Содержание статьи

Для контроля текущих запросов в PostgreSQL используют представление pg_stat_activity, где отображаются pid, datname, usename, query и state. Отслеживание длительных запросов через поле query_start позволяет быстро выявлять узкие места при высокой нагрузке.
Использование EXPLAIN показывает план выполнения запроса с оценкой стоимости операций, а EXPLAIN ANALYZE добавляет фактическое время выполнения, что помогает выявлять операции с наибольшей задержкой. Для точной диагностики рекомендуется сравнивать оценочные и фактические показатели, особенно при сложных JOIN и агрегациях.
Статистика по всем запросам хранится в pg_stat_statements. Она содержит количество вызовов, общее и среднее время выполнения. Анализ этих данных позволяет идентифицировать наиболее ресурсоемкие запросы, корректировать индексы и оптимизировать структуры таблиц.
Для комплексного анализа полезно агрегировать данные по базе, пользователю и таблице. Практика показывает, что оптимизация 5–10% самых длительных запросов сокращает общую нагрузку на 40–60%, что особенно эффективно при параллельной обработке транзакций и высоком уровне конкуренции. Регулярное обновление статистики через ANALYZE обеспечивает актуальность планов выполнения.
Отслеживание текущих запросов с помощью pg_stat_activity
Для мониторинга выполняемых в PostgreSQL запросов используется системная представление pg_stat_activity. Оно содержит информацию о всех активных соединениях, включая идентификатор сессии pid, пользователя, базу данных, текущее состояние запроса и время его начала.
Базовый запрос для получения списка активных запросов выглядит так:
SELECT pid, usename, datname, state, query, query_start FROM pg_stat_activity;
Колонка state отражает текущее состояние сессии: active – выполняется запрос, idle – сессия без активного запроса, idle in transaction – открыта транзакция без выполнения запроса.
Для анализа долгих запросов применяют фильтрацию по времени выполнения. Например, чтобы найти запросы, выполняющиеся более 5 минут:
SELECT pid, usename, query, now() — query_start AS duration FROM pg_stat_activity WHERE state = ‘active’ AND now() — query_start > interval ‘5 minutes’;
Идентификаторы процессов (pid) позволяют при необходимости завершить проблемные запросы через команду pg_terminate_backend(pid). Это особенно полезно при блокировках или нагрузке на сервер.
Регулярный мониторинг pg_stat_activity помогает выявлять узкие места, контролировать длительные транзакции и оптимизировать нагрузку на PostgreSQL. Для автоматизации анализа используют скрипты или средства мониторинга, которые периодически собирают данные из этого представления.
Использование pg_stat_statements для сбора статистики запросов
Расширение pg_stat_statements позволяет собирать агрегированную статистику по выполнению SQL-запросов в PostgreSQL. Оно хранит данные о количестве вызовов, среднем и максимальном времени выполнения, количестве возвращённых строк и блокировках.
Для включения расширения необходимо выполнить команду CREATE EXTENSION pg_stat_statements; в базе данных и добавить в конфигурационный файл postgresql.conf параметр shared_preload_libraries = 'pg_stat_statements'. После перезапуска сервера статистика станет доступна.
Основная таблица для анализа – pg_stat_statements. Полезные поля: query – текст запроса, calls – количество выполнений, total_time – суммарное время выполнения, rows – количество обработанных строк, mean_time – среднее время выполнения.
Для выявления медленных запросов рекомендуется использовать запрос:
SELECT query, calls, total_time, mean_time, rows FROM pg_stat_statements ORDER BY total_time DESC LIMIT 20;
Для очистки накопленной статистики применяется SELECT pg_stat_statements_reset();. Регулярное использование pg_stat_statements позволяет выявлять горячие точки базы, оптимизировать индексы и переписывать неэффективные запросы, снижая нагрузку на сервер.
Фильтрация медленных и проблемных запросов
Для выявления медленных запросов используется представление pg_stat_statements. Основные показатели для анализа – total_exec_time, mean_exec_time и calls. Запросы с высокой средней длительностью или частыми вызовами чаще всего создают нагрузку на сервер.
Фильтрация выполняется с помощью сортировки и условий, например: ORDER BY mean_exec_time DESC LIMIT 20 покажет 20 самых медленных запросов. Для выявления аномально долгих запросов можно использовать порог по времени, например mean_exec_time > 500 (мс).
Дополнительно полезно анализировать частоту ошибок и блокировок. Столбцы calls и rows позволяют оценить эффективность запросов: большое количество вызовов при низком объёме выборки указывает на потенциально избыточные операции.
Для постоянного мониторинга рекомендуется создавать представления или отчёты, фильтрующие запросы по времени выполнения, числу вызовов и проценту от общего времени нагрузки. Это позволяет быстро выявлять проблемные запросы и корректировать индексы, оптимизировать условия фильтрации и пересматривать стратегию кэширования.
