Содержание статьи

Knn Imputer применяется для восстановления пропусков в наборах данных путем использования информации о ближайших соседях. Метод вычисляет расстояние между строками по доступным признакам и заполняет отсутствующие значения средним или взвешенным значением соседей. Количество соседей напрямую влияет на точность: слишком мало может вызвать нестабильные результаты, слишком много – сгладить важные особенности данных.
Метрики расстояния определяют, какие строки будут считаться близкими. Наиболее распространены Евклидово, Манхэттенское и Минковское расстояния. Выбор метрики зависит от типа признаков: для числовых лучше подходит Евклидово, для категориальных часто используют гомогенность или специальные кодировки.
Перед применением Knn Imputer рекомендуется масштабирование данных, особенно если признаки имеют разные диапазоны. Без нормализации признаки с большими значениями будут доминировать при вычислении расстояния, что исказит результаты. Масштабирование можно выполнить с помощью MinMaxScaler или StandardScaler.
Метод подходит как для числовых, так и для категориальных данных, но для категориальных значений требуется предварительное кодирование, например, через OneHotEncoder или LabelEncoder. Это позволяет корректно вычислять расстояния между строками и сохранять структуру данных.
Knn Imputer полезен для анализа данных в бизнесе, медицине и науке, когда пропуски возникают случайно или системно. Практическое применение требует тестирования нескольких комбинаций соседей, метрик и масштабирования, чтобы выбрать вариант, который минимизирует искажения и сохраняет закономерности в данных.
Что такое Knn Imputer и для чего используется
Алгоритм особенно полезен, когда пропуски распределены случайно или частично зависят от других признаков. Он подходит как для числовых, так и для категориальных признаков, но категориальные значения необходимо предварительно кодировать.
Рекомендации по использованию:
| Параметр | Описание | Практический совет |
|---|---|---|
| n_neighbors | Количество ближайших соседей, учитываемых при заполнении | Для небольших наборов данных 3–5 соседей, для больших – 5–10 |
| metric | Метрика расстояния между строками | Евклидово для числовых, гомогенность или кодировка для категориальных |
| weights | Способ взвешивания соседей | uniform – одинаковый вес, distance – обратнопропорционально расстоянию |
| scaling | Масштабирование признаков перед вычислением расстояний | StandardScaler или MinMaxScaler для нормализации диапазонов |
Knn Imputer позволяет минимизировать искажения данных и сохранить статистические характеристики набора, что важно при построении моделей машинного обучения и анализе данных в реальных проектах.
Выбор числа соседей для заполнения пропусков
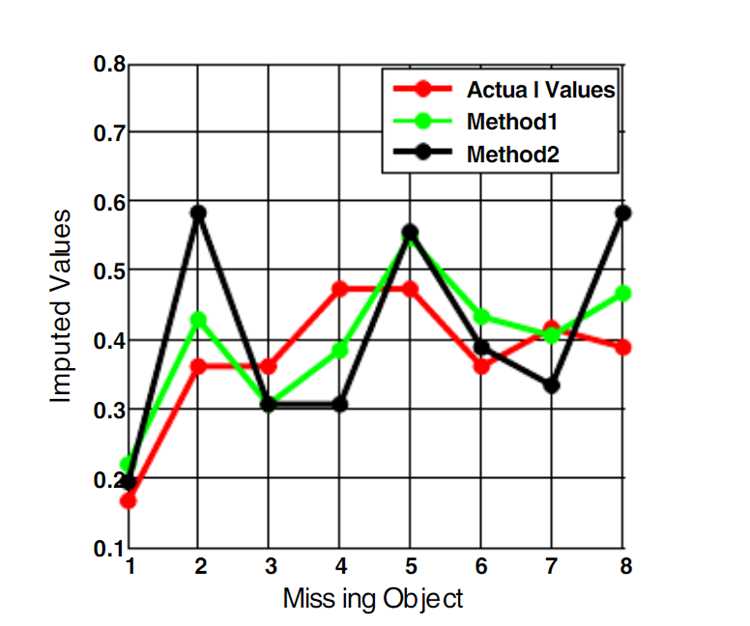
Параметр n_neighbors определяет, сколько ближайших строк будет учитываться при вычислении значения для пропуска. Малое число соседей (2–3) сохраняет локальные особенности данных, но увеличивает риск выбросов и нестабильных значений. Большое число (6–10 и более) сглаживает результат, снижая влияние отдельных наблюдений, но может теряться детализация закономерностей.
