Содержание статьи

Медиана помогает быстро понять, где в наборе данных находится центральное значение без влияния редких выбросов. В pandas этот показатель вычисляется напрямую, поэтому можно сразу работать с числовыми столбцами любой длины и структуры. Метод median() учитывает пропуски, различия типов и режим агрегирования, что позволяет применять его в разных задачах анализа.
При работе со столбцами, полученными из файлов CSV или Excel, медиана часто используется для проверки сдвига распределения и подготовки данных к моделям. Например, в наборе из нескольких тысяч строк медиана может показать реальное «ядро» значений даже при наличии экстремальных чисел. В pandas можно вычислять медиану не только по одному столбцу, но и по группам, по строкам, а также в формате скользящего окна.
Если данные содержат пропуски или смешанные типы, pandas корректно игнорирует неподходящие элементы, что избавляет от предварительной фильтрации вручную. Благодаря этому медиана становится удобным инструментом для быстрой проверки предположений, анализа распределений и подготовки данных к дальнейшей обработке.
Определение медианы в DataFrame и Series через метод median()
Метод median() в pandas рассчитан на работу как с отдельными столбцами, так и с полными таблицами. Он вычисляет центральное значение по числовым данным, автоматически пропуская несовместимые элементы. Формат результата зависит от структуры объекта: для Series возвращается одно число, для DataFrame – серия медиан по каждому подходящему столбцу.
- Для Series: s.median() – выдаёт одно числовое значение.
- Для DataFrame: df.median() – выдаёт набор медиан по всем числовым столбцам.
- При наличии строковых или категориальных данных функция игнорирует их без ошибок.
Перед вычислением полезно проверить типы столбцов, чтобы исключить неподходящие значения. В случаях, когда данные загружены из текстовых файлов, числовые колонки могут быть импортированы как строки. В таких ситуациях помогает явное преобразование к нужному типу через pd.to_numeric().
- Проверить типы данных: df.dtypes.
- При необходимости преобразовать колонки: df[‘col’] = pd.to_numeric(df[‘col’], errors=’coerce’).
- Вызвать медиану: df.median() или df[‘col’].median().
Такой подход снижает вероятность некорректных значений и даёт контроль над тем, какие столбцы участвуют в вычислении медианы. Это особенно полезно при анализе таблиц с разнородными данными.
Расчёт медианы по выбранному столбцу с учётом типа данных

При вычислении медианы в отдельном столбце важно убедиться, что значения представлены в числовом формате. Если данные импортированы из CSV или Excel, столбец может содержать строковый тип из-за лишних символов или неправильного распознавания. В таких случаях медиана не будет рассчитана корректно, и pandas вернёт пропуск.
Для приведения данных к нужному формату используют pd.to_numeric() с параметром errors=»coerce». Это позволяет преобразовать допустимые элементы, а неподходящие значения заменить на NaN, чтобы они не участвовали в расчётах.
Последовательность действий:
- Проверить тип столбца: df[‘col’].dtype.
- При необходимости выполнить преобразование: df[‘col’] = pd.to_numeric(df[‘col’], errors=’coerce’).
- Посчитать медиану: df[‘col’].median().
Такой подход помогает исключить ошибки, вызванные смешанными типами, и получить корректный результат даже при работе с данными, содержащими пропуски или текстовые элементы, попавшие в числовой столбец.
Медиана по строкам и столбцам с параметром axis
Параметр axis в методе median() определяет направление расчёта. Значение axis=0 задаёт вычисление по столбцам, а axis=1 – по строкам. Это полезно при анализе таблиц, где требуется получить сводные показатели по горизонтали или вертикали без предварительного разбиения данных.
Расчёт по столбцам позволяет быстро получить медиану для каждого числового признака. Такой режим удобен, когда таблица содержит несколько параметров, и нужно оценить центральные значения по каждому из них. При использовании df.median(axis=0) pandas исключает из вычислений неподходящие типы и пропуски.
