Содержание статьи

В Apache Kafka consumer group id определяет группу потребителей, которые совместно читают сообщения из одного топика. Каждое сообщение доставляется только одному потребителю внутри группы, что позволяет масштабировать обработку данных без дублирования.
Использование правильного group id критично для балансировки нагрузки. Если два потребителя имеют одинаковый group id, Kafka автоматически распределяет между ними партиции топика. При увеличении числа потребителей выше количества партиций некоторые потребители будут простаивать, что важно учитывать при проектировании систем с высоким трафиком.
Group id также влияет на хранение смещений (offsets). Kafka отслеживает, какие сообщения уже были прочитаны конкретной группой, обеспечивая устойчивость к сбоям и возможность продолжить обработку после перезапуска потребителя без потери данных.
При смене group id создается новая независимая группа, и все сообщения топика будут читаться с начала или с текущего смещения в зависимости от настроек. Это позволяет организовывать отдельные потоки обработки для разных бизнес-задач без влияния на существующие потребители.
Оптимальная настройка consumer group id требует учета количества партиций, скорости поступления сообщений и требуемой устойчивости к сбоям. Практика показывает, что для каждого топика лучше использовать несколько групп с осмысленными идентификаторами, чтобы управлять параллельной обработкой и архивированием данных без дублирования.
htmlKafka consumer group id: что означает и как работает
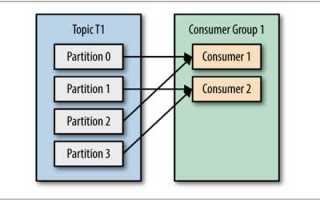
Consumer group id в Kafka служит уникальным идентификатором группы потребителей, которые совместно обрабатывают сообщения одного топика. Каждый потребитель в группе получает уникальные партиции, что исключает дублирование данных и позволяет масштабировать обработку при увеличении нагрузки.
Kafka использует group id для отслеживания offsets – позиции последнего прочитанного сообщения в партиции. При перезапуске потребителя с тем же group id система продолжает чтение с последнего зафиксированного смещения, обеспечивая непрерывность обработки без потери данных.
Если несколько потребителей используют один group id, Kafka распределяет партиции автоматически. При добавлении новых потребителей происходит перераспределение партиций между всеми участниками группы. При удалении потребителя его партиции перераспределяются среди оставшихся, что обеспечивает баланс нагрузки.
Смена или дублирование group id создаёт отдельную независимую группу, которая начинает чтение топика с начала или с настроенного смещения. Это позволяет создавать отдельные потоки обработки для разных задач без влияния на существующих потребителей.
Практическая рекомендация: для каждого критичного потока данных использовать отдельный, осмысленный group id, учитывать количество партиций при масштабировании и регулярно контролировать перераспределение нагрузок между потребителями для стабильной работы системы.
Определение consumer group id в Kafka
Использование одного group id несколькими потребителями позволяет Kafka делить партиции между ними, обеспечивая параллельную обработку без дублирования данных. Каждый потребитель в группе получает одну или несколько партиций, а Kafka автоматически перераспределяет их при добавлении или удалении участников.
Group id также отвечает за сохранение позиции чтения сообщений. Kafka фиксирует offset для каждой партиции и группы, что гарантирует возобновление обработки после перезапуска потребителя с того места, где она была прервана.
Рекомендация: давать group id осмысленные имена, отражающие назначение потока данных. Это облегчает мониторинг, отладку и управление масштабированием, особенно в системах с высокой нагрузкой и большим количеством топиков.
Роль consumer group id в распределении сообщений
Consumer group id определяет, каким образом сообщения топика распределяются между потребителями. Kafka гарантирует, что каждое сообщение доставляется только одному потребителю внутри группы, предотвращая дублирование обработки.
При наличии нескольких потребителей с одним group id партиции топика автоматически распределяются между ними. Если число потребителей меньше числа партиций, некоторые потребители получат несколько партиций. Если потребителей больше партиций, лишние потребители будут простаивать до перераспределения.
