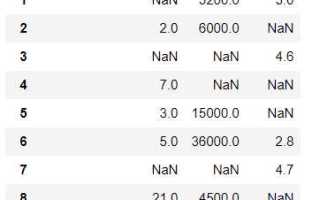
При работе с pandas часто возникает задача очистки данных: определённые значения в DataFrame могут мешать анализу или вычислениям. Например, числовой столбец может содержать значения -1 или 0, которые в контексте задачи нужно считать отсутствующими. Замена таких значений на NaN позволяет использовать встроенные методы pandas для подсчёта, фильтрации и агрегации без искажений.
Метод replace в pandas позволяет менять конкретные значения на NaN для одного столбца или сразу нескольких. Для сложных условий применяется метод loc с логическими выражениями, что даёт контроль над тем, какие строки затрагиваются. Например, можно заменить все отрицательные числа на NaN или строки с определёнными символами.
После замены значений на NaN важно понимать, как это влияет на дальнейшие операции: функции sum, mean и count учитывают пропуски, а методы dropna и fillna помогают корректировать DataFrame для анализа или экспорта. Планомерный подход к замене позволяет избежать ошибок в вычислениях и сохранять целостность исходных данных.
Загрузка данных в DataFrame перед заменой
Для начала работы с заменой значений на NaN необходимо корректно загрузить данные в pandas DataFrame. Если исходные данные находятся в CSV-файле, используется функция pd.read_csv() с указанием разделителя, кодировки и обработки пропусков. Например, pd.read_csv(‘data.csv’, sep=’,’, encoding=’utf-8′, na_values=[‘NA’, ‘n/a’]) автоматически интерпретирует заданные строки как NaN.
При работе с Excel-файлами применяется pd.read_excel(). Рекомендуется сразу указывать нужный лист через параметр sheet_name и задавать список значений, которые нужно считать отсутствующими, через na_values. Это упрощает последующую замену данных, снижая риск ошибки при ручной корректировке.
Для загрузки данных из словарей или списков достаточно создать DataFrame напрямую: pd.DataFrame(data). Важно заранее проверить типы столбцов и привести их к нужным, так как замена значений на NaN в числовых и строковых столбцах выполняется по-разному. Применение метода info() и head() помогает убедиться, что структура DataFrame соответствует требованиям к обработке.
Использование метода replace для замены конкретных значений
Метод replace в pandas позволяет заменить одно или несколько значений на NaN напрямую в DataFrame или конкретном столбце. Синтаксис простой и поддерживает словари для одновременной замены разных значений.
Примеры применения:
- Замена одного значения в столбце: df[‘возраст’] = df[‘возраст’].replace(-1, np.nan)
- Замена нескольких значений в одном столбце: df[‘баллы’] = df[‘баллы’].replace([0, -999], np.nan)
- Замена разных значений в нескольких столбцах через словарь:
df.replace({‘возраст’: -1, ‘баллы’: [0, -999]}, np.nan, inplace=True)
Рекомендации при использовании:
- Перед заменой проверять наличие значений через value_counts() или unique(), чтобы не пропустить редкие случаи.
- При массовой замене использовать словари для повышения читаемости кода и минимизации ошибок.
- Для сохранения исходного DataFrame можно применить параметр inplace=False и присвоить результат новой переменной.
Замена нескольких значений на NaN одновременно
В pandas можно заменить несколько значений на NaN сразу, что ускоряет обработку больших DataFrame и снижает риск ошибок. Для этого используют метод replace с передачей списка значений или словаря, где ключи – значения для замены, а значения словаря – np.nan.
Пример замены нескольких значений в столбце:
df['баллы'] = df['баллы'].replace([0, -1, -999], np.nan)Для разных столбцов можно использовать словарь:
df.replace({'возраст': [-1, 0], 'баллы': [-999, 0]}, np.nan, inplace=True)Для наглядности можно представить заменяемые значения в виде таблицы:
| Столбец | Значения до замены | Значения после замены |
|---|---|---|
| возраст | -1, 0, 25, 30 | NaN, NaN, 25, 30 |
| баллы | 0, -999, 10, 15 | NaN, NaN, 10, 15 |
Рекомендуется сначала проверить значения через unique(), чтобы не пропустить редкие варианты. После массовой замены DataFrame готов к дальнейшему анализу с корректным учётом пропусков.
Применение условий для замены по столбцу
Для замены значений на NaN по условию используется метод loc с логическим выражением. Это позволяет выбирать только те строки, которые соответствуют критериям, например отрицательные значения или строки с некорректными данными.
Пример замены отрицательных чисел на NaN в столбце возраст:
df.loc[df['возраст'] < 0, 'возраст'] = np.nanЗамена значений по сложным условиям с несколькими столбцами:
df.loc[(df['баллы'] < 0) | (df['возраст'] < 18), ['баллы', 'возраст']] = np.nanРекомендации:
- Использовать метод info() после замены для проверки типов и количества пропусков.
- Перед применением условий проверять данные через describe() и value_counts(), чтобы учесть все редкие значения.
- Для повторяющихся условий создавать отдельные логические переменные, чтобы код оставался читаемым и безопасным.