Режим axis=1 применяется для строк, где требуется объединить несколько значений в один показатель. Такой подход встречается при обработке результатов измерений или при работе с матрицами оценок. Перед расчётом стоит убедиться, что строка не содержит текстовых элементов, чтобы избежать некорректных значений.
Пример последовательности:
- Медиана по столбцам: df.median(axis=0).
- Медиана по строкам: df.median(axis=1).
- Проверка данных перед расчётом: df.apply(pd.to_numeric, errors=»coerce»).
Использование параметра axis позволяет гибко выбирать направление вычислений и получать набор показателей, подходящий под конкретную задачу анализа.
Игнорирование пропусков при вычислении медианы
Метод median() по умолчанию исключает значения NaN, что позволяет получать корректный результат даже при неполных данных. Такой режим подходит для таблиц, где пропуски встречаются нерегулярно и не требуют предварительного заполнения.
Чтобы контролировать объём данных, участвующих в расчёте, стоит оценить количество пропусков в каждом столбце. Это помогает понять, насколько медиана отражает реальную структуру выборки. Проверку выполняют с помощью df.isna().sum(). Если доля пропусков велика, лучше предварительно заменить их на подходящие значения или удалить строки, чтобы не исказить распределение.
Перед вычислением медианы рекомендуют привести столбцы к числовому типу, поскольку строковые элементы при преобразовании через pd.to_numeric() также превращаются в NaN. Это освобождает от ручного поиска ошибочных значений и делает расчёт медианы более точным.
- Проверка пропусков: df.isna().sum().
- Преобразование типов: df[‘col’] = pd.to_numeric(df[‘col’], errors=»coerce»).
- Расчёт медианы с учётом исключённых пропусков: df[‘col’].median().
Игнорирование пропусков позволяет использовать медиану как устойчивый показатель при анализе данных, где встречаются нечисловые или отсутствующие значения, сохраняя при этом точность расчёта.
Медиана для сгруппированных данных с использованием groupby()
Метод groupby() позволяет разбить DataFrame на подгруппы по одному или нескольким столбцам и вычислить медиану отдельно для каждой группы. Это полезно при анализе категориальных признаков, когда нужно сравнить центральные значения числовых показателей между категориями.
Пример вычисления медианы по группам:
df.groupby('category')['value'].median()Результат возвращается в виде Series с индексом, соответствующим уникальным значениям категориального столбца. Для нескольких числовых колонок медианы можно получить сразу:
df.groupby('category')[['value1', 'value2']].median()Пример наглядной таблицы результата:
| category | value1 | value2 |
|---|---|---|
| A | 12 | 45 |
| B | 20 | 50 |
| C | 18 | 47 |
Такой подход позволяет анализировать распределение данных внутри каждой группы, выявлять отклонения и быстро сравнивать показатели без необходимости фильтровать DataFrame вручную.
Получение медианы для нескольких столбцов одновременно
В pandas можно вычислять медиану сразу для нескольких столбцов, указав их список при вызове метода median(). Это позволяет ускорить анализ и получить сводные показатели без повторного обращения к DataFrame.
Последовательность действий:
- Выбрать нужные столбцы: cols = [‘value1’, ‘value2’, ‘value3’].
- Вызвать медиану: df[cols].median().
- Получить результат в виде Series, где индекс – названия столбцов, а значения – медианы.
Дополнительно можно использовать фильтрацию по типу данных, чтобы автоматически выбирать все числовые колонки:
- numeric_cols = df.select_dtypes(include=’number’).columns
- df[numeric_cols].median()
Такой подход особенно полезен при работе с большими таблицами, где нужно сравнивать центральные значения сразу по нескольким показателям, не создавая промежуточных переменных.