Перераспределение партиций происходит при добавлении или удалении потребителей, обеспечивая баланс нагрузки без ручного вмешательства. Kafka отслеживает offsets для каждой группы, что позволяет новым потребителям подхватывать поток с последнего зафиксированного сообщения.
Рекомендация: проектируя систему, учитывать количество партиций и group id для оптимальной параллельной обработки. Для критичных потоков создавать отдельные группы с уникальными идентификаторами, чтобы изменения в одной группе не влияли на обработку других.
Как Kafka использует group id для балансировки нагрузки

В Kafka group id служит ключом для распределения партиций топика между потребителями одной группы. Это позволяет равномерно распределять нагрузку и обеспечивать параллельную обработку сообщений.
Механизм балансировки работает следующим образом:
- Каждой партиции топика назначается один потребитель из группы.
- Если количество потребителей меньше числа партиций, некоторые потребители получают несколько партиций.
- Если потребителей больше партиций, лишние потребители остаются в ожидании перераспределения.
- При добавлении нового потребителя Kafka автоматически перераспределяет партиции между всеми участниками группы.
- При отключении потребителя его партиции перераспределяются между оставшимися, сохраняя баланс нагрузки.
Рекомендации по использованию:
- Сопоставлять количество потребителей с числом партиций для равномерной обработки.
- Использовать уникальные group id для независимых потоков обработки.
- Регулярно мониторить перераспределение партиций при масштабировании группы, чтобы избегать простаивания потребителей.
Разница между уникальными и одинаковыми group id
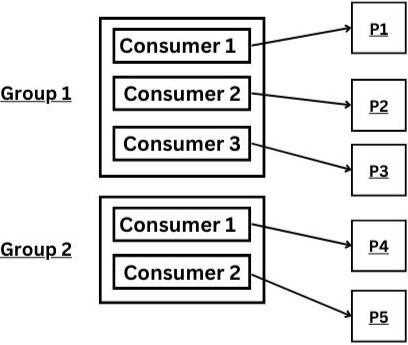
В Kafka group id определяет, как сообщения топика распределяются между потребителями. Разница между уникальными и одинаковыми идентификаторами влияет на обработку и хранение offsets.
| Тип group id | Поведение Kafka | Применение |
|---|---|---|
| Одинаковые group id | Все потребители одной группы получают разные партиции, сообщения не дублируются, offsets хранятся для группы | Параллельная обработка данных, балансировка нагрузки, масштабирование потребителей |
| Уникальные group id | Каждый потребитель считается отдельной группой, получает все сообщения топика, offsets отслеживаются независимо | Создание независимых потоков обработки, повторная обработка сообщений, аналитика без влияния на основную группу |
Рекомендации:
- Использовать одинаковые group id для распределенной обработки и увеличения пропускной способности.
- Использовать уникальные group id для независимых потоков, тестирования или повторного анализа данных.
- Следить за количеством потребителей и партиций, чтобы минимизировать простаивание или дублирование сообщений.
Writing
Настройка consumer group id в конфигурации клиента
Consumer group id указывается в конфигурации Kafka consumer и определяет принадлежность клиента к определённой группе. Каждый consumer в одной группе получает уникальные партиции топиков, что обеспечивает распределение нагрузки.
Для Java-клиента значение задаётся через свойство group.id:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "my-consumer-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Для Python (kafka-python) используется параметр group_id при создании объекта KafkaConsumer:
consumer = KafkaConsumer('my-topic',
bootstrap_servers='localhost:9092',
group_id='my-consumer-group',
auto_offset_reset='earliest')
Важно выбирать уникальные идентификаторы для разных групп, чтобы избежать пересечения обработки сообщений. Изм
Writing
Поведение Kafka при смене или дублировании group id
Дублирование group.id для нескольких consumer приводит к перераспределению партиций между всеми участниками группы. Каждая партиция назначается только одному consumer в группе, остальные остаются простаивать до перераспределения.
При одновременном подключении нескольких consumer с одинаковым group.id происходит rebalance. Этот процесс временно приостанавливает обработку сообщений на всех consumer, пока Kafka распределяет партиции.
