Содержание статьи

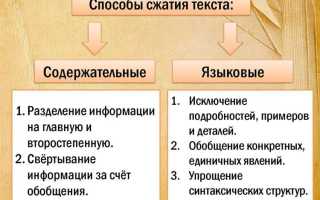
Объёмы данных растут быстрее, чем доступные ресурсы хранения. Чтобы сократить нагрузку на память и каналы передачи, используют алгоритмы, ориентированные на тип содержимого: текст, изображение, звук или видео. Выбор метода влияет на скорость обработки, итоговый размер и качество результата.
При работе с текстом полезны схемы кодирования, опирающиеся на частотный анализ символов. Они уменьшают количество бит на наиболее повторяющиеся элементы и дают ощутимый выигрыш при больших массивах. Для архивирования документации или исходного кода подходят алгоритмы без потерь, где итоговые данные позволяют полностью восстановить оригинал.
Графические и аудиофайлы обрабатываются иначе: сначала выделяются избыточные компоненты, затем выполняется преобразование и последующее квантование. Такие методы уменьшают размер за счёт удаления малозаметных фрагментов. Чтобы избежать резких искажений, важно подбирать параметры кодирования под конкретный формат: для изображений – степень квантования, для аудио – глубину анализа спектра.
При сжатии видео особое внимание уделяется межкадровым связям. Наборы кадров сравниваются, и повторяющиеся элементы сохраняются один раз, что значительно снижает общий объём. Эффективность зависит от точности обнаружения движения и выбранного уровня детализации.
Практическая рекомендация: перед выбором алгоритма стоит определить допустимые потери, требования к скорости обработки и характер данных. Сочетание нескольких методов в одном процессе часто даёт лучший результат, чем попытка использовать универсальное решение.
Вот план из семи узких и прикладных заголовков уровня :

Алгоритмы без потерь: применяются при работе с текстами, исходными файлами и структурированными данными. Для повышения степени сжатия стоит анализировать частотность символов и выбирать схемы кодирования, нацеленные на уменьшение длины наиболее повторяющихся последовательностей.
Методы с потерями для мультимедиа: подходят для изображений и звука, где допустимо уменьшение точности. Для стабильного результата важно подбирать параметры квантования под конкретный формат, чтобы избежать заметных искажений.
Словарные алгоритмы в архиваторах: формируют базы повторяющихся блоков. Чем больше однородных фрагментов в данных, тем выше коэффициент сжатия. Для максимального эффекта перед архивированием рекомендуется удалять временные и служебные компоненты.
Преобразование и квантование для изображений: позволяет сократить объём за счёт разложения на частотные составляющие. Для материалов с резкими переходами лучше использовать меньший уровень квантования, иначе появляются артефакты.
Кодирование аудио с учётом особенностей слуха: снижает объём, опираясь на маскировку частот. Для речи полезно ограничивать верхний диапазон, поскольку он мало влияет на разборчивость, а для музыки – контролировать сложные спектральные зоны.
Сжатие видео на основе анализа кадров: уменьшает размер за счёт фиксации изменений между кадрами. При съёмке с быстрым движением лучше повышать точность поиска блоков, иначе объём растёт из-за ошибок компенсации.
Оптимизация текстов через кодирование частот: эффективна для логов, таблиц и длинных документов. При подготовке данных полезно исключать повторяющиеся шаблоны и нормализовать структуру, что повышает результативность выбранного алгоритма.
Алгоритмы без потерь: принципы работы и области применения

Алгоритмы без потерь сохраняют точное соответствие исходным данным. Основой служат методы удаления повторяющихся фрагментов, рекурсивное кодирование длин серий и построение словарей, где повторяемые блоки заменяются короткими ссылками. Эти методы эффективны для текстов, конфигураций, исходного кода и структурированных массивов, где требуется стопроцентное восстановление.
Для текстовых файлов используется кодирование, опирающееся на частотность символов и последовательностей. Чем выше неоднородность распределения, тем заметнее уменьшение объёма. Перед обработкой стоит нормализовать данные: убрать дублирующиеся строки, временные поля, лишние пробелы.
При работе с бинарными данными полезны схемы словарного типа. Они формируют перечень встречающихся блоков и заменяют их короткими указателями. Такой подход хорошо работает с логами, архивами проектов и данными, содержащими повторяющиеся структуры.
Для максимального результата важно учитывать характер материала. Наборы с высокой вариативностью дают меньший выигрыш, поэтому стоит предварительно оценивать распределение повторов. В сценариях, где изменение исходного содержимого недопустимо, эти алгоритмы остаются единственным надёжным вариантом сжатия.
Методы сжатия с потерями для мультимедийных данных
В аудиосистемах применяются модели психоакустики. Алгоритм анализирует спектр и убирает частоты, скрытые более сильными компонентами. Для речевых материалов полезно ограничивать диапазон, не влияющий на разборчивость, а для музыкальных треков – контролировать уровень подавления в областях, отвечающих за тембр инструментов.
Видеообработка использует раздельную работу с кадрами и блоками. Алгоритм уменьшает объём за счёт устранения дублирующихся фрагментов и устранения деталей, которые не различаются при нормальной скорости воспроизведения. При съёмке с быстрыми движениями необходимо снижать степень упрощения, иначе заметно растёт число искажений в динамичных сценах.
Чтобы добиться точного баланса между качеством и итоговым размером, рекомендуется выбирать параметры сжатия под конкретный тип материала: для фотографий – контролировать уровень квантования, для аудио – ограничивать ненужный спектр, для видео – корректировать чувствительность к движению.
Использование словарных алгоритмов в архиваторах

