Содержание статьи

Архитектуры семейства CISC создавались для выполнения разнородных инструкций, включая команды со сложной адресацией и расширенными форматами операндов. В основе лежит подход, при котором одна инструкция способна объединять несколько действий: чтение данных, вычисление адреса, арифметику и запись результата. Такой набор возможностей требует развитой системы декодирования и микрокода, определяющего пошаговую логику выполнения.
Большая часть современных CISC-процессоров использует микропрограммы, позволяющие преобразовывать многосоставные инструкции в последовательность внутренних операций. Это снижает требования к компилятору, но увеличивает нагрузку на блок декодирования и систему управления. При планировании нагрузки на процессор стоит учитывать, что длительные инструкции могут занимать несколько тактов и временно удерживать исполнительные узлы.
Для практического применения архитектуры важны сведения о пределах пропускной способности при работе с длинными командами, правила использования разных режимов адресации и влияние размера кода на размещение программ в памяти. Разработчику полезно анализировать реальные профили выполнения: частоту обращений к сложным инструкциям, стоимость переходов между микрокодовыми последовательностями и поведение кэшей при смешанном наборе команд.
Ключевые признаки CISC и их влияние на набор команд
Архитектуры класса CISC характеризуются расширенными форматами инструкций, высокой вариативностью адресации и возможностью объединять несколько операций в одной команде. Такая структура влияет на декодирование, объём кода и взаимодействие с памятью, что важно учитывать при проектировании низкоуровневой логики и разработке компиляторов.
Набор команд CISC включает длинные инструкции со встроенными операциями вычисления адреса, чтения данных и последующей обработки. Это упрощает генерацию кода для сложных выражений, однако повышает нагрузку на блок управления, который должен анализировать многообразие форматов и преобразовывать их во внутренние микрооперации.
| Признак | Практическое влияние |
|---|---|
| Многоформатные инструкции | Увеличение декодирующей логики и вариативности генерации кода |
| Развитые режимы адресации | Сокращение количества команд при обработке структур данных |
| Микрокодовое исполнение | Гибкость добавления новых инструкций без изменения аппаратной части |
| Длинный машинный код | Повышенная нагрузка на кэш инструкций и планирование размещения программы |
При выборе инструкций для критичных участков алгоритма имеет смысл оценивать длину конкретной команды, количество задействованных тактов и влияние на конвейер. Использование слишком громоздких операций может увеличивать задержки, поэтому разработчику стоит сопоставлять функциональность инструкции с реальными ограничениями по времени выполнения.
Принцип микрокода и его роль в выполнении сложных инструкций
Микрокод определяет последовательность внутренних операций, необходимых для выполнения инструкций с расширенной логикой. Каждая сложная команда разбивается на микрооперации, которые взаимодействуют с регистровым файлом, арифметико-логическим блоком и узлами доступа к памяти. Такой подход позволяет поддерживать широкие форматы команд без изменения основной схемотехники.
Микропрограмма хранится в специализированном ПЗУ или перезаписываемой памяти, что даёт возможность обновлять алгоритмы выполнения отдельных инструкций и корректировать поведение процессора. При запуске сложной команды блок управления считывает соответствующую последовательность микроопераций и формирует сигналы для исполнительных узлов.
- Инструкции с несколькими операндами получают собственные цепочки микроопераций, включающие вычисление адреса и подготовку данных.
- Редко используемые команды обрабатываются через длинные микрокодовые фрагменты, что уменьшает требования к аппаратным схемам.
- Обновление микропрограмм позволяет адаптировать поведение процессора под новые компиляторы или исправлять обнаруженные ошибки.
При создании производительного кода полезно оценивать частоту вызовов команд, которые опираются на глубокие микрокодовые последовательности. Избыточные обращения к ним могут увеличивать время выполнения, поэтому разработчику стоит выбирать инструкции, соотнося их функциональность с возможной длиной микропрограммы.
Последовательность декодирования команд в CISC-процессорах
Декодирование в CISC-процессорах начинается с определения длины инструкции, поскольку формат может включать префиксы, байты модификаторов, поля адресации и дополнительные операнды. Блок извлечения должен корректно выделить границы команды, чтобы избежать смещения и неверного чтения последующих байтов.
После определения длины осуществляется анализ полей операций и режимов адресации. Процессор сопоставляет комбинацию бит с таблицей опкодов, выясняя, требуется ли доступ к памяти, используются ли регистры общего назначения и требуется ли вычисление эффективного адреса. На этом этапе формируются управляющие сигналы для блоков вычисления адреса и подачи запросов в кэш данных.
Следующий шаг – разбиение инструкции на микрооперации. Если команда сложная, процессор обращается к микропрограмме. При наличии простой инструкции она преобразуется в минимальное количество внутренних шагов, которые могут быть помещены в очередь исполнения. Это снижает задержки при обработке коротких последовательностей команд.
