Содержание статьи

В JavaScript подсчет символов в строке осуществляется напрямую через свойство length. Оно возвращает целое число, соответствующее количеству символов, включая пробелы, спецсимволы и невидимые управляющие символы. Например, строка «Привет, мир!» имеет длину 12, так как учитываются все буквы, запятая, пробел и восклицательный знак.
При работе с пользовательским вводом важно учитывать не только видимые символы, но и переносы строк, табуляцию и пробелы в начале и конце строки. Методы trim() и регулярные выражения позволяют исключать лишние символы и корректно оценивать количество значимых символов, что особенно актуально для валидации форм.
Для подсчета конкретных символов или групп символов удобно использовать методы split() или match() с регулярными выражениями. Например, подсчет всех вхождений буквы «а» в тексте можно выполнить с помощью str.match(/а/g).length, что позволяет быстро анализировать тексты без ручного перебора.
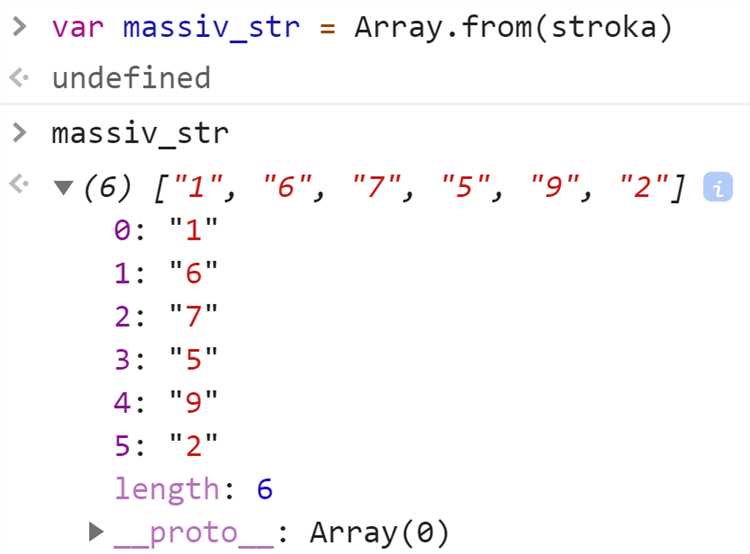
При работе с Unicode стоит помнить, что некоторые символы, такие как эмодзи или сложные иероглифы, могут занимать более одного кода UTF-16. В таких случаях стандартное свойство length возвращает число кодовых единиц, а не реальных символов. Для корректного подсчета используют методы Array.from() или for…of для обхода строки по реальным символам.
Использование свойства length для подсчета символов
Свойство length в JavaScript возвращает количество кодовых единиц UTF-16 в строке. Для строки «JavaScript» значение будет 10, так как каждый символ занимает одну кодовую единицу. Оно учитывает все символы, включая пробелы, знаки препинания и специальные символы, например, \n или \t.
Применение length особенно полезно для быстрой проверки длины строки при валидации данных формы. Например, чтобы ограничить ввод имени до 20 символов, можно использовать условие if (input.value.length > 20). Это исключает необходимость ручного перебора всех символов.
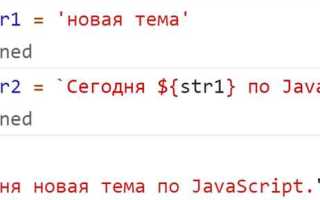
Для динамических строк свойство length обновляется автоматически при изменении значения переменной. Если присвоить строке новое значение, str = «новый текст», str.length сразу вернет актуальное число символов, что упрощает обработку ввода и подсчет данных без дополнительных функций.
При анализе текста с нестандартными символами или эмодзи стоит учитывать, что length считает кодовые единицы, а не визуальные символы. Для большинства латинских и кириллических символов этого достаточно, но для корректного подсчета сложных Unicode-символов рекомендуется использовать методы Array.from() или оператор for…of.
