Содержание статьи

Установка и настройка Scikit learn в Python
Для работы с Scikit learn необходим Python версии 3.8 или выше и актуальные версии пакетов numpy, scipy и joblib. Установка выполняется через команду pip install scikit-learn, которая автоматически подтянет все зависимости.
После установки рекомендуется проверить корректность работы библиотеки. Для этого в интерактивной оболочке Python достаточно выполнить import sklearn и print(sklearn.__version__). Если ошибок нет и отображается номер версии, библиотека готова к использованию.
Для использования функций Scikit learn в проектах достаточно импортировать нужные модули, например: from sklearn.model_selection import train_test_split или from sklearn.ensemble import RandomForestClassifier. Это позволяет сразу применять алгоритмы разделения данных, классификации и регрессии без дополнительной настройки.
При работе с крупными наборами данных рекомендуется настроить окружение Python для увеличения объёма оперативной памяти и проверки совместимости с numpy и pandas, так как Scikit learn активно использует эти библиотеки для хранения массивов и матриц признаков.
Основные структуры данных и форматы для моделей
Scikit learn работает с данными в виде матриц признаков и векторов целевых значений. Основная структура для признаков – двумерный массив numpy.ndarray или объект pandas.DataFrame, где строки соответствуют наблюдениям, а столбцы – признакам. Для целевой переменной используется одномерный массив numpy.ndarray или pandas.Series.
Все числовые признаки должны быть приведены к числовому типу данных. Категориальные признаки необходимо кодировать с помощью OneHotEncoder или LabelEncoder, так как большинство алгоритмов Scikit learn не обрабатывает строки напрямую.
Для работы с разреженными данными библиотека поддерживает форматы scipy.sparse.csr_matrix и scipy.sparse.csc_matrix. Это удобно при больших разреженных матрицах признаков, например, в задачах текстовой аналитики с мешком слов или TF-IDF.
Перед передачей данных в модели рекомендуется проверять размерность: массив признаков должен быть размером (n_samples, n_features), а целевая переменная – (n_samples,). Несоответствие размерностей приведёт к ошибкам при обучении моделей.
Предобработка данных с помощью Scikit learn

Перед обучением моделей важно привести данные к формату, который Scikit learn может корректно обработать. Для числовых признаков используется масштабирование с помощью StandardScaler или MinMaxScaler. Для категориальных признаков применяют OneHotEncoder или OrdinalEncoder. Пропущенные значения заполняют через SimpleImputer.
Часто применяют комбинации нескольких преобразований с помощью ColumnTransformer, что позволяет одновременно обрабатывать числовые и категориальные столбцы без необходимости ручной разметки.
| Метод | Назначение | Пример применения |
|---|---|---|
| StandardScaler | Нормализация числовых признаков до среднего 0 и стандартного отклонения 1 | from sklearn.preprocessing import StandardScaler |
| MinMaxScaler | Приведение числовых признаков к диапазону [0, 1] | from sklearn.preprocessing import MinMaxScaler |
| OneHotEncoder | Преобразование категориальных признаков в бинарные столбцы | from sklearn.preprocessing import OneHotEncoder |
| SimpleImputer | Заполнение пропущенных значений средним, медианой или константой | from sklearn.impute import SimpleImputer |
| ColumnTransformer | Комбинированная обработка числовых и категориальных признаков в одной структуре | from sklearn.compose import ColumnTransformer |
После предобработки данные становятся готовыми к разделению на обучающую и тестовую выборки с помощью train_test_split и последующему обучению моделей без ошибок размерностей или несовместимых типов данных.
Разделение данных на тренировочные и тестовые наборы
Для корректной оценки качества модели необходимо разделить данные на тренировочный и тестовый наборы. В Scikit learn это выполняется функцией train_test_split из модуля sklearn.model_selection. Обычно используют соотношение 70:30 или 80:20, где большая часть данных предназначена для обучения, а оставшаяся – для проверки точности модели.
Функция принимает массив признаков и целевую переменную, а также параметры test_size для размера тестовой выборки и random_state для воспроизводимости разбиения. Пример: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42).
Если данные несбалансированы по классам, рекомендуется использовать параметр stratify=y, чтобы сохранить пропорции классов в тренировочном и тестовом наборах. Это особенно важно для задач классификации с редкими категориями.
После разделения наборов можно применить предобработку, масштабирование и обучение моделей отдельно к тренировочной выборке, сохраняя тестовую выборку для финальной оценки точности и предотвращения переобучения.
Применение регрессии для прогнозирования
В Scikit learn регрессионные модели позволяют прогнозировать числовые значения на основе набора признаков. Наиболее часто используется LinearRegression, которая строит линейную зависимость между признаками и целевой переменной. Для нестандартных зависимостей применяют Ridge, Lasso или PolynomialFeatures для полиномиальной регрессии.
Для обучения модели необходимо передать тренировочные данные: массив признаков и целевую переменную. После обучения метод predict() позволяет получать прогнозы для новых наблюдений. Пример: model = LinearRegression(); model.fit(X_train, y_train); y_pred = model.predict(X_test).
Оценка точности прогнозов выполняется через метрики mean_squared_error или r2_score, что позволяет сравнивать разные модели и подбирать параметры регуляризации. Перед применением регрессии рекомендуется масштабировать числовые признаки, особенно если используются регуляризованные модели.
Регрессионные модели применяются в прогнозировании цен, прогнозировании спроса, анализе временных рядов и других задачах, где целевая переменная носит непрерывный характер и важно учитывать зависимость от нескольких факторов одновременно.
Классификация объектов и оценка точности моделей

