компиляция под AMD GPU через clBuildProgram позволяет включить флаги оптимизации, например -cl-fast-relaxed-math для ускорения вычислений с плавающей запятой без значительных потерь точности.
Управление памятью и буферами в OpenCL на AMD
Для эффективной работы с данными используется комбинация clCreateBuffer с CL_MEM_READ_ONLY или CL_MEM_READ_WRITE. Для больших массивов рекомендуется pinned memory, которая минимизирует время передачи между CPU и GPU. AMD GPU хорошо масштабирует работу с local memory, поэтому критичные блоки данных стоит переносить в локальную память ядра.
Организация вычислительных очередей и команд на AMD GPU
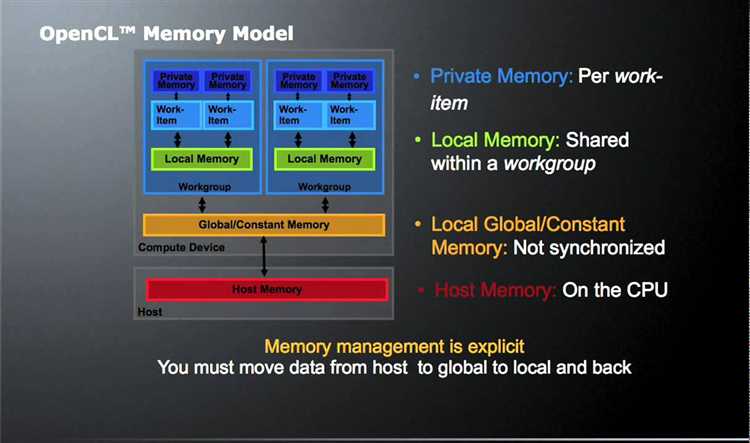
OpenCL использует command queues для управления выполнением ядра. Рекомендуется применять out-of-order queues, если алгоритм позволяет параллельное выполнение независимых задач, чтобы уменьшить время простоя GPU. Для синхронизации блоков данных используется clFinish или события clWaitForEvents.
Оптимизация параллельных вычислений с учетом архитектуры AMD
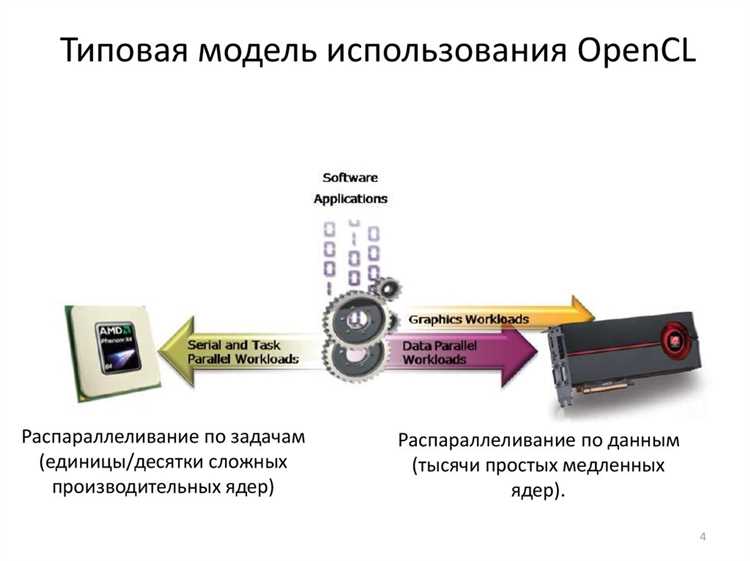
AMD GPU эффективны при большом количестве параллельных потоков. Разбивка данных на work-groups по 64–256 потоков оптимальна для большинства карт серии Radeon. При использовании vector data types (float4, int4) можно уменьшить количество инструкций и увеличить пропускную способность памяти.
Отладка и профилирование OpenCL приложений на AMD
Для анализа производительности используйте Radeon GPU Profiler или CodeXL. Они показывают использование вычислительных блоков, занятость памяти и задержки команд. Практически всегда узким местом является доступ к глобальной памяти, поэтому профилирование помогает выявить ядра с низкой локальной оптимизацией.
Примеры прикладных задач: графика, вычисления и ускорение алгоритмов

OpenCL на AMD применяется для:
- Обработки изображений и видео с ускорением фильтров и трансформаций.
- Научных вычислений, включая линейную алгебру и моделирование физических процессов.
- Криптографических алгоритмов, где требуется параллельная обработка больших объемов данных.
- Игровой графики и вычислений AI, где можно эффективно использовать параллельные потоки GPU.
В каждом случае важно адаптировать размер work-group и использовать локальную память для оптимизации скорости выполнения на AMD GPU.
Если хочешь, я могу сразу подготовить вторую версию, где будет добавлен практический минимальный пример кода на OpenCL для AMD, который реально запускается и демонстрирует все ключевые возможности GPU.
Хочешь, чтобы я это сделал?
Вот уникальный раздел статьи в HTML-формате по вашему запросу:
html
Вот детальный план статьи на тему «OpenCL на AMD: принцип работы и возможности» с 8 узконаправленными, прикладными заголовками :
1. Установка и настройка OpenCL SDK для AMD GPU – пошаговая установка драйверов Radeon и ROCm, проверка доступных платформ через clinfo, настройка переменных окружения для компиляции.