Сравнение медианы и среднего для оценки распределения данных

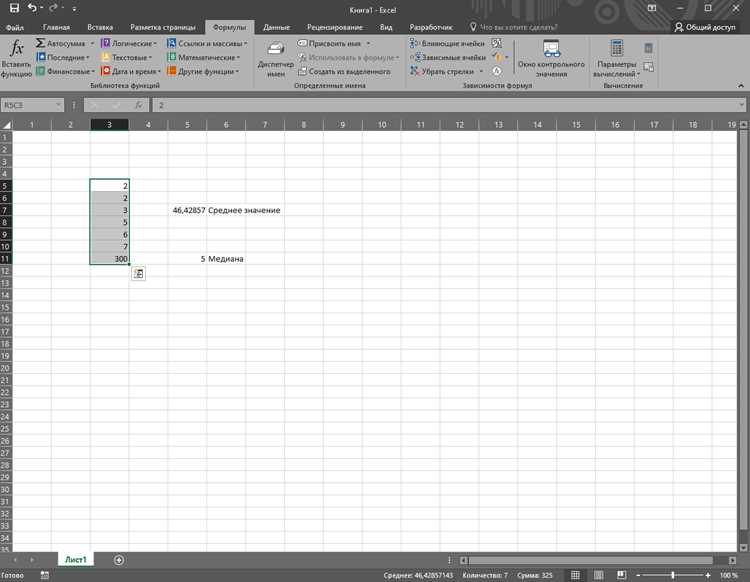
Медиана и среднее арифметическое отражают разные аспекты распределения данных. Среднее чувствительно к выбросам, а медиана показывает центральное значение, игнорируя экстремальные значения. В pandas среднее вычисляется методом mean(), медиана – median().
Пример анализа:
- Если df[‘col’].mean() существенно больше df[‘col’].median(), распределение имеет положительный сдвиг.
- Если среднее меньше медианы, наблюдается отрицательный сдвиг.
- Если медиана близка к среднему, распределение относительно симметричное.
median_val = df['col'].median()
mean_val = df['col'].mean()
print(f"Медиана: {median_val}, Среднее: {mean_val}")Такой подход позволяет быстро оценить форму распределения и выявить наличие выбросов, что помогает принимать решения о нормализации данных или выборе подходящей статистики для анализа.
Медиана в окне скользящего расчёта через rolling().median()

Метод rolling() позволяет вычислять медиану по скользящему окну фиксированного размера, что полезно для анализа временных рядов или последовательных измерений. После задания окна применяется median(), чтобы получить медиану внутри каждого окна.
Пример использования:
df['value'].rolling(window=5).median()Здесь window=5 задаёт размер окна в 5 элементов. pandas автоматически пропускает NaN и возвращает медиану для каждой позиции, где окно полностью заполнено. Если часть окна содержит пропуски, медиана считается по оставшимся числам.
Рекомендации по работе с rolling().median():
- Выбирайте размер окна исходя из периодичности данных.
- Для симметричных окон можно использовать параметр center=True, чтобы медиана была привязана к середине окна.
- Скользящие медианы помогают сгладить выбросы и выявить тренды без искажения данных экстремальными значениями.
Такой подход удобен для финансовых, погодных и производственных данных, где важно отслеживать локальные изменения центрального значения без влияния резких скачков.
Вопрос-ответ:
Как посчитать медиану для одного столбца в pandas?
Для одного столбца используйте метод median() на Series. Например, df[‘col’].median() вернёт центральное значение столбца, автоматически игнорируя NaN и некорректные элементы.
Можно ли вычислить медиану сразу для нескольких столбцов?
Да, достаточно передать список столбцов DataFrame и вызвать метод median(). Пример: df[[‘col1′,’col2′,’col3’]].median(). Результатом будет Series с медианами по каждому столбцу. Для автоматического выбора всех числовых столбцов используйте df.select_dtypes(include=’number’).columns.
Как рассчитать медиану для сгруппированных данных?
Метод groupby() позволяет разбить DataFrame на группы и вычислить медиану по каждой из них. Пример: df.groupby(‘category’)[‘value’].median() создаст Series, где индекс — категории, а значения — медианы. Для нескольких колонок можно использовать df.groupby(‘category’)[[‘value1′,’value2’]].median().
В чём отличие медианы от среднего, и когда её лучше использовать?
Медиана показывает центральное значение набора данных, не влияясь на выбросы, тогда как среднее чувствительно к экстремальным значениям. Если данные содержат выбросы или асимметричное распределение, медиана даёт более реалистичную оценку «середины» значений.