Для небольших наборов данных до 500 строк рекомендуется использовать 3–5 соседей. Для средних наборов (500–5000 строк) – 5–7, для больших – 7–10. Оптимальное число зависит от распределения признаков и плотности данных вокруг пропусков.
Рекомендуется проводить тестирование нескольких вариантов и оценивать результаты через метрики качества, например, среднеквадратичную ошибку или сравнение с известными контрольными значениями. При наличии категориальных признаков число соседей должно быть достаточным, чтобы охватить разнообразие категорий, иначе частота редких значений будет занижена.
В случае сильно разношерстных данных можно комбинировать несколько настроек: для признаков с высокой вариативностью выбирать больше соседей, для стабильных – меньше. Такой подход позволяет сохранить баланс между точностью и устойчивостью заполнения пропусков.
Метрики расстояния и их влияние на результат

Выбор метрики расстояния определяет, какие наблюдения считаются ближайшими соседями при заполнении пропусков. Наиболее часто используются Евклидово, Манхэттенское и Минковское расстояния. Евклидово подходит для числовых признаков с одинаковым масштабом, Манхэттенское – для признаков с разной динамикой и аномалиями, Минковское позволяет настраивать степень чувствительности к отклонениям через параметр p.
Евклидово расстояние вычисляет прямое «пространственное» отклонение и подходит для равномерно масштабированных признаков. Оно усиливает влияние больших числовых значений, поэтому перед применением рекомендуется масштабирование через StandardScaler или MinMaxScaler.
Манхэттенское расстояние суммирует абсолютные отклонения по каждому признаку, что делает метод более устойчивым к выбросам. Оно полезно при наличии признаков с различной дисперсией и несоизмеримыми величинами.
Минковское расстояние обобщает Евклидово и Манхэттенское через параметр p. При p=1 получается Манхэттен, при p=2 – Евклидово. Настройка p позволяет балансировать чувствительность к удаленным соседям, особенно при данных с разной плотностью распределения.
Для категориальных признаков стандартные метрики не применимы. В таких случаях используют кодирование (LabelEncoder или OneHotEncoder) и метрику гомогенности или расстояние Хэмминга. Неправильный выбор метрики может привести к смещению заполненных значений и искажению закономерностей в наборе данных.
Обработка категориальных и числовых данных
Числовые признаки можно использовать напрямую в Knn Imputer, но важно нормализовать значения для корректного вычисления расстояний. StandardScaler подходит при нормальном распределении, MinMaxScaler – для приведения данных к единому диапазону [0,1]. Масштабирование предотвращает доминирование признаков с большими величинами.
Категориальные признаки требуют кодирования. LabelEncoder заменяет категории на числовые метки, сохраняя уникальные значения, но чувствителен к порядку. OneHotEncoder создаёт бинарные столбцы для каждой категории, что обеспечивает равное влияние всех категорий при вычислении расстояния.
Для смешанных наборов данных числовые признаки масштабируют, категориальные кодируют, а затем объединяют. Важно проверять результат на выбросы: при высоком разбросе категориальных меток может понадобиться использование расстояния Хэмминга для категориальных столбцов отдельно, чтобы избежать искажения соседей.
При заполнении пропусков категориальные значения вычисляются как наиболее часто встречающиеся среди соседей, числовые – как среднее или взвешенное среднее. Такой подход сохраняет структуру данных и уменьшает вероятность введения несоответствий между признаками.
Пошаговый алгоритм заполнения пропусков Knn Imputer
2. Предварительная обработка данных: числовые признаки масштабируются через StandardScaler или MinMaxScaler, категориальные кодируются с помощью LabelEncoder или OneHotEncoder.
3. Выбор числа соседей и метрики: задается параметр n_neighbors и выбирается метрика расстояния (Евклидово, Манхэттенское, Минковское или Хэмминг для категориальных признаков).
4. Вычисление расстояний: для каждой строки с пропуском рассчитывается расстояние до всех остальных строк по выбранным признакам и метрике.
5. Определение ближайших соседей: сортировка расстояний и выбор k ближайших строк без пропусков по целевому признаку.
6. Заполнение пропусков: числовые значения заменяются средним или взвешенным средним соседей, категориальные – наиболее часто встречающимся значением среди соседей.
7. Проверка и корректировка: анализируются заполненные значения на предмет выбросов и несоответствий, при необходимости корректируется масштабирование или количество соседей.
Особенности масштабирования данных перед применением
Масштабирование данных необходимо для корректной работы Knn Imputer, так как алгоритм использует расстояния между строками. Без нормализации признаки с большими значениями будут иметь непропорциональное влияние на соседей.
