Содержание статьи

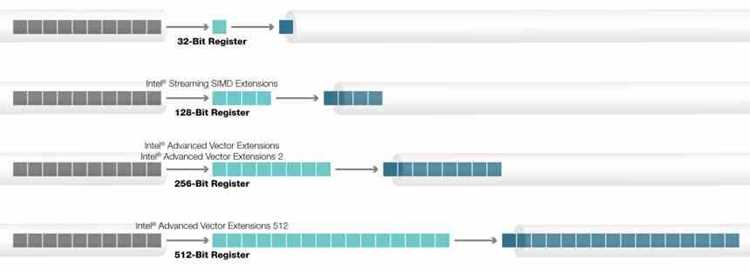
AVX-512 – набор команд процессора, разработанный для обработки больших массивов чисел за один такт. Технология использует 512-битные регистры, что позволяет выполнять восемь операций над 64-битными значениями или шестнадцать операций над 32-битными одновременно. Такой подход заметно ускоряет вычисления в задачах, где данные можно сформировать в векторные блоки.
Расширение включает маскирование, позволяющее выполнять команду только над частью элементов. Это уменьшает количество условных переходов в коде и снижает нагрузку на конвейер. Дополнительные инструкции работают с целыми числами, числами с плавающей запятой и логическими операциями, покрывая широкий набор сценариев: от фильтрации данных до матричных вычислений.
Практический результат от AVX-512 заметен в коде, который опирается на плотные циклы и повторяющиеся операции. Программист может использовать встроенные функции компилятора (intrinsics) или позволить оптимизатору автоматически применять команды расширения. При работе вручную важно учитывать структуру данных, выравнивание памяти и доступность конкретных подмножеств AVX-512 в используемом процессоре.
AVX512: что это и как работает расширение инструкций

AVX-512 – расширенный набор векторных команд, рассчитанный на выполнение операций над 512-битными данными. Он опирается на дополнительные регистры ZMM, расширенную систему масок и поднаборы инструкций, ориентированные на разные группы задач: целочисленные расчёты, операции с числами с плавающей запятой, перестановку данных, криптографию.
Базовая работа AVX-512 строится на параллельной обработке нескольких элементов внутри одного регистра. Процессор выполняет одну команду сразу над серией значений, что уменьшает число итераций в циклах и снижает нагрузку на общий поток команд.
- 512-битные регистры ZMM0–ZMM31 – основа параллельной обработки.
- Регистры масок K0–K7 определяют, какие элементы участвуют в операции.
- Подмножества команд (VL, BW, DQ, IFMA, VNNI и др.) включаются в зависимости от архитектуры CPU.
Чтобы получить прирост скорости, важно адаптировать структуру данных под векторные схемы. Разделение массивов на блоки кратные 64 или 32 байтам уменьшает число «хвостовых» элементов, которые требуют отдельной обработки.
- Проверить поддержку AVX-512 у процессора (Intel Xeon, Core отдельных поколений, некоторые модели ноутбуков).
- Использовать встроенные функции (intrinsics) для точного контроля над векторными операциями.
- Избегать смешивания AVX-512 и старых наборов инструкций внутри критичных участков кода, чтобы минимизировать переключение режимов.
- Профилировать производительность – разные подмножества AVX-512 могут вести себя по-разному в зависимости от размера данных и частоты вызовов.
Назначение AVX-512 в современных процессорах и типы поддерживаемых операций
AVX-512 расширяет возможности процессора при работе с плотными числовыми массивами, позволяя выполнять до шестнадцати операций над 32-битными значениями или восьми операций над 64-битными числами в одном цикле. Архитектура ориентирована на задачи, где объём операций значительно превышает объём управляющей логики: моделирование, обработка сигналов, машинное обучение, анализ больших массивов логов.
Набор команд разделён на подгруппы, каждая из которых охватывает определённый тип вычислений. Это позволяет компилятору или разработчику выбрать нужные инструкции в зависимости от структуры данных и характера вычислений. Поддержка конкретных подмножеств зависит от модели CPU: серверные Xeon предлагают полный набор, настольные процессоры часто включают лишь часть модулей.