Учет пробелов и спецсимволов в строке
В JavaScript пробелы, табуляции и переносы строк считаются полноценными символами при использовании свойства length. Например, строка «Привет \n мир» имеет длину 12, так как символ переноса строки \n учитывается наряду с буквами и пробелами.
Для подсчета значимых символов часто применяют метод trim(), который удаляет пробелы в начале и конце строки. После вызова str.trim().length результат отражает только внутренние символы и пробелы между словами, что важно при проверке ввода пользователем.
Спецсимволы, такие как \t, \r или невидимые управляющие символы, также влияют на длину строки. Их можно исключить с помощью регулярных выражений: str.replace(/\s/g, »).length подсчитает количество символов без пробелов, табуляций и переносов строк.
При анализе текста для статистики или ограничения ввода рекомендуется явно учитывать пробелы и спецсимволы, так как они могут значительно увеличить длину строки. Это особенно важно для многострочных текстов и форм с ограничением символов.
Подсчет символов без учета пробелов

Для подсчета символов без пробелов в JavaScript удобно использовать метод replace() с регулярным выражением /\s/g. Оно удаляет все пробельные символы, включая пробелы, табуляции и переносы строк. Например, ‘Привет мир’.replace(/\s/g, »).length вернет 10 вместо 11.
Если требуется исключить только обычные пробелы, можно использовать str.replace(/ /g, »), сохраняя переносы строк и табуляцию. Это полезно при анализе текстов, где важна структура абзацев, но пробелы между словами учитывать не нужно.
Метод split() также применим: str.split(‘ ‘).join(»).length вернет длину строки без пробелов. Этот способ удобен, когда необходимо одновременно преобразовать текст и подсчитать символы.
Для динамического ввода форм рекомендуется подсчитывать символы без пробелов при каждой смене значения поля. Это позволяет точно контролировать ограничения на количество значимых символов и предотвращает ошибки при валидации текстовых данных.
Определение количества определенного символа
Для подсчета конкретного символа в строке удобно использовать метод match() с регулярным выражением. Например, str.match(/а/g) возвращает массив всех вхождений буквы «а». Чтобы получить количество, достаточно обратиться к length: str.match(/а/g)?.length || 0. Оператор ?. защищает от ошибок, если символов нет.
Альтернативный метод – перебор символов с помощью цикла for…of и счетчика. Это позволяет учитывать условия, например, различие между верхним и нижним регистром, или исключать спецсимволы.
Регулярные выражения поддерживают модификатор i для игнорирования регистра: str.match(/a/gi) подсчитает все вхождения «a» и «A». Для поиска нескольких символов можно использовать класс символов: str.match(/[aeiou]/gi) возвращает количество всех гласных.
Подсчет символов в многострочном тексте
В многострочном тексте каждый символ переноса строки учитывается свойством length как отдельный символ. Для точного анализа важно различать пробельные символы и переносы строк.
Для обработки многострочного текста можно использовать следующие подходы:
- Удаление всех пробелов и переносов строк: str.replace(/\s/g, »).length возвращает количество только видимых символов.
- Подсчет символов каждой строки отдельно: str.split(‘\n’).map(line => line.length) формирует массив длин всех строк.
- Игнорирование табуляции и пробелов в начале и конце строк: str.split(‘\n’).map(line => line.trim().length) учитывает только содержимое текста.
При работе с textarea или многострочными блоками важно учитывать, что браузеры могут использовать разные символы переноса строки (\r\n или \n). Для унификации текста перед подсчетом рекомендуется применять str.replace(/\r\n/g, ‘\n’).
Если необходимо подсчитать определенные символы в каждой строке, комбинация split() и match() позволяет получать массив с количеством вхождений по строкам: str.split(‘\n’).map(line => (line.match(/а/g) || []).length).
Работа с Unicode и эмодзи при подсчете
Стандартное свойство length в JavaScript возвращает количество кодовых единиц UTF-16, а не реальных символов. Это важно при работе с эмодзи и сложными Unicode-символами, которые могут занимать две кодовые единицы. Например, ‘😊’.length вернет 2, хотя визуально символ один.