Замена строковых значений на NaN
В pandas строки с определёнными значениями можно заменить на NaN с помощью метода replace или условий через loc. Это полезно для обработки пропусков в текстовых данных, например, когда встречаются значения вроде «нет данных», «unknown» или пустые строки.
Пример замены конкретных строк в столбце город:
df['город'] = df['город'].replace(['нет данных', 'unknown', ''], np.nan)Использование условий позволяет гибко обрабатывать строки с шаблонами:
df.loc[df['город'].str.contains('неизвестно', na=False), 'город'] = np.nanРекомендации при работе со строками:
- Перед заменой проверять уникальные значения через unique() или value_counts(), чтобы не пропустить редкие варианты.
- При использовании str.contains() указывать na=False, чтобы избежать ошибок при наличии уже существующих NaN.
- После замены убедиться, что тип столбца соответствует задачам анализа: строки и NaN могут корректно сочетаться в object-типе.
Обработка отсутствующих значений после замены
После замены значений на NaN важно корректно обработать пропуски, чтобы анализ данных не был искажен. В pandas для этого применяются методы dropna и fillna, а также функции агрегирования, учитывающие NaN.
Пример удаления строк с пропусками в столбце баллы:
df.dropna(subset=['баллы'], inplace=True)Заполнение отсутствующих значений медианой или средним позволяет сохранить размер DataFrame без искажения статистики:
df['возраст'].fillna(df['возраст'].median(), inplace=True)Для категориальных данных удобно использовать значение по умолчанию или наиболее частое значение:
df['город'].fillna('Не указано', inplace=True)Рекомендации:
- Перед удалением или заполнением проверять долю пропусков через isna().sum(), чтобы не потерять важные данные.
- Выбирать метод обработки пропусков в зависимости от типа столбца и целей анализа: числовые данные – медиана или среднее, категориальные – модальный элемент или placeholder.
- После обработки использовать info() для проверки количества оставшихся пропусков.
Сохранение изменений в новый DataFrame или файл
После замены значений на NaN данные можно сохранить для дальнейшего анализа или экспорта. Сохранять изменения можно либо в новый DataFrame, либо напрямую в файл.
Создание нового DataFrame без изменения исходного:
df_new = df.copy()Сохранение DataFrame в CSV-файл:
df.to_csv('data_cleaned.csv', index=False, encoding='utf-8')Сохранение в Excel с указанием листа:
df.to_excel('data_cleaned.xlsx', sheet_name='Лист1', index=False)Рекомендации при сохранении:
- Использовать index=False, чтобы не сохранять индекс, если он не нужен в анализе.
- Проверять кодировку при экспорте CSV, особенно если в данных есть кириллица или специальные символы.
- Для больших файлов Excel использовать openpyxl или xlsxwriter как движок записи.
- При создании копии DataFrame убедиться, что copy() применён до внесения изменений, чтобы сохранить исходный вариант данных.
Вопрос-ответ:
Как заменить одно конкретное значение на NaN в столбце DataFrame?
Для замены одного значения используется метод replace. Например, чтобы заменить -1 на NaN в столбце возраст, применяется команда: df[‘возраст’] = df[‘возраст’].replace(-1, np.nan). Это изменит только указанный столбец, не затрагивая другие данные.
Можно ли одновременно заменить несколько значений на NaN в разных столбцах?
Да, для этого удобно использовать словарь в методе replace, где ключи — названия столбцов, а значения — список заменяемых значений. Например: df.replace({‘возраст’: [-1, 0], ‘баллы’: [0, -999]}, np.nan, inplace=True). Такой подход позволяет заменять разные значения сразу в нескольких столбцах.
Как заменить значения на NaN по условию, например все отрицательные числа?
Применяется метод loc с логическим выражением. Например, чтобы заменить все отрицательные значения в столбце баллы: df.loc[df[‘баллы’] < 0, ‘баллы’] = np.nan. Для сложных условий можно объединять несколько выражений через оператор | или &.
Каким образом обрабатывать строковые значения, которые нужно считать отсутствующими?
Строковые значения заменяются на NaN через replace или условие с str.contains. Например, df[‘город’] = df[‘город’].replace([‘нет данных’, ‘unknown’, »], np.nan) или df.loc[df[‘город’].str.contains(‘неизвестно’, na=False), ‘город’] = np.nan. Так данные становятся единообразными для дальнейшего анализа.
Что делать с пропусками после замены значений на NaN?
После замены можно удалить строки с NaN через dropna или заполнить их определёнными значениями с помощью fillna. Например, df[‘возраст’].fillna(df[‘возраст’].median(), inplace=True) заменит пропуски медианой, а df[‘город’].fillna(‘Не указано’, inplace=True) добавит текстовый placeholder для категориального столбца.
Как заменить в DataFrame сразу несколько значений на NaN и при этом сохранить исходные данные?
Чтобы заменить несколько значений на NaN без изменения исходного DataFrame, можно создать его копию через copy(), а затем применять метод replace или loc. Например: df_new = df.copy() создает новый DataFrame, после чего можно заменить значения: df_new.replace({‘возраст’: [-1, 0], ‘баллы’: [0, -999]}, np.nan, inplace=True). Такой подход сохраняет исходный DataFrame без изменений, а новый содержит пропуски, готовые к анализу или дальнейшей обработке.