Основные виды операций AVX-512 включают:
- арифметические действия с числами с плавающей запятой одинарной и двойной точности;
- целочисленные операции с расширением разрядности, включая умножение и суммирование нескольких элементов за цикл;
- логические операции и сравнения, применяемые к каждому элементу регистра;
- перестановку и уплотнение данных с возможностью гибкого выбора элементов;
- инструкции для машинного обучения, такие как VNNI, ускоряющие свёртки и матричные умножения;
- криптографические подмножества (IFMA), уменьшающие число шагов при работе с большими числами.
Практическая польза проявляется в задачах, где данные легко группируются в блоки фиксированного размера. Чтобы получить стабильный прирост, требуется заранее продумать организацию массивов, минимизировать разрывы в памяти и избегать смешивания разных векторных наборов на одном критичном участке кода.
Структура 512-битных регистров и их роль в вычислениях

Регистры ZMM представляют собой 512-битные блоки, разделённые на равные сегменты по 32 или 64 бита в зависимости от используемого типа данных. Такое деление позволяет выполнять операции над несколькими элементами параллельно, не затрагивая соседние сегменты. В архитектуре доступно до 32 ZMM-регистров, что облегчает работу с большими массивами без постоянных обращений к памяти.
Дополнительную роль играют регистры масок K0–K7. Они определяют, какие элементы внутри ZMM участвуют в вычислении. Это полезно в циклах с неполными блоками данных, где требуется пропустить часть элементов, не разрывая общий ход вычислений.
- ZMM0–ZMM31 – основной набор для параллельной обработки данных.
- K0–K7 – маски, управляющие выборочными операциями в пределах регистра.
- Возможность комбинировать перестановку, арифметику и сравнение в пределах одного вызова инструкции.
Правильно организованные данные позволяют задействовать всю ширину регистра. Массивы, выравнённые по 64 байтам, уменьшают количество дополнительных загрузок и предотвращают распад блока на фрагменты, требующие отдельной обработки.
- Группировать данные в массивы фиксированного размера, кратные ширине регистра.
- Проверять выравнивание и корректировать структуру хранения при необходимости.
- Использовать маскирование для «хвостовых» элементов без переходов в ветвления.
Принцип маскирования операций и управление выполнением команд
Маскирование в AVX-512 основано на использовании регистров K0–K7, где каждый бит соответствует элементу внутри ZMM-регистра. Маска определяет, какие элементы участвуют в операции, а какие пропускаются. Такой подход убирает необходимость условных переходов и снижает нагрузку на конвейер команд.
Инструкции AVX-512 поддерживают несколько режимов поведения при отключённых элементах: сохранение исходного значения, запись нулей или формирование альтернативного результата. Это позволяет контролировать вычисления в ситуациях, когда размер массива не совпадает с шириной регистра или требуется выборочная обработка данных.
- K-регистры задают набор активных позиций внутри 512-битного блока.
- Маски могут использоваться совместно с загрузкой и сохранением данных, что уменьшает количество вспомогательных операций.
- Режимы «merge» и «zeroing» позволяют выбирать стратегию обработки отключённых элементов.
При работе с масками важно учитывать распределение данных в памяти. Неправильное выравнивание или нерегулярные структуры приводят к большему числу отключённых сегментов, что уменьшает плотность обработки и увеличивает число обращений к памяти.
- Подготавливать массивы так, чтобы большая часть элементов попадала в активные позиции маски.
- Использовать режим «merge» для сохранения исходных значений, когда требуется частичная обработка.
- Применять «zeroing» в ситуациях, где важна предсказуемость результата и контроль над побочными значениями.