Рекомендации: использовать уникальные идентификаторы для логически независимых процессов, избегать частой смены group.id без необходимости, контролировать настройки session.timeout.ms и max.poll.interval.ms для минимизации задержек при rebalance.
Для мониторинга активности групп применяются команды kafka-cons
Writing
Практические примеры использования consumer group id
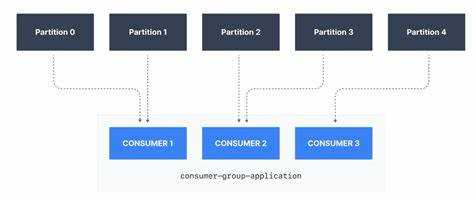
Consumer group id позволяет организовать параллельную обработку сообщений и управлять потоками данных в Kafka. Основные примеры применения:
- Многопоточная обработка: несколько consumer с одинаковым
group.idраспределяют партиции топика, увеличивая производительность. Например, топик с 6 партициями обрабатывается тремя consumer, каждый получает по две партиции. - Разделение бизнес-логики: разные сервисы используют отдельные
group.id, чтобы независимые процессы не влияли на смещения друг друга. Например, аналитический сервис и сервис уведомлений читают один топик через разные группы. - Обработка повторов и восстановление: смена
group.idпозволяет повторно обработать исторические сообщения без вмешательства в текущие группы. - Мониторинг и отладка: отдельная тестовая группа с уникальным
group.idпозволяет проверять работу consumer без воздействия на рабочие процессы.
Рекомендации:
Consumer group id — это уникальный идентификатор группы потребителей сообщений из Kafka. Он позволяет нескольким потребителям совместно читать данные из одного топика, распределяя партиции между собой. Благодаря этому каждая запись обрабатывается только одним потребителем внутри группы, что обеспечивает масштабирование и балансировку нагрузки. Когда несколько потребителей принадлежат одной группе, Kafka распределяет партиции топика между ними. Если новых потребителей становится больше, партиции перераспределяются. Если потребителей меньше, некоторые партиции остаются закреплёнными за существующими участниками. Таким образом, group id определяет границы распределения данных внутри группы. Да, можно, но с ограничениями. Если разные приложения используют один и тот же group id, Kafka будет считать их частью одной группы и распределять партиции между всеми экземплярами. Это может вызвать непредсказуемое распределение сообщений и пересечение обработки, если приложения ожидают полный поток данных. Обычно для разных приложений используют разные group id. Kafka распределит партиции топика между этими двумя потребителями. Каждый потребитель получит уникальный набор партиций, так что одно сообщение не будет обработано одновременно двумя потребителями. Если один из потребителей отключится, Kafka перераспределит его партиции оставшимся участникам группы. Для изменения consumer group id необходимо остановить потребителя, внести изменения в конфигурацию и перезапустить его с новым идентификатором. Новый group id создаст отдельную группу, и потребитель начнет читать данные независимо от предыдущей группы. При этом старые смещения (offsets) не будут использоваться, если не настроено сохранение offset для нового идентификатора. Consumer group id определяет принадлежность потребителя к определённой группе. Kafka распределяет партиции топика между всеми участниками группы, так что каждое сообщение обрабатывается только одним потребителем внутри этой группы. Это позволяет масштабировать обработку данных: добавление новых потребителей автоматически перераспределяет партиции, а удаление участников возвращает их партиции оставшимся потребителям. Да, один топик может одновременно обслуживаться несколькими группами потребителей. Каждая группа с уникальным consumer group id будет получать полный поток сообщений независимо от других групп. Это позволяет разным сервисам обрабатывать одни и те же данные по своим правилам, не мешая работе друг друга.Вопрос-ответ:
Что такое consumer group id в Kafka и зачем он нужен?
Как consumer group id влияет на распределение партиций между потребителями?
Можно ли использовать один consumer group id для нескольких приложений?
Что произойдет, если два потребителя с одинаковым group id подключатся к одному топику?
Как изменить consumer group id для уже работающего потребителя?
Как consumer group id влияет на обработку сообщений в Kafka?
Можно ли иметь несколько групп потребителей с одним и тем же топиком?