Словарные методы позволяют находить повторяющиеся блоки и заменять их ссылками на ранее встречавшиеся последовательности. Такой подход уменьшает объём без изменения исходного содержимого. Эффективность зависит от структуры данных и количества повторов внутри файла.
Основные шаги работы словарных алгоритмов:
- формирование динамического словаря с запоминанием встречающихся фрагментов;
- поиск совпадающих блоков и их замена на указатели фиксированной длины;
- обновление словаря по мере обработки, что позволяет адаптироваться под структуру данных.
Практические рекомендации:
- Перед архивированием удалять временные элементы, лишние пробелы, дублирующиеся строки – это увеличивает плотность повторов и повышает степень сжатия.
- Для больших логов использовать предварительную нормализацию: сортировку записей, объединение однотипных сообщений.
- Для бинарных файлов группировать данные по функциональным блокам, чтобы алгоритм быстрее выделял повторяющиеся шаблоны.
Словарные методы подходят для архивации документов, конфигураций, исходного кода и иных структур, где часто встречаются идентичные фрагменты. При правильной подготовке данных коэффициент уменьшения размера заметно возрастает.
Сжатие изображений через преобразование и квантование

Процесс основан на разложении изображения на частотные компоненты и уменьшении точности тех элементов, которые слабо влияют на визуальное восприятие. Такой подход позволяет значительно сократить объём при контролируемом снижении детализации.
Ключевые этапы обработки:
- разделение изображения на блоки фиксированного размера;
- применение частотного преобразования для выделения низких и высоких компонентов;
- квантование коэффициентов с уменьшением точности высокочастотных данных;
- кодирование полученной матрицы с использованием компактных представлений.
Практические советы по настройке параметров:
- Для снимков с резкими границами снижать силу квантования, чтобы уменьшить вероятность появления заметных блоковых артефактов.
- Для изображений с мягкими переходами использовать более сильное квантование, поскольку потеря высоких частот практически незаметна.
- При обработке технической графики уделять особое внимание сохранению точности низкочастотной части, где находятся основные контуры.
- Для экономии пространства предварительно уменьшать цветовое пространство или переводить изображение в формат с меньшим числом каналов, если задача допускает такую оптимизацию.
Преобразование и квантование позволяют адаптировать степень сокращения к содержимому изображения, обеспечивая баланс между размером и визуальными свойствами файла.
Кодирование аудио с учётом особенностей слухового восприятия

Аудиофайлы сжимаются с потерями на основе анализа спектра и психоакустических эффектов. Алгоритмы определяют частоты, которые маскируются более громкими компонентами, и исключают их из финального потока данных. Это снижает размер без заметного ухудшения качества.
Основные этапы:
- разделение сигнала на временные фреймы и анализ спектра каждого блока;
- выявление частот, находящихся под порогом слышимости или замаскированных сильными тонами;
- квантование и кодирование оставшихся компонент с минимальной потерей информации;
- формирование битового потока с учетом оптимизации повторяющихся паттернов.
Рекомендации по настройке:
- Для речи ограничивать верхний диапазон до 8–12 кГц, что не снижает разборчивость, но уменьшает объём.
- Для музыкальных треков сохранять диапазоны, отвечающие за тембр инструментов, и снижать квантование в областях малозаметного шума.
- При многоканальном аудио контролировать баланс каналов и синхронизацию фаз, чтобы сжатие не вызывало артефактов пространственного восприятия.
- Проверять полученный поток на наличие щелчков и потери деталей при низких уровнях сигнала, корректируя параметры маскировки и квантования.
Использование психоакустического кодирования позволяет уменьшить размер файлов в 5–12 раз для музыки и до 20 раз для речи без ощутимой потери качества.
Сжатие видео на основе межкадрового анализа
Межкадровое сжатие снижает объём видео за счёт фиксации повторяющихся элементов между последовательными кадрами. Алгоритм анализирует движение объектов и сохраняет только различия, вместо хранения полного кадра. Это особенно эффективно для сцен с медленным движением и статическими фонами.
Этапы обработки:
- разделение видео на ключевые (I-кадры) и зависимые (P- и B-кадры);
- вычисление векторов движения между кадрами для идентификации изменяющихся областей;
- кодирование только различий и векторов движения;
- комбинирование с внутрекадровым сжатием для оптимизации локальных деталей.
Рекомендации по настройке параметров:
- Для динамичных сцен уменьшать интервал между ключевыми кадрами, чтобы сохранить четкость движения.
- Для статических сцен увеличивать интервал, что сокращает размер без потери визуальной информации.
- Контролировать точность поиска блоков движения: высокое разрешение повышает качество, но увеличивает размер и нагрузку на процессор.
- При кодировании с потерями регулировать степень квантования для P- и B-кадров, чтобы избежать появления заметных артефактов при воспроизведении.
Межкадровой анализ позволяет уменьшить объём видео в 10–30 раз по сравнению с несжатым потоком, сохраняя приемлемое качество для большинства приложений.
Оптимизация текстовых данных через кодирование частот