При проектировании низкоуровневой логики критичных участков кода рекомендуется учитывать объём декодирования. Инструкции с большим числом дополнительных полей увеличивают нагрузку на блок анализа и могут вызывать временные остановки конвейера, поэтому их следует использовать только при необходимости, когда выигрыш в сокращении числа команд действительно оправдан.
Организация работы блоков выполнения при длинных инструкциях
Длинные инструкции требуют поэтапного распределения нагрузки между арифметическими узлами, блоком вычисления адреса и модулем доступа к памяти. Процессор формирует очередь микроопераций, каждая из которых занимает определённый исполнительный блок. Это позволяет поддерживать предсказуемое продвижение по конвейеру даже при сложной структуре команды.
Для управления такими последовательностями используются внутренние маркеры готовности, которые фиксируют завершение отдельных микроопераций. Блоки исполнения синхронизируются через буферы, чтобы исключить конфликты за ресурсы при одновременном доступе к шине или регистрационным портам.
- Арифметические узлы получают только те микрооперации, которые не зависят от данных из последующих шагов.
- Блок вычисления адреса обрабатывает запросы заранее, чтобы уменьшить задержку перед обращением к памяти.
- Очередь памяти распределяет запросы с учётом того, какой микрооперации требуется чтение или запись.
- Контроль зависимостей предотвращает запуск микроопераций, использующих ещё не готовые данные.
Для повышения пропускной способности кода разработчику стоит учитывать, что последовательности длинных инструкций могут занимать исполнительные блоки дольше обычного. При составлении критичных участков алгоритма полезно оценивать, какие микрооперации будут лежать в цепочке и не приведут ли они к блокировкам других потоков данных.
Как многотактное исполнение влияет на структуру конвейера
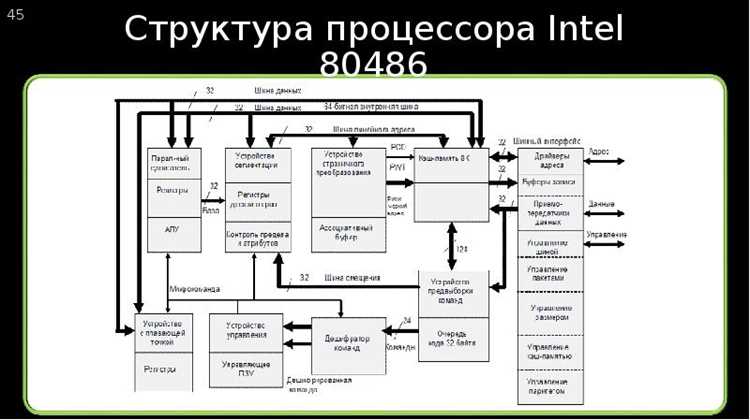
Многотактное исполнение нарушает равномерность продвижения команд по конвейеру, поскольку отдельные микрооперации могут занимать исполнительные блоки дольше одного такта. Конвейер вынужден согласовывать работу фаз так, чтобы не возникало конфликтов между командами, ожидающими завершения предыдущих этапов.
При обработке длинных инструкций процессор создаёт временные точки остановки, где дальнейшее продвижение ограничено готовностью данных. Это влияет на расчёт глубины конвейера: слишком глубокая структура увеличивает риск накопления задержек, а недостаточная глубина снижает пропускную способность при большом числе коротких команд.
Для минимизации задержек процессоры используют буферизацию микроопераций и переупорядочивание шагов, не зависящих от данных предыдущих операций. Такой подход позволяет заполнять простои и частично компенсировать длительность выполнения отдельных этапов.
Разработчику полезно оценивать, вызовет ли выбранная инструкция избыточное количество остановок конвейера. В критичных участках кода лучше избегать команд, требующих длительных последовательностей внутренних шагов, так как они увеличивают вероятность временных блокировок исполнительных узлов.
Стратегии оптимизации памяти команд в CISC-архитектуре
В CISC-процессорах инструкции могут иметь разную длину, что создаёт разнородность в расположении команд в памяти. Для сокращения объёма кода используют упрощённые варианты часто вызываемых инструкций и комбинируют короткие операции с макрокомандами, которые объединяют несколько микроопераций.
Для ускорения доступа применяются кэш-инструкции и буферизация последовательностей команд. Буферы позволяют хранить наиболее часто используемые команды, снижая количество обращений к основной памяти. При этом структура кэша учитывает вариативность длины инструкций, чтобы избежать частичных попаданий и конфликтов в блоках хранения.
Компиляторы для CISC-систем используют выравнивание инструкций и минимизацию префиксов, чтобы уменьшить фрагментацию кода. Также применяются стратегии повторного использования коротких инструкций в циклах, что сокращает объём памяти и повышает скорость выполнения.
При проектировании критичных программных участков рекомендуется анализировать распределение длинных и коротких инструкций, оценивать их влияние на кэш и использовать макрокоманды только там, где сокращение числа операций оправдано с точки зрения общей производительности.
Подходы к обработке адресации в многоформатных инструкциях

Многоформатные инструкции CISC поддерживают прямую, косвенную, регистровую и базово-индексную адресацию. Процессор анализирует поля операндов для определения способа получения данных и расчёта эффективного адреса, что критично для точного доступа к памяти и регистрам.