Как происходит обработка данных векторными блоками в AVX-512

Векторная обработка в AVX-512 строится на разбиении массива на блоки, соответствующие ширине 512-битного регистра. Каждый блок содержит набор элементов одинакового типа, что позволяет выполнять одинаковую операцию одновременно над всеми сегментами. Процессор загружает данные в регистры ZMM, применяет выбранную инструкцию и сохраняет результат обратно в память.
Алгоритм работы опирается на последовательность действий: загрузка, перестановка при необходимости, выполнение операции и сохранение. Если количество элементов массива не совпадает с размером блока, используется маскирование. Это позволяет обработать оставшиеся элементы без разрывов в циклах.
Основные этапы обработки:
- загрузка данных в ZMM с учётом выравнивания по 64 байтам;
- опциональная перестановка элементов при работе с матрицами или сложными структурами;
- применение арифметических, логических или смешанных инструкций;
- запись результата с использованием масок при наличии неполных блоков.
Чтобы получить стабильный прирост скорости, важно исключить лишние переходы между наборами инструкций. Использование intrinsics позволяет точно контролировать последовательность действий и уменьшить количество вспомогательных операций.
Набор AVX-512 поддерживает работу с данными одинарной и двойной точности, целочисленными блоками разного размера, а также сложными перестановками. При правильной организации массива процессор загружает данные без лишних обращений к кэшу, что сокращает задержки и увеличивает пропускную способность вычислительного контура.
Ограничения AVX-512: частотные просадки, энергопотребление и совместимость
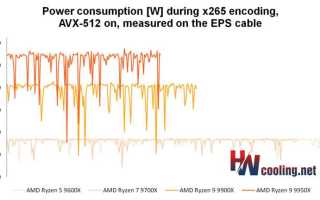
Использование AVX-512 связано с увеличением энергопотребления и снижением тактовой частоты процессора. При выполнении тяжёлых векторных операций CPU может снижать частоту на 200–400 МГц в зависимости от модели, чтобы удерживать тепловой пакет в допустимых пределах. Это важно учитывать при планировании нагрузки на серверы и рабочих станций.
Совместимость AVX-512 зависит от конкретного поколения процессора. Не все настольные модели поддерживают полный набор подмножеств инструкций. Важно проверять наличие инструкций VNNI, IFMA, BW, DQ, которые могут отсутствовать в мобильных или бюджетных CPU.
Ниже приведена таблица основных ограничений и рекомендаций при использовании AVX-512:
| Параметр | Описание | Рекомендации |
|---|---|---|
| Снижение частоты | До 400 МГц при полной загрузке ZMM-регистров | Использовать параллельные потоки с контролем нагрузки, избегать длительных непрерывных блоков AVX-512 |
| Энергопотребление | Повышение потребления до 30–50% относительно обычных операций | Применять маскирование и разделять тяжёлые блоки, чтобы распределить нагрузку по времени |
| Совместимость | Разные наборы инструкций поддерживаются на серверных и настольных CPU | Проверять наличие подмножеств команд и использовать intrinsics с условными проверками |
| Выравнивание данных | Неправильная структура массива снижает пропускную способность | Выравнивать массивы по 64 байтам, группировать элементы по типу данных |
Эффективное использование AVX-512 требует балансировки между производительностью и тепловым режимом. Оптимизация кода и корректное распределение данных позволяет снизить негативное влияние на частоту и энергопотребление.
Практическое применение AVX-512 в задачах вычислений и мультимедиа

AVX-512 используется для ускорения вычислений, где массивы данных можно обрабатывать блоками. В научных вычислениях это линейная алгебра, матричные умножения, фильтрация сигналов и моделирование физических процессов. Параллельная обработка 8–16 элементов за такт сокращает время выполнения тяжёлых циклов в несколько раз.
В задачах мультимедиа AVX-512 ускоряет кодирование и декодирование видео, обработку изображений, наложение фильтров и эффекты. Команды поддерживают одновременно операции с целыми числами и числами с плавающей запятой, что позволяет выполнять смешанные вычисления без переключения режимов.
Примеры использования:
- Матрицы и тензоры в машинном обучении – ускорение свёрток и перемножений блоков через intrinsics VNNI.