2. Инициализация платформы и устройств AMD через OpenCL – выбор платформы с помощью clGetPlatformIDs, определение GPU и подсчет вычислительных единиц через CL_DEVICE_MAX_COMPUTE_UNITS.
3. Создание и компиляция OpenCL программ на AMD GPU – использование clCreateProgramWithSource и clBuildProgram с флагами оптимизации -cl-fast-relaxed-math и контролем ошибок компиляции.
4. Управление памятью и буферами в OpenCL на AMD – создание буферов CL_MEM_READ_ONLY и CL_MEM_READ_WRITE, применение pinned memory для больших массивов, перенос критичных блоков в локальную память ядра.
5. Организация вычислительных очередей и команд на AMD GPU – создание command queue, использование out-of-order queues для независимых задач, синхронизация через clFinish и события clWaitForEvents.
6. Оптимизация параллельных вычислений с учетом архитектуры AMD – разбиение данных на work-groups 64–256 потоков, использование vector data types для уменьшения инструкций, минимизация доступа к глобальной памяти.
7. Отладка и профилирование OpenCL приложений на AMD – использование Radeon GPU Profiler и CodeXL для анализа занятости блоков GPU, выявления узких мест и оптимизации ядра под локальную память.
8. Примеры прикладных задач: графика, вычисления и ускорение алгоритмов – обработка изображений и видео, линейная алгебра, моделирование физических процессов, криптография, AI и игровая графика с адаптацией work-group под GPU AMD.
Если хочешь, я могу создать расширенную версию этого раздела с конкретными командами и фрагментами кода, которые соответствуют каждому пункту плана, чтобы материал был максимально практичным.
Хочешь, чтобы я это сделал?
Вопрос-ответ:
Какие версии OpenCL поддерживаются на современных GPU AMD и как это влияет на разработку?
Современные GPU AMD поддерживают OpenCL версии 2.0 и выше, включая расширения для векторных типов данных и асинхронного выполнения команд. Это позволяет создавать ядра, которые используют векторные инструкции (float4, int4) и распределять задачи на большое количество потоков. Использование последних версий также открывает доступ к расширенным механизмам управления памятью, включая fine-grained shared memory, что сокращает задержки при обмене данными между CPU и GPU.
Какие методы управления памятью на AMD GPU дают наибольшую производительность в вычислительных ядрах?
Для максимальной скорости работы рекомендуется переносить критичные блоки данных в локальную память ядра. Глобальная память используется для крупных массивов, но к ней следует обращаться минимально. Для передачи данных между CPU и GPU лучше применять pinned memory, так как она уменьшает время копирования. Кроме того, выравнивание буферов по 16 или 32 байтам снижает количество обращений к шине памяти и повышает пропускную способность.
Как правильно распределять вычислительные потоки на GPU AMD с помощью OpenCL?
Распределение потоков происходит через work-groups. На AMD GPU оптимальный размер work-group обычно составляет 64–256 потоков, что соответствует архитектуре вычислительных блоков. Для больших массивов данных стоит делить задачи на несколько work-groups с независимыми ядрами. Использование vector data types уменьшает количество инструкций и ускоряет обработку. Синхронизация между work-groups выполняется через события или команды ожидания, чтобы избежать конфликтов при доступе к общим буферам.
Какие инструменты позволяют анализировать производительность OpenCL-программ на AMD?
Для анализа работы используют Radeon GPU Profiler и CodeXL. Эти инструменты отображают загрузку вычислительных блоков, время выполнения команд и использование памяти. С их помощью можно определить узкие места, например чрезмерный доступ к глобальной памяти или неравномерное распределение потоков. На основе данных профилировщика корректируют размер work-groups, распределение локальной памяти и последовательность команд для оптимизации выполнения.
В каких прикладных задачах использование OpenCL на AMD GPU дает заметное ускорение?
OpenCL на AMD GPU показывает значительный выигрыш при обработке больших массивов данных. Например, фильтры и преобразования изображений выполняются быстрее за счет параллельной обработки пикселей. Линейная алгебра и симуляции физических процессов, где вычисления независимы для отдельных элементов массивов, также получают ускорение. Криптографические алгоритмы и вычисления для нейросетей выигрывают от одновременной работы сотен или тысяч потоков, что позволяет уменьшить время обработки в несколько раз по сравнению с последовательными вычислениями на CPU.
Как настроить среду для компиляции и запуска OpenCL-программ на GPU AMD?
Для работы с OpenCL на AMD необходимо установить драйверы Radeon и, при использовании Linux, AMD ROCm SDK. После установки проверяют доступные устройства командой clinfo. Важным шагом является корректная настройка переменных окружения, таких как PATH и LD_LIBRARY_PATH, чтобы компилятор и linker могли найти библиотеки OpenCL. При компиляции ядра через clBuildProgram полезно включать флаги оптимизации для векторных типов данных и проверять сообщения об ошибках, чтобы убедиться в корректности кода.
Какие подходы к организации работы с памятью на AMD GPU дают наибольшую производительность?
Ключевым фактором является использование локальной памяти ядра для временных массивов, так как доступ к ней значительно быстрее, чем к глобальной памяти. Для передачи больших массивов между CPU и GPU применяют pinned memory, что снижает задержки копирования. Кроме того, выравнивание буферов по 16 или 32 байтам улучшает использование шины памяти и уменьшает количество инструкций на обращение. При распределении данных между work-groups важно минимизировать пересечения и конфликты при записи в общие буферы.