Scikit learn предоставляет широкий набор алгоритмов для классификации объектов, включая LogisticRegression, DecisionTreeClassifier, RandomForestClassifier и KNeighborsClassifier. Для применения модели требуется обучающий набор признаков и целевая переменная с метками классов.
Основные шаги классификации:
- Импорт алгоритма и создание объекта модели. Пример: model = RandomForestClassifier(n_estimators=100, random_state=42).
- Обучение модели с помощью fit(X_train, y_train).
- Получение предсказаний для тестового набора: y_pred = model.predict(X_test).
- Оценка точности с помощью метрик, таких как accuracy_score, precision_score, recall_score и f1_score.
Для анализа качества модели удобно использовать матрицу ошибок (confusion_matrix), которая показывает количество верных и неверных классификаций по каждому классу.
- accuracy_score – доля правильных предсказаний на всем тестовом наборе.
- precision_score – точность предсказания конкретного класса.
- recall_score – полнота предсказания, показывает, какая часть объектов класса была правильно идентифицирована.
- f1_score – гармоническое среднее точности и полноты, полезно при несбалансированных классах.
Для выбора наилучшей модели и настройки гиперпараметров используют кросс-валидацию cross_val_score, которая делит тренировочный набор на несколько частей и оценивает стабильность предсказаний.
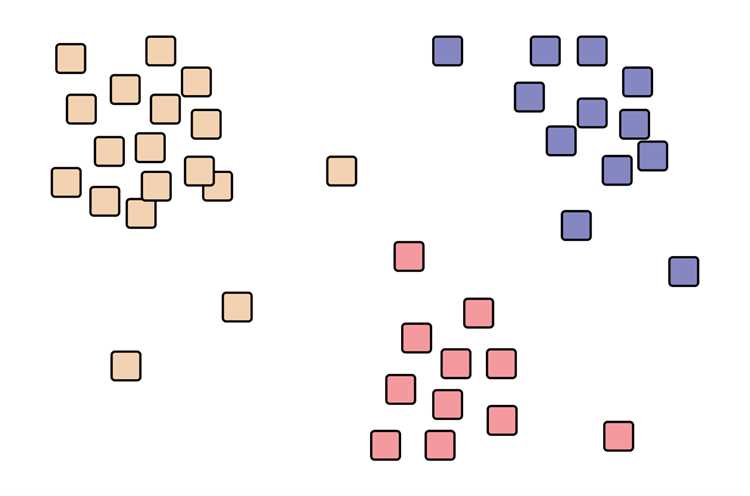
Кластеризация данных и выявление групп

Кластеризация позволяет разделить набор данных на группы с похожими признаками без использования заранее известных меток. В Scikit learn применяются алгоритмы KMeans, AgglomerativeClustering, DBSCAN и MeanShift.
Основные шаги кластеризации:
- Подготовка данных: числовые признаки должны быть масштабированы с помощью StandardScaler или MinMaxScaler.
- Выбор алгоритма и его параметров, например, количество кластеров n_clusters для KMeans или порог eps для DBSCAN.
- Обучение модели на признаках: model.fit(X).
- Получение меток кластеров: labels = model.labels_ или predict(X) для KMeans.
Результаты кластеризации можно анализировать визуально или статистически. Полезные метрики:
- Silhouette Score – оценка компактности и разделимости кластеров.
- Calinski-Harabasz Index – отношение межкластерного расстояния к внутрикластерной дисперсии.
- Davies-Bouldin Index – показывает степень перекрытия кластеров.
Кластеризация используется для сегментации клиентов, выявления закономерностей в больших данных, сокращения размерности и подготовки исходных признаков для последующего обучения моделей классификации или регрессии.
Сравнение моделей и выбор подходящей стратегии