Для ускорения вычисления адреса используют отдельные блоки, которые заранее формируют смещения и индексы. При комбинировании нескольких методов адресации создаются микрооперации, последовательно подготавливающие все элементы адреса для последующего чтения или записи.
В системах с микрокодовым управлением часть инструкций разбивается на этапы: сначала вычисляется адрес, затем извлекаются данные, и только после этого выполняется основная операция. Такой подход минимизирует ошибки при сложных комбинациях форматов и позволяет оптимально распределять нагрузку между исполнительными блоками.
Разработчику важно учитывать, какие режимы адресации чаще всего используются в критичных циклах программы. Для повышения производительности стоит отдавать предпочтение прямой и регистровой адресации там, где возможно, и применять сложные методы только для редких случаев или операций с большими структурами данных.
Сравнение поведения CISC-ядер в реальных вычислительных сценариях
CISC-ядерные процессоры демонстрируют различную эффективность в зависимости от структуры инструкций и характера нагрузки. В приложениях с большим количеством коротких операций наблюдается высокий уровень простоя блоков декодирования из-за необходимости обработки длинных команд, что снижает пропускную способность конвейера.
При работе с интенсивными вычислительными задачами, где преобладают сложные инструкции с множеством операндов, CISC-ядра показывают преимущество: уменьшение числа машинных команд сокращает обращения к памяти и количество циклов на подготовку данных. Однако это требует грамотного управления микрокодом и предвычисления адресов для предотвращения блокировок.
В системах реального времени важно учитывать время отклика на прерывания и переключение контекста, так как длинные инструкции могут задерживать обслуживание внешних событий. Оптимизация кода должна предусматривать использование более коротких команд для критичных участков и комбинирование сложных инструкций там, где сокращение числа операций оправдано.
Для анализа производительности рекомендуется профилировать код, определять частоту вызова сложных инструкций и оценивать их влияние на конвейер и кэш. Такая методика позволяет выбрать баланс между компактностью кода и временем выполнения, что критично для приложений с переменной нагрузкой.
Вопрос-ответ:
Что отличает CISC-процессоры от RISC в контексте набора команд?
CISC-процессоры имеют инструкции переменной длины, которые могут выполнять несколько действий за один цикл команды, включая вычисление адресов и доступ к памяти. Это позволяет уменьшить количество инструкций в программе, но требует более сложного блока декодирования и микрокода для преобразования команд в микрооперации. В отличие от RISC, где каждая команда выполняет одну операцию, CISC концентрируется на сокращении общего числа команд.
Как микрокод влияет на выполнение сложных инструкций в CISC?
Микрокод разбивает сложные команды на последовательность микроопераций, которые процессор может выполнять поэтапно. Это позволяет использовать одни и те же аппаратные блоки для разных инструкций, упрощает добавление новых команд и уменьшает требования к изменению схемотехники. Для разработчика это значит, что длинные инструкции могут занимать несколько тактов и влиять на планирование выполнения критичных участков кода.
Почему режимы адресации важны при работе с многоформатными инструкциями?
Многоформатные инструкции используют различные способы адресации, включая прямую, косвенную, регистровую и базово-индексную. Выбор метода влияет на количество тактов, необходимое для извлечения данных, и на нагрузку на вычислительные блоки. Оптимально применять более простые методы адресации для часто выполняемых операций и оставлять сложные режимы для редких случаев, когда требуется работа с большими структурами данных.
Какие ограничения накладывает многотактное исполнение на конвейер CISC-процессора?
Многотактное исполнение отдельных микроопераций удлиняет время прохождения команды через конвейер. Это создаёт точки ожидания, где последующие команды не могут продвинуться дальше, пока предыдущая микрооперация не завершена. Для уменьшения простоев используют буферы и переупорядочивание микроопераций, позволяющее параллельно выполнять независимые шаги и поддерживать стабильное заполнение конвейера.
Как оптимизировать использование памяти команд в CISC-процессорах?
Оптимизация памяти включает сокращение длины часто используемых инструкций, выравнивание кода и применение буферизации для кэширования последовательностей команд. Компилятор может комбинировать короткие операции в макрокоманды, чтобы уменьшить число обращений к памяти. В критичных участках следует анализировать распределение длинных и коротких инструкций, чтобы минимизировать влияние на кэш и скорость выполнения.
Почему CISC-процессоры используют переменную длину инструкций и как это влияет на производительность?
CISC-процессоры применяют инструкции переменной длины для того, чтобы одна команда могла выполнять несколько действий, включая вычисление адресов, арифметические операции и доступ к памяти. Это уменьшает количество команд в программе, но усложняет декодирование и планирование выполнения, так как процессор должен определять границы каждой инструкции и разбивать её на микрооперации. В реальных сценариях это позволяет сократить число обращений к памяти, но может увеличить простои конвейера, если используются длинные команды без учёта их длительности.