Содержание статьи

Spliterator в Java появился в версии 8 как инструмент для обхода и разделения элементов коллекций. Он объединяет возможности итератора и структуры, позволяющей разбивать задачи для параллельной обработки. Основное назначение Spliterator – облегчить работу с потоками данных, предоставляя более гибкие способы обхода, чем стандартный Iterator.
Spliterator поддерживает метод tryAdvance, который позволяет последовательно обрабатывать элементы, и forEachRemaining, позволяющий применять действия ко всем оставшимся элементам. Эти методы дают возможность писать компактный код для последовательной обработки коллекций без явного контроля индексов или состояния итератора.
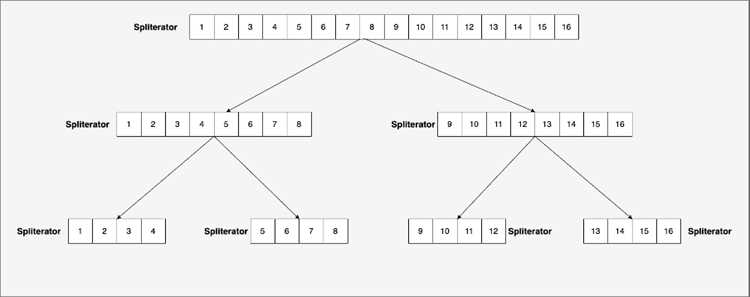
Особая особенность Spliterator – метод trySplit, который разделяет элементы на две части для параллельной обработки. Это особенно важно при работе с большими коллекциями и потоками Stream, где распределение нагрузки между потоками ускоряет вычисления. Разделение может происходить рекурсивно, что делает Spliterator удобным для построения параллельных алгоритмов.
Каждый Spliterator имеет набор характеристик, определяемых методом characteristics(), таких как ORDERED, SIZED, IMMUTABLE. Эти характеристики помогают корректно использовать Spliterator в алгоритмах, оптимизируя обход элементов и определяя возможности параллельной обработки.
Использование Spliterator в связке с потоками Stream позволяет точно контролировать обработку данных. Он подходит для случаев, когда стандартные итераторы и циклы не обеспечивают необходимой гибкости или производительности, особенно при работе с большими или сложными структурами данных.
Java Spliterator: назначение и использование
Spliterator предназначен для обхода и разделения элементов коллекций в Java, сочетая возможности итератора и механизма параллельной обработки. Он обеспечивает контроль над порядком обхода и характеристиками коллекции, что позволяет оптимально использовать данные в потоках Stream.
Метод tryAdvance выполняет действие над одним элементом за раз и возвращает true, пока элементы не закончатся. Это полезно при пошаговой обработке коллекций или при реализации специфических алгоритмов обхода без полного хранения всех элементов в памяти.
Метод forEachRemaining применяет указанное действие ко всем оставшимся элементам Spliterator, сокращая объем кода и минимизируя необходимость в ручных циклах. Он особенно эффективен при обработке больших массивов данных и списков.
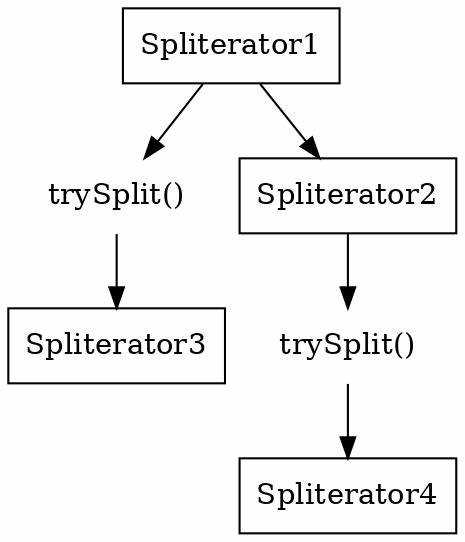
Метод trySplit делит текущий Spliterator на две части, создавая отдельные подзадачи для параллельной обработки. При работе с потоками Stream это позволяет равномерно распределять нагрузку между потоками, ускоряя выполнение сложных вычислений на больших коллекциях.
Характеристики Spliterator, определяемые методом characteristics(), включают флаги ORDERED, SIZED, IMMUTABLE, которые влияют на стратегию обхода и возможность безопасного параллельного выполнения. Знание этих характеристик помогает выбирать подходящие методы обработки для конкретных коллекций.
Использование Spliterator оправдано при работе с массивами, списками, множествами и потоками данных, где требуется точный контроль над обходом, разделением задач и характеристиками коллекции. Он позволяет комбинировать последовательную и параллельную обработку без изменения структуры исходных данных.