После обучения нескольких моделей необходимо оценить их качество и выбрать наиболее подходящую стратегию для анализа данных. В Scikit learn для этого используют метрики и кросс-валидацию.
Основные этапы сравнения моделей:
- Определение метрик качества в зависимости от задачи: для регрессии mean_squared_error, r2_score, для классификации accuracy_score, f1_score, precision и recall.
- Применение кросс-валидации с помощью cross_val_score для оценки стабильности модели на разных разбиениях данных.
- Сравнение средних значений метрик между моделями и анализ разброса результатов для определения надёжности.
- Учет скорости обучения и предсказаний, особенно для больших наборов данных.
При выборе стратегии рекомендуется учитывать:
- Сложность модели относительно объёма данных и количества признаков.
- Чувствительность модели к выбросам и масштабам признаков.
- Возможность настройки гиперпараметров для улучшения точности.
- Скорость обучения и предсказания для практического применения.
Комбинированный анализ метрик и ресурсов позволяет выбрать модель, которая обеспечивает баланс между точностью и производительностью, минимизируя переобучение и повышая устойчивость прогнозов на новых данных.
Вопрос-ответ:
Как установить Scikit learn и проверить его работоспособность в Python?
Scikit learn устанавливается через команду pip install scikit-learn, которая автоматически подтягивает необходимые зависимости: numpy, scipy и joblib. Проверка работы выполняется командой import sklearn в Python и выводом версии через print(sklearn.__version__). Если ошибок нет и отображается номер версии, библиотека готова к использованию.
Какие структуры данных подходят для моделей Scikit learn?
Модели Scikit learn работают с числовыми признаками в виде двумерных массивов numpy.ndarray или объектов pandas.DataFrame. Целевая переменная представляется одномерным массивом numpy.ndarray или pandas.Series. Категориальные признаки необходимо преобразовать через OneHotEncoder или LabelEncoder, а пропуски заполнять с помощью SimpleImputer.
Как разделить данные на тренировочные и тестовые наборы?
Для разделения используют функцию train_test_split из sklearn.model_selection. Она принимает массив признаков и целевую переменную, а также параметры test_size для доли тестовой выборки и random_state для воспроизводимости. Например: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42). Для задач с несбалансированными классами рекомендуется параметр stratify=y.
Какие алгоритмы регрессии можно использовать для прогнозирования числовых значений?
Для прогнозирования числовых значений применяются LinearRegression, Ridge, Lasso и полиномиальная регрессия с помощью PolynomialFeatures. После обучения методом fit() прогнозы получают через predict(). Для оценки точности используют метрики mean_squared_error и r2_score. Рекомендуется масштабировать признаки при использовании регуляризованных моделей.
Как сравнивать модели и выбрать оптимальную стратегию анализа данных?
Сравнение моделей проводят через метрики качества и кросс-валидацию. Для классификации используют accuracy_score, f1_score, precision и recall, для регрессии — mean_squared_error и r2_score. Кросс-валидация cross_val_score позволяет оценить стабильность предсказаний. При выборе модели учитывают точность, стабильность, скорость обучения и предсказаний, а также чувствительность к выбросам и масштабам признаков.
Как правильно подготовить данные для моделей Scikit learn?
Подготовка данных включает несколько шагов. Числовые признаки должны быть приведены к числовому типу и при необходимости масштабированы с помощью StandardScaler или MinMaxScaler. Категориальные признаки преобразуются через OneHotEncoder или OrdinalEncoder. Пропущенные значения заполняют с помощью SimpleImputer, выбирая среднее, медиану или константу в зависимости от типа признака. После этого проверяют размерности массивов: признаки — (n_samples, n_features), целевая переменная — (n_samples,), чтобы избежать ошибок при обучении моделей.
В каких случаях стоит использовать кластеризацию и какие алгоритмы подходят?
Кластеризацию применяют для выявления групп в данных без заранее известных меток. В Scikit learn используют KMeans для разбиения на фиксированное число кластеров, AgglomerativeClustering для иерархической кластеризации, DBSCAN для обнаружения плотных областей и шумов, а также MeanShift для автоматического определения количества групп. Перед применением данных рекомендуется масштабировать числовые признаки. Для оценки качества кластеризации используют метрики Silhouette Score, Calinski-Harabasz Index или Davies-Bouldin Index.