Кодирование частот уменьшает объём текстовых данных за счёт присвоения более коротких кодов часто встречающимся символам и последовательностям. Наиболее известные методы – алгоритмы Хаффмана и Арифметическое кодирование, которые адаптируются под распределение частот в конкретном файле.
Пример распределения кодов для текстового документа:
| Символ | Частота | Код Хаффмана |
|---|---|---|
| e | 12% | 0 |
| t | 9% | 10 |
| a | 8% | 110 |
| o | 7% | 1110 |
| прочие | 64% | 1111… |
Рекомендации по применению:
- Перед кодированием провести анализ частот символов или слов для определения оптимальной схемы.
- Для больших массивов данных использовать адаптивное кодирование, чтобы динамически учитывать изменения частоты.
- Удалять лишние пробелы и стандартные шаблоны, чтобы повысить плотность повторов и увеличить коэффициент сжатия.
- Комбинировать кодирование частот с другими методами сжатия, например словарными алгоритмами, для более высокой эффективности.
Правильная настройка кодирования частот позволяет сократить текстовые файлы в 2–5 раз без потери информации, что особенно полезно для архивирования логов, исходного кода и больших документов.
Вопрос-ответ:
Что такое алгоритмы сжатия без потерь и где их применяют?
Алгоритмы без потерь сохраняют точное соответствие исходным данным после восстановления. Они используются для текстовых файлов, исходного кода, конфигураций и баз данных. Основные методы включают кодирование длин серий, словарные алгоритмы и частотное кодирование. Такие подходы позволяют уменьшить размер без потери информации, что важно для документов, требующих полной точности.
Как методы сжатия с потерями применяются к изображениям и видео?
Сжатие с потерями основано на удалении деталей, малозаметных для глаза или слуха. Для изображений применяют преобразование в частотную область и квантование, уменьшая точность высокочастотных компонентов. В видео анализируют движение между кадрами и сохраняют только различия. Такой подход сокращает размер файлов, при этом качество остаётся приемлемым для просмотра и воспроизведения.
В чём преимущество словарных алгоритмов в архиваторах?
Словарные алгоритмы создают список повторяющихся блоков данных и заменяют их короткими ссылками. Этот метод особенно эффективен для файлов с регулярными шаблонами, например логов или исходного кода. Перед сжатием рекомендуется нормализовать данные, удаляя дубли и временные элементы, что повышает степень сжатия.
Каким образом кодирование аудио учитывает особенности слуха человека?
Аудиокодеки используют психоакустические модели для выявления частот, которые маскируются более громкими компонентами. Эти частоты удаляются или уменьшается их точность, что сокращает объём без заметного ухудшения восприятия. Для речи ограничивают верхний диапазон, а для музыки контролируют сохранение спектральных зон, отвечающих за тембр инструментов.
Как кодирование частот помогает уменьшить размер текстовых данных?
Кодирование частот присваивает короткие коды часто встречающимся символам и длинные коды редким. Например, букве «e» в английском тексте соответствует минимальный битовый код, а редким символам — более длинный. Такой подход сокращает общий объём файла. Для больших документов используют адаптивное кодирование, которое учитывает изменения частот по мере обработки данных.
Какие методы сжатия информации лучше использовать для разных типов данных?
Выбор метода зависит от структуры и назначения данных. Для текстовых документов и исходного кода оптимальны алгоритмы без потерь, такие как кодирование длин серий, словарные схемы и частотное кодирование, так как они позволяют восстановить исходный файл полностью. Для изображений применяют преобразование и квантование, где высокочастотные детали слабо влияют на восприятие и могут быть сокращены. В аудио используют психоакустическое кодирование, удаляя частоты, скрытые более громкими компонентами. Видео сжимают через межкадровой анализ, сохраняя только изменения между кадрами. При выборе метода важно учитывать допустимые потери, характеристики материала и требования к итоговому размеру.