Рекомендации по масштабированию:
- StandardScaler: центрирование признаков по среднему и масштабирование по стандартному отклонению. Подходит для признаков с нормальным распределением.
- MinMaxScaler: преобразует значения в диапазон [0,1], сохраняет относительные различия и применяется для признаков с разным масштабом.
- Для смешанных данных масштабирование применяют только к числовым признакам, категориальные кодируются отдельно.
- После масштабирования важно проверять распределение данных, чтобы исключить сжатие информации и потери вариативности.
Этап масштабирования особенно критичен при использовании Евклидового или Минковского расстояния. Манхэттенское расстояние менее чувствительно к масштабу, но нормализация улучшает стабильность заполнения пропусков и уменьшает влияние выбросов.
Практические примеры применения на реальных данных
В медицине Knn Imputer используется для восстановления пропусков в лабораторных анализах пациентов. Например, если у части пациентов отсутствуют значения уровня глюкозы, алгоритм заполняет их на основе ближайших пациентов с похожими возрастом, весом и показателями давления. Рекомендуется масштабировать числовые признаки и проверять результаты через контрольные выборки.
В бизнес-аналитике метод применяется для заполнения пропусков в данных о продажах и поведении клиентов. Если отсутствуют показатели количества покупок или рейтинги товаров, Knn Imputer использует соседние записи с похожими профилями покупателей. Для категориальных признаков важен правильный выбор кодирования и метрики.
В научных исследованиях алгоритм помогает восполнить недостающие данные при опросах и экспериментах. Например, пропущенные ответы на шкале удовлетворенности могут быть рассчитаны через k ближайших участников с сопоставимыми характеристиками. Проверка на устойчивость к выбросам позволяет избежать искажений итоговой статистики.
Для всех случаев важно тестировать несколько комбинаций числа соседей, метрик расстояния и методов масштабирования. Это позволяет подобрать настройки, которые минимизируют смещение данных и сохраняют внутренние закономерности набора.
Вопрос-ответ:
Что такое Knn Imputer и как он работает с пропусками?
Knn Imputer – это метод заполнения пропусков на основе k ближайших соседей. Алгоритм вычисляет расстояние между строками по доступным признакам и заменяет отсутствующие значения средним или наиболее часто встречающимся значением соседей. Он учитывает локальные закономерности и сохраняет структуру данных без удаления строк.
Как выбрать оптимальное количество соседей для заполнения?
Параметр n_neighbors определяет, сколько ближайших строк учитывается при заполнении. Для небольших наборов данных 3–5 соседей дают точные результаты, для средних – 5–7, для больших – 7–10. Малое число может вызвать нестабильность, большое – сглаживание локальных особенностей. Рекомендуется тестировать несколько вариантов и оценивать ошибки на контрольных данных.
Какая метрика расстояния подходит для разных типов данных?
Для числовых признаков обычно применяют Евклидово или Минковское расстояние, при этом важно масштабировать значения. Манхэттенское расстояние устойчиво к выбросам. Для категориальных признаков используют расстояние Хэмминга или кодирование через OneHotEncoder с последующим вычислением схожести. Неправильная метрика может привести к неверному определению соседей и искажению заполненных значений.
Нужно ли масштабировать данные перед применением Knn Imputer?
Да, масштабирование числовых признаков необходимо, так как алгоритм опирается на расстояния. Без нормализации признаки с большими значениями будут иметь чрезмерное влияние. Для нормализации используют StandardScaler для нормального распределения и MinMaxScaler для приведения значений к диапазону [0,1]. Категориальные признаки масштабированию не подлежат и кодируются отдельно.
Как Knn Imputer работает с категориальными и числовыми признаками одновременно?
Числовые признаки масштабируют, а категориальные кодируют через LabelEncoder или OneHotEncoder. При заполнении пропусков числовые значения заменяются средним или взвешенным средним соседей, а категориальные – наиболее частым значением. Такой подход позволяет корректно учитывать влияние разных типов признаков на выбор ближайших соседей.
Как Knn Imputer определяет, какие значения использовать для заполнения пропусков?
Knn Imputer вычисляет расстояние между строкой с пропущенным значением и всеми остальными строками по признакам, где данные присутствуют. Затем выбираются k ближайших соседей, и пропуск заполняется на основе этих соседей: для числовых признаков берется среднее или взвешенное среднее по расстоянию, для категориальных – наиболее часто встречающееся значение. Такой подход учитывает локальные зависимости и распределение данных, позволяя восстановить пропуски без удаления строк или применения простого усреднения по всему набору.