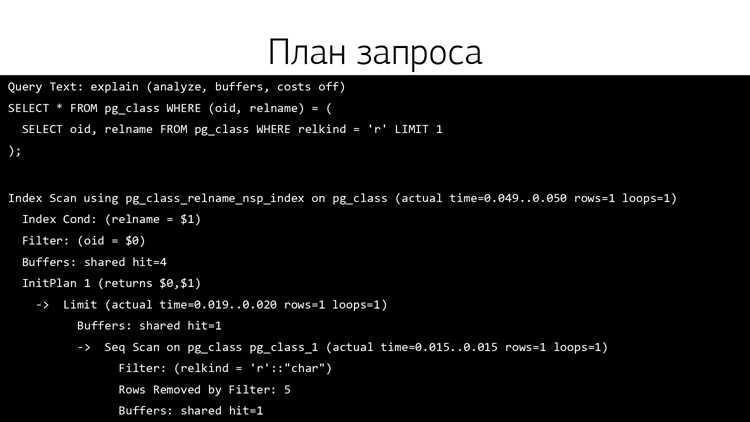
Использование EXPLAIN (ANALYZE) совместно с фильтрацией медленных запросов помогает выявить узкие места в плане выполнения, такие как последовательные сканирования больших таблиц, избыточные соединения или неэффективные фильтры.
Регулярный анализ и фильтрация запросов с максимальной длительностью и частотой позволяет сократить время отклика системы и минимизировать блокировки, что критично для высоконагруженных PostgreSQL-инсталляций.
Понимание планов выполнения через EXPLAIN и EXPLAIN ANALYZE

EXPLAIN отображает план выполнения запроса без его фактического выполнения, позволяя оценить стратегию доступа к данным. Он показывает последовательность операций, используемые индексы, порядок соединений и оценочные стоимости.
EXPLAIN ANALYZE выполняет запрос и возвращает реальные затраты времени на каждую операцию. Это позволяет выявить расхождения между планом и фактической производительностью.
Ключевые элементы плана выполнения:
- Seq Scan – последовательное сканирование таблицы. Часто указывает на отсутствие подходящего индекса.
- Index Scan – использование индекса для выборки данных. Эффективно при фильтрах с высокой селективностью.
- Nested Loop, Hash Join, Merge Join – методы соединения таблиц. Выбор зависит от объёма данных и наличия индексов.
- Cost – оценка ресурсов (начальная и общая). Сравнение cost с фактическим временем выявляет узкие места.
- Rows – количество строк, которое планировщик ожидает обработать. Значительное отклонение от фактического количества может указывать на устаревшие статистики.
Рекомендации по анализу:
- Использовать EXPLAIN для проверки предполагаемого плана перед оптимизацией.
- Применять EXPLAIN ANALYZE для измерения реальной нагрузки на каждую операцию.
- Сравнивать фактическое количество обработанных строк с оценочным и обновлять статистику через
ANALYZEпри значительных расхождениях. - Идентифицировать операции с наибольшим временем выполнения и проверять индексы или переписывать запросы для снижения нагрузки.
- Использовать опцию
BUFFERSв EXPLAIN ANALYZE для оценки использования памяти и чтения с диска.
Правильная интерпретация планов выполнения позволяет точечно оптимизировать запросы, снижая время отклика и нагрузку на сервер.
Идентификация блокировок и взаимных ожиданий
В PostgreSQL блокировки возникают при конкурирующем доступе к одним и тем же ресурсам. Для диагностики используют представления системного каталога pg_locks и динамическую информацию из pg_stat_activity. Основная цель – определить заблокированные процессы и процессы-«владельцы» блокировок.
Пример запроса для выявления текущих блокировок и взаимных ожиданий:
| Запрос | Описание |
|---|---|
SELECT blocked.pid AS blocked_pid, blocked.query AS blocked_query, blocking.pid AS blocking_pid, blocking.query AS blocking_query, blocked.wait_event_type, blocked.wait_event FROM pg_stat_activity blocked JOIN pg_locks blocked_locks ON blocked.pid = blocked_locks.pid JOIN pg_locks blocking_locks ON blocked_locks.locktype = blocking_locks.locktype AND blocked_locks.database IS NOT DISTINCT FROM blocking_locks.database AND blocked_locks.relation IS NOT DISTINCT FROM blocking_locks.relation AND blocked_locks.page IS NOT DISTINCT FROM blocking_locks.page AND blocked_locks.tuple IS NOT DISTINCT FROM blocking_locks.tuple AND blocked_locks.pid != blocking_locks.pid JOIN pg_stat_activity blocking ON blocking_locks.pid = blocking.pid WHERE NOT blocked_locks.granted; |
Для быстрого выявления циклических блокировок (deadlock) можно использовать системный журнал PostgreSQL, где фиксируются события deadlock detected. После выявления взаимных ожиданий следует оценить план транзакций, порядок блокировок и изоляцию транзакций, чтобы исключить повторение ситуации.