Как создать Spliterator для коллекций в Java
Spliterator создается для любой коллекции, реализующей интерфейс Collection, с помощью метода spliterator(). Например, для списка ArrayList вызов myList.spliterator() возвращает объект Spliterator, готовый к обходу элементов.
Для массивов используется статический метод Arrays.spliterator(array), который создает Spliterator с правильными характеристиками, учитывающими размер и порядок элементов. Это позволяет сразу применять методы tryAdvance или forEachRemaining.
Spliterator также можно создавать вручную, реализуя интерфейс Spliterator<T>. В этом случае необходимо определить методы tryAdvance, trySplit, estimateSize и characteristics, что позволяет точно контролировать обход и разделение данных, особенно для нестандартных структур или потоков генерации элементов.
При создании Spliterator важно учитывать тип коллекции и предполагаемый сценарий обработки. Например, для LinkedList предпочтительно использовать встроенный Spliterator, так как он учитывает последовательность элементов, а для массивов – Arrays.spliterator для минимизации накладных расходов.
Различия между Spliterator и Iterator
Spliterator и Iterator оба позволяют обходить элементы коллекций, но имеют принципиальные различия в функциональности и применении. Spliterator разработан с учетом параллельной обработки и разделения данных, тогда как Iterator предназначен только для последовательного обхода.
Основные различия можно отобразить в таблице:
| Характеристика | Iterator | Spliterator |
|---|---|---|
| Обход элементов | Последовательный, с помощью метода next() | Последовательный или параллельный, через tryAdvance и forEachRemaining |
| Разделение задач | Не поддерживается | Поддерживается методом trySplit для параллельной обработки |
| Характеристики коллекции | Не предоставляет информации о свойствах коллекции | Через метод characteristics() можно узнать ORDERED, SIZED, IMMUTABLE и другие флаги |
| Применение в Stream | Неприменимо напрямую | Используется для построения последовательных и параллельных потоков Stream |
| Создание | Через iterator() коллекции | Через spliterator() или реализацию интерфейса Spliterator |
Выбор между Iterator и Spliterator зависит от задачи: для простой последовательной обработки достаточно Iterator, для параллельных вычислений и контроля характеристик коллекции предпочтительнее Spliterator.
Использование метода tryAdvance для обхода элементов

Метод tryAdvance Spliterator позволяет обработать один элемент за вызов, возвращая true, пока элементы не закончатся. Он подходит для пошагового обхода коллекций и интеграции с пользовательскими алгоритмами.
Рекомендации по использованию:
- Передача действия через лямбда-выражение или объект Consumer для обработки текущего элемента.
- Использовать цикл while(spliterator.tryAdvance(…)) для последовательного обхода всех элементов.
- Не изменять коллекцию во время обхода, чтобы избежать ConcurrentModificationException.
Пример применения:
- Создание Spliterator для списка: Spliterator<String> spliterator = list.spliterator();
- Обход элементов по одному:
while(spliterator.tryAdvance(System.out::println)) {} - Можно комбинировать с условием, выполняя действия только для определенных элементов.
Метод tryAdvance обеспечивает контроль за обработкой каждого элемента и минимизирует потребление памяти, так как не требует предварительной загрузки всех элементов в отдельную структуру. Он особенно полезен для больших коллекций и потоков данных, где важна постепенная обработка.
Применение forEachRemaining для обработки всех элементов
Метод forEachRemaining Spliterator выполняет заданное действие для всех оставшихся элементов без необходимости вручную контролировать обход. Он сокращает код и повышает читаемость при обработке коллекций и потоков данных.
Рекомендации по использованию:
- Передавать действие через объект Consumer или лямбда-выражение, например: spliterator.forEachRemaining(System.out::println).
- Использовать для завершения обхода после частичной обработки через tryAdvance, чтобы не повторять код.
- Применять при работе с большими коллекциями, чтобы уменьшить накладные расходы на управление циклом.
- Можно комбинировать с фильтрацией элементов внутри лямбды для выполнения специфических операций.
Метод forEachRemaining полезен при интеграции с потоками Stream, когда требуется выполнить действие для всех элементов без параллельного разделения. Он позволяет обрабатывать коллекции компактно и безопасно, без ручного контроля индексов и состояния итератора.
Разделение задач с помощью trySplit
Метод trySplit Spliterator создает новый Spliterator, покрывающий часть элементов исходной коллекции, оставляя оригинальный Spliterator для оставшихся элементов. Это позволяет распределять обработку между потоками при параллельном вычислении.