Для корректного подсчета всех символов используют Array.from(): Array.from(str).length возвращает реальное количество символов, включая эмодзи и комбинированные символы.
Аналогично, можно использовать цикл for…of для итерации по реальным символам: каждый проход цикла соответствует одному визуальному символу, что позволяет подсчитывать и обрабатывать Unicode-тексты без искажений.
При подсчете конкретных символов с учетом Unicode следует использовать регулярные выражения с флагом u: str.match(/./gu).length подсчитает все символы корректно, включая многобайтовые и комбинированные символы.
Подсчет символов в пользовательском вводе формы
При работе с формами важно отслеживать количество символов в полях ввода для контроля лимитов и валидации. В JavaScript это делается через свойство value элемента формы и стандартное length.
Примеры подходов:
- Подсчет общей длины текста: input.value.length возвращает количество символов, включая пробелы и спецсимволы.
- Подсчет без пробелов: input.value.replace(/\s/g, »).length исключает все пробельные символы, полезно для проверки содержания.
- Подсчет конкретных символов: (input.value.match(/@/g) || []).length позволяет ограничивать количество определенных знаков, например, символов «@» в email.
Для динамического контроля рекомендуется использовать обработчик события input:
- Подключить событие к полю: input.addEventListener(‘input’, callback).
- Внутри callback подсчитывать символы с помощью length или регулярных выражений.
- Отображать пользователю количество введенных символов или предупреждать при превышении лимита.
Такой подход позволяет предотвращать ошибки ввода, корректно обрабатывать Unicode-символы и эмодзи, а также применять ограничения на количество значимых символов без лишних вычислений.
Сравнение длины строк и проверка лимитов

В JavaScript длину строки получают через свойство length, которое возвращает количество кодовых единиц UTF-16. Для проверки ограничения на ввод, например 100 символов, используют условие: if (str.length > 100).
Если необходимо учитывать только значимые символы без пробелов и переносов строк, применяют str.replace(/\s/g, »).length. Это особенно важно для полей форм, где лимит задается по фактическому содержимому.
Для корректного контроля длины текста с эмодзи и сложными Unicode-символами применяют Array.from(str).length. Такой метод возвращает количество визуальных символов, предотвращая ошибки при ограничении ввода.
При работе с формами рекомендуется использовать события input для динамической проверки. Это позволяет обновлять счетчик символов и предотвращать превышение лимита до отправки данных.
Вопрос-ответ:
Как правильно подсчитать количество эмодзи в строке?
Свойство length возвращает количество кодовых единиц UTF-16, поэтому один эмодзи может считаться за два символа. Для точного подсчета используйте Array.from(str).length, которое формирует массив из визуальных символов, включая эмодзи. Альтернативно можно применить цикл for…of, где каждый проход цикла соответствует одному символу, что позволяет корректно учитывать многобайтовые и комбинированные символы.
Можно ли подсчитать только буквы в строке, игнорируя пробелы и цифры?
Да, для этого используют регулярные выражения. Например, str.match(/[а-яА-Яa-zA-Z]/g).length вернет количество букв в строке, игнорируя пробелы, цифры и спецсимволы. Если в строке нет букв, результат будет undefined, поэтому стоит добавить проверку через || 0 для корректного вывода нуля.
Как подсчитать символы в многострочном тексте и при этом исключить пробелы в начале и конце строк?
Можно разбить текст на массив строк с помощью split(‘\n’), затем применить trim() к каждой строке и посчитать длину: str.split(‘\n’).map(line => line.trim().length). Такой подход позволяет получить длину каждой строки без лишних пробелов, сохранив переносы между абзацами для анализа структуры текста.
Как ограничить ввод в текстовое поле по количеству символов с учетом эмодзи и спецсимволов?
Стандартное length может неверно подсчитывать эмодзи, поэтому используют Array.from(input.value).length для подсчета визуальных символов. Далее в обработчике события input проверяют результат: если количество превышает лимит, можно обрезать строку или показать предупреждение. Такой метод работает корректно для букв, цифр, пробелов, спецсимволов и эмодзи одновременно.