- Обработка аудио и видео – параллельное суммирование и фильтрация сигналов, ускорение FFT.
- Научные симуляции – расчёт гравитации, электромагнитных полей и динамики частиц с использованием целочисленных и плавающих операций.
- Криптография – операции умножения больших чисел через подмножество IFMA.
Для максимальной производительности важно структурировать данные блоками, выравнивать массивы по 64 байтам и использовать маски K-регистров для обработки неполных блоков. Это снижает количество обращений к памяти и сохраняет высокую плотность вычислений в ZMM-регистрах.
Вопрос-ответ:
Что такое AVX-512 и чем оно отличается от AVX2?
AVX-512 — это набор команд процессора для параллельной обработки данных в 512-битных регистрах ZMM. В отличие от AVX2, который работает с 256-битными регистрами, AVX-512 позволяет одновременно выполнять больше арифметических и логических операций над числами с плавающей запятой и целыми числами. Кроме того, AVX-512 использует маски K-регистров для выборочной обработки элементов внутри блока, что упрощает работу с неполными массивами.
Как маскирование влияет на выполнение команд AVX-512?
Маскирование с использованием регистров K0–K7 позволяет включать или исключать отдельные элементы из операции внутри 512-битного регистра. Это позволяет работать с массивами, размер которых не кратен ширине регистра, без ветвлений и дополнительных условий. Режимы «merge» и «zeroing» управляют тем, что происходит с отключёнными элементами: сохраняются исходные значения или обнуляются, что даёт контроль над результатом и предотвращает побочные эффекты.
Какие задачи получают наибольшую выгоду от AVX-512?
Наибольший прирост производительности наблюдается при обработке больших числовых массивов, где данные можно разделить на блоки: матричные умножения, фильтрация сигналов, FFT, симуляции физических процессов, кодирование и декодирование видео. Использование AVX-512 сокращает количество итераций в циклах и уменьшает обращения к памяти за счёт параллельной обработки элементов регистра.
Какие ограничения AVX-512 нужно учитывать при разработке приложений?
Основные ограничения связаны с повышенным энергопотреблением и снижением тактовой частоты процессора при полной загрузке ZMM-регистров. Некоторые модели CPU поддерживают не все подмножества инструкций, поэтому проверка доступных команд обязательна. Неправильное выравнивание массивов или смешивание различных наборов инструкций может снизить плотность обработки и увеличить задержки.
Как правильно организовать данные для работы с AVX-512?
Для оптимальной работы данные следует группировать в блоки, кратные 512 битам, и выравнивать массивы по 64 байтам. Это позволяет загрузить целый блок в ZMM-регистр без дополнительных обращений к памяти. Для оставшихся элементов используют маскирование, что обеспечивает обработку неполных блоков без изменения структуры кода. Также рекомендуется избегать частого переключения между AVX-512 и другими наборами инструкций в критичных участках.
Зачем процессору нужен набор команд AVX-512?
AVX-512 позволяет процессору обрабатывать большие блоки данных параллельно, используя 512-битные регистры ZMM. Это сокращает количество циклов при работе с массивами чисел с плавающей запятой и целыми числами, ускоряет матричные вычисления, фильтрацию сигналов и обработку мультимедиа. Маскирование K-регистров позволяет обрабатывать только часть элементов без дополнительных условных переходов, что повышает плотность вычислений и снижает нагрузку на конвейер.
Какие ограничения стоит учитывать при использовании AVX-512?
Использование AVX-512 увеличивает энергопотребление и может приводить к снижению тактовой частоты процессора на 200–400 МГц при полной загрузке регистров ZMM. Не все процессоры поддерживают полный набор инструкций, поэтому перед применением следует проверить доступность конкретных подмножеств, таких как VNNI или IFMA. Также важно выравнивать массивы данных по 64 байтам и использовать маскирование для неполных блоков, чтобы сохранить плотность обработки и снизить количество обращений к памяти.