Рекомендации по использованию:
- Вызывать trySplit() рекурсивно для больших коллекций, чтобы создавать несколько подзадач для параллельной обработки.
- Проверять возвращаемое значение: если метод возвращает null, дальнейшее деление невозможно, и следует использовать текущий Spliterator для последовательного обхода.
- Использовать в сочетании с потоками Stream для ускорения вычислений, особенно при работе с массивами или списками с большим количеством элементов.
- Учитывать характеристики коллекции через метод characteristics(), чтобы понимать порядок и размер подзадач, создаваемых методом trySplit.
Метод trySplit позволяет организовать баланс между количеством потоков и размером задач, что важно для оптимального использования ресурсов при параллельной обработке данных.
Определение характеристик Spliterator через characteristics()
Метод characteristics() возвращает набор флагов, описывающих свойства Spliterator и коллекции, которую он обходил. Эти характеристики помогают выбирать подходящие методы обработки и определять возможности параллельного выполнения.
Основные характеристики:
- ORDERED – элементы имеют определенный порядок.
- SIZED – известно точное количество элементов.
- IMMUTABLE – коллекция не изменяется после создания Spliterator.
- CONCURRENT – коллекция может изменяться параллельно с обходом.
- DISTINCT – элементы уникальны.
Рекомендации по использованию:
- Использовать характеристики для оптимизации работы с потоками Stream и параллельного распределения задач через trySplit.
- Проверять наличие флага SIZED, чтобы заранее определить размер подзадач и корректно оценить estimateSize().
- При обработке неизменяемых коллекций применять IMMUTABLE, что позволяет безопасно параллелить вычисления.
- Учитывать ORDERED при сохранении последовательности элементов, особенно в списках и массивах.
Знание характеристик Spliterator помогает точно управлять обходом элементов, контролировать разделение задач и корректно интегрировать обработку данных с потоками Stream.
Применение Spliterator в потоках Stream

Spliterator интегрируется с потоками Stream для построения последовательных и параллельных вычислений. Поток использует Spliterator для обхода элементов коллекции и распределения задач между потоками при параллельной обработке.
Рекомендации по использованию:
- Для создания потока на основе коллекции применять stream() или parallelStream(), Spliterator будет автоматически использован для обхода элементов.
- При работе с большими коллекциями и сложными вычислениями использовать параллельный поток, чтобы trySplit делил задачи между ядрами процессора.
- Характеристики Spliterator влияют на поведение Stream: ORDERED сохраняет порядок элементов, SIZED позволяет заранее оценить размер подзадач.
- Для кастомных структур данных реализовать собственный Spliterator, чтобы Stream корректно обрабатывал элементы в последовательном или параллельном режиме.
Использование Spliterator в потоках Stream позволяет комбинировать преимущества последовательного обхода и параллельной обработки, обеспечивая контроль над характеристиками коллекции и оптимальное распределение задач без дополнительного кода управления итерацией.
Вопрос-ответ:
Что такое Spliterator в Java и чем он отличается от обычного Iterator?
Spliterator — это интерфейс для обхода и разделения элементов коллекций. В отличие от Iterator, он поддерживает параллельную обработку через метод trySplit и предоставляет характеристики коллекции через characteristics(), такие как порядок элементов, размер и возможность параллельного изменения.
Как использовать метод tryAdvance для обхода коллекции?
Метод tryAdvance выполняет действие над одним элементом за вызов и возвращает true, пока элементы не закончились. Обычно его используют в цикле while, передавая лямбда-выражение или объект Consumer для обработки элементов. Это позволяет обрабатывать данные поэтапно без загрузки всей коллекции в память.
Для чего применяется метод forEachRemaining в Spliterator?
Метод forEachRemaining выполняет указанное действие для всех оставшихся элементов Spliterator. Он сокращает код и подходит для обработки больших коллекций, когда нужно применить однотипное действие ко всем элементам без ручного управления циклом.
Как метод trySplit помогает в параллельной обработке данных?
Метод trySplit делит текущий Spliterator на две части: одна продолжает обход оставшихся элементов, а другая обрабатывается отдельно. Это позволяет распараллеливать задачи и использовать несколько потоков для ускорения вычислений на больших коллекциях, контролируя размер и порядок подзадач.
Какая информация доступна через метод characteristics() и как её использовать?
Метод characteristics() возвращает набор флагов, описывающих свойства Spliterator, такие как ORDERED, SIZED, IMMUTABLE и CONCURRENT. Эти данные помогают выбирать подходящие методы обхода и деления задач, контролировать порядок элементов и оценивать возможности параллельной обработки.