В Python строка представляет собой упорядоченную последовательность символов, к которой можно обращаться напрямую. Это дает несколько практических подходов: перебор символов без индексов, работа через числовые позиции, а также комбинирование символов с дополнительной информацией, например номером позиции. Каждый из вариантов подходит под конкретные задачи и отличается читаемостью и контролем над результатом.
Материал ориентирован на тех, кто хочет уверенно работать со строками в Python и понимать, что именно происходит при каждом шаге перебора символов. Примеры и пояснения помогут выбрать подходящий вариант под конкретную задачу, а не использовать универсальный шаблон без понимания его ограничений.
Перебор символов строки с помощью цикла for
Базовый пример перебора выглядит следующим образом:
word = "Python"
for char in word:
print(char)Перебор через for подходит для большинства практических ситуаций:
- проверка символов на соответствие условиям;
- поиск определённых знаков в строке;
- пошаговая обработка пользовательского ввода.
Строки в Python поддерживают символы Юникода, поэтому цикл корректно работает с кириллицей и специальными знаками:
text = "Привет!"
for symbol in text:
print(symbol)Использование индексов строки и функции range
Классический вариант перебора строится на связке range и len:
word = "Python"
for i in range(len(word)):
print(word[i])Функция len возвращает длину строки, а range формирует последовательность индексов. Такой способ полезен, если нужно вывести символы с шагом, пропустить отдельные позиции или обработать строку частями.
Практические сценарии, где индексы дают преимущества:
- доступ к соседним символам при анализе текста;
- обход строки в обратном порядке;
text = "код"
for i in range(len(text)):
print(i, text[i])Функция enumerate используется для одновременного получения символа строки и его позиции. При переборе она возвращает пару значений: индекс и текущий символ, что избавляет от необходимости вызывать len и обращаться к строке по индексу вручную.
word = "Python"
for index, char in enumerate(word):
print(index, char)По умолчанию нумерация начинается с нуля. При необходимости стартовое значение можно изменить, передав второй аргумент в enumerate:
for index, char in enumerate(word, 1):
print(index, char)Такой подход удобен, когда требуется вывести буквы в читаемом виде, например при анализе пользовательского ввода или формировании отчетов, где позиция символа имеет значение.
Самый краткий способ – использовать срез с отрицательным шагом:
word = "Python"
for char in word[::-1]:
print(char)Альтернативный вариант – перебор индексов в обратном направлении:
text = "код"
for i in range(len(text) - 1, -1, -1):
print(text[i])Такой подход даёт больше контроля, если требуется работать с позициями символов или добавлять условия, зависящие от индекса. Начальное значение – последний индекс строки, конечное – ноль, шаг отрицательный.
Обработка пробелов и специальных символов в строке
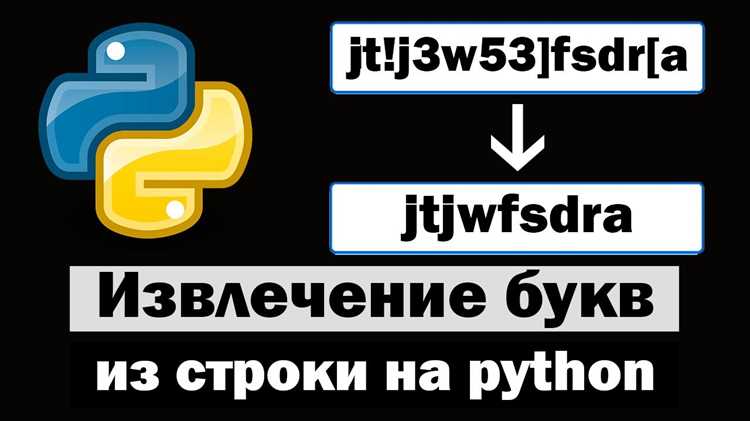
Для пропуска пробелов и специальных символов используют условие if внутри цикла:
text = "Привет, мир!"
for char in text:
if char.isalpha():
print(char)Метод isalpha() проверяет, является ли символ буквой, исключая пробелы, цифры и знаки пунктуации. Аналогично можно использовать isalnum() для букв и цифр или isspace() для работы только с пробелами.
Если требуется сохранить специальные символы, но отделить их визуально, можно добавлять форматирование:
for char in text:
if not char.isalpha():
print(f"[{char}]")
else:
print(char)| Позиция | Буква |
|---|---|
| 0 | P |
| 1 | y |
| 2 | t |
| 3 | h |
| 4 | o |
| 5 | n |
Код для генерации такой таблицы:
word = "Python"
print("<table border='1'>")
print("<tr><th>Позиция</th><th>Буква</th></tr>")
for i, char in enumerate(word):
print(f"<tr><td>{i}</td><td>{char}</td></tr>")
print("</table>")Дополнительно можно применять условное форматирование: выделять гласные, изменять цвет букв или добавлять классы CSS для визуального разделения. Например, для выделения гласных можно использовать условие if char.lower() in ‘аеёиоуыэюяaeiou’.