Рекомендации:
| Действие | Цель |
|---|---|
Анализ pg_locks и pg_stat_activity |
Выявить текущие блокировки и их владельцев |
| Проверка журнала на deadlock | Определить циклические ожидания и их участников |
| Оптимизация порядка транзакций | Минимизировать вероятность блокировок |
| Использование меньшей изоляции или SELECT FOR UPDATE NOWAIT | Снизить риск взаимных ожиданий |
Сбор и анализ логов запросов для диагностики

Для детального анализа производительности PostgreSQL важно настроить логирование запросов. Основные параметры конфигурации находятся в postgresql.conf: log_statement, log_duration, log_min_duration_statement. Значение log_statement позволяет фиксировать все или отдельные типы SQL-запросов, log_duration – время выполнения всех запросов, log_min_duration_statement – регистрацию запросов, превышающих заданный порог времени в миллисекундах.
Рекомендуется использовать log_min_duration_statement для выявления медленных запросов. Например, установка log_min_duration_statement = 500 регистрирует все запросы, выполняющиеся дольше 500 мс. Для диагностики блокировок и взаимных ожиданий включают log_lock_waits = on, что фиксирует ситуации ожидания блокировок.
Логи удобно анализировать с помощью внешних инструментов: pgBadger, pgFouine или специализированных скриптов на Python. Эти инструменты позволяют агрегировать статистику по запросам, выявлять частые и медленные запросы, определять пиковые периоды нагрузки и строить графики по времени выполнения.
При разборе логов следует обращать внимание на повторяющиеся медленные запросы, частые блокировки и нестандартные операции с большим количеством строк. Анализируя execution time и lock wait, можно оптимизировать индексы, пересмотреть JOIN и WHERE условия, снизить нагрузку на транзакции и уменьшить вероятность взаимных блокировок.
Для долговременного мониторинга рекомендуется хранить логи в структурированном формате (CSV или JSON), включить timestamp и session_id. Это упрощает фильтрацию, поиск проблемных сессий и построение отчетов по нагрузке на систему.
Вопрос-ответ:
Как быстро определить, какие запросы замедляют работу PostgreSQL?
Для выявления медленных запросов используют логирование и системные представления. В логах можно настроить параметр log_min_duration_statement, чтобы фиксировать только запросы, выполняющиеся дольше заданного времени. В pg_stat_statements отображаются агрегированные данные по каждому запросу: среднее время, количество вызовов, максимальная задержка. Сравнивая эти данные, можно понять, какие запросы требуют оптимизации.
Можно ли увидеть, какие запросы выполняются в данный момент?
Да, для этого используют представление pg_stat_activity. Оно показывает идентификатор сессии, пользователя, базу данных, состояние запроса и сам текст SQL. Дополнительно можно фильтровать по состоянию, например, видеть только активные запросы: SELECT pid, usename, query, state FROM pg_stat_activity WHERE state='active'; Это помогает отслеживать текущую нагрузку и блокировки.
Как понять, какие индексы реально используются запросами?
EXPLAIN и EXPLAIN ANALYZE показывают план выполнения запроса и указывают, используются ли индексы. EXPLAIN отображает предполагаемый план с оценкой количества строк, а EXPLAIN ANALYZE показывает фактическое время выполнения. Если план использует seq scan вместо index scan на таблице с большим количеством данных, это сигнализирует, что индекс либо отсутствует, либо выбран неэффективно.
Как определить источники блокировок и взаимных ожиданий?
Системные представления pg_locks и pg_stat_activity позволяют видеть, какие объекты заблокированы и какие сессии ожидают освобождения. Соединяя их, можно выявить циклические блокировки или конфликты между транзакциями. Например, запрос к pg_locks покажет тип блокировки и идентификатор сессии, а pg_stat_activity — текст выполняемого запроса. Это позволяет понять, какие операции вызывают задержки и устранить их корректировкой порядка транзакций.
Зачем использовать pg_stat_statements при анализе производительности?
pg_stat_statements собирает статистику по всем выполненным SQL-запросам: количество вызовов, среднее и максимальное время, обработанные строки. Эти данные помогают увидеть, какие запросы повторяются чаще всего и какие занимают больше всего времени. На основе этой информации можно оптимизировать индексы, переписать медленные запросы и снизить нагрузку на сервер.
Как можно отследить текущие запросы в PostgreSQL и понять, какие из них создают нагрузку на базу?
Для наблюдения за активными запросами используется системный представление pg_stat_activity. Оно показывает информацию о каждом подключении: идентификатор процесса, пользователя, базу данных, текущее состояние и выполняемую команду. Для выявления ресурсоёмких операций часто фильтруют запросы по длительности выполнения, используя поле state и query_start, чтобы определить, какие команды выполняются дольше обычного. Дополнительно можно сочетать это с EXPLAIN ANALYZE для отдельных запросов, чтобы увидеть их план выполнения и понять, какие операции занимают больше всего времени. Такой подход помогает выявлять медленные запросы и узкие места без остановки работы базы.