Содержание статьи

В PHP строки представляют собой последовательность байтов, что позволяет работать с ними как с массивами символов. Для большинства задач достаточно стандартной функции str_split, которая преобразует строку в массив по одному символу. Она поддерживает указание длины сегмента, что удобно для разбиения на блоки, а не только на одиночные символы.
При работе с многобайтовыми кодировками, такими как UTF-8, стандартные функции могут обрезать символы некорректно. В этом случае на помощь приходит функция mb_str_split, которая корректно разделяет строку на символы любой длины, включая эмодзи и специальные символы, сохраняя исходную кодировку.
Для задач, где нужна фильтрация или обработка отдельных символов по шаблону, используют регулярные выражения через функцию preg_split. Она позволяет разрезать строку по конкретным условиям и сразу возвращает массив готовых элементов.
Также есть метод с циклом и доступом к символам по индексу через квадратные скобки. Этот подход полезен, если требуется динамическая обработка каждого символа без создания дополнительных массивов. Он работает для ASCII и простых UTF-8 символов, но для сложных многобайтовых символов предпочтительнее mb_str_split.
Выбор способа зависит от кодировки строки, размера данных и задачи. Для коротких ASCII строк достаточно str_split, для длинных UTF-8 строк или символов нестандартной длины – mb_str_split, а для фильтрации или сложного разбиения – preg_split. Это позволяет минимизировать ошибки и контролировать результат на каждом этапе.
Использование функции str_split для простого разбиения строки

Функция str_split разбивает строку на массив символов или блоков заданной длины. Синтаксис прост: str_split(string $string, int $length = 1). Если не указывать $length, строка делится на отдельные символы по одному. Например, str_split(‘PHP’) вернёт массив [‘P’, ‘H’, ‘P’].
Параметр $length позволяет создавать массив блоков фиксированной длины. Например, str_split(‘123456’, 2) вернёт [’12’, ’34’, ’56’], что удобно для обработки последовательностей данных или числовых кодов.
Функция работает только с однобайтовыми кодировками. Для ASCII строк она точна и не требует дополнительных проверок. Для UTF-8 символов с несколькими байтами результат может быть некорректным, так как каждый байт интерпретируется как отдельный элемент.
str_split возвращает массив, который можно сразу использовать в циклах foreach, передавать в функции сортировки или фильтрации. Это упрощает обработку символов без ручного доступа через индексы и позволяет избегать ошибок при разбиении длинных строк.
Преобразование строки в массив через оператор spread (…)

В PHP начиная с версии 8.1 можно использовать оператор spread (…) для преобразования строки в массив символов. Он автоматически разделяет строку на отдельные элементы при присвоении массиву.
Пример использования:
- $chars = […’PHP’]; создаст массив [‘P’, ‘H’, ‘P’].
- Оператор работает только с однобайтовыми символами, поэтому для ASCII строк результат точный.
- Можно комбинировать с другими массивами: $result = […$prefix, …’ABC’, …$suffix];
Преимущество метода в краткости и читабельности кода. Он удобен, если нужно быстро разбить строку без вызова дополнительных функций и сразу объединять с другими массивами.
Ограничения:
- Не поддерживает корректную обработку многобайтовых UTF-8 символов. Для эмодзи или кириллицы лучше использовать mb_str_split.
- Работает только с литералами или переменными строкового типа. Попытка использовать объект, реализующий __toString(), может вызвать ошибку без явного приведения к строке.
Разбиение строки на символы с помощью preg_split
Функция preg_split позволяет разбивать строку на символы с использованием регулярных выражений. Это особенно полезно для UTF-8 строк или случаев, когда требуется фильтровать определённые символы.
Пример базового разбиения строки на отдельные символы:
$chars = preg_split(‘//u’, $string, -1, PREG_SPLIT_NO_EMPTY);
Объяснение параметров:
- ‘//u’ – шаблон с модификатором u для корректной работы с многобайтовыми символами.
- -1 – отсутствие ограничения на количество элементов массива.
- PREG_SPLIT_NO_EMPTY – исключает пустые строки из результата.
Preg_split позволяет одновременно разрезать строку и отфильтровать ненужные символы. Например, preg_split(‘/[^\p{L}]/u’, $string, -1, PREG_SPLIT_NO_EMPTY) вернёт только буквы, игнорируя пробелы и цифры.
Метод подходит для сложных текстов, включая кириллицу, эмодзи и специальные символы, и обеспечивает точное разбиение там, где str_split или оператор spread могут давать ошибку.
Получение отдельного символа строки через цикл и индексы

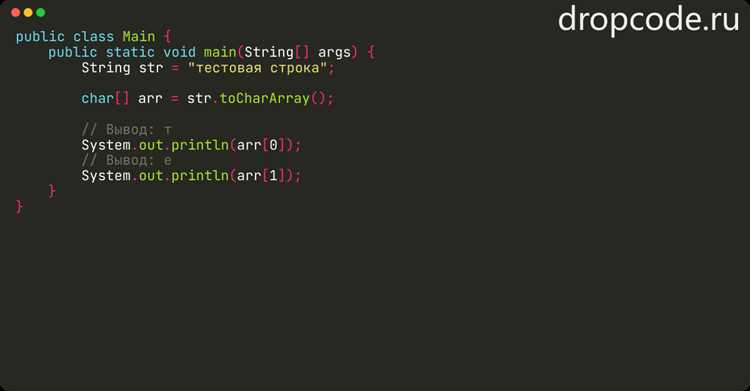
В PHP строки можно рассматривать как массивы символов, что позволяет получать каждый символ по индексу. Для этого используется синтаксис `$string[$i]`, где `$i` – номер позиции символа, начиная с нуля.
Пример: если `$text = «Пример»;`, то `$text[0]` вернёт `П`, а `$text[3]` – `е`. Такой подход удобен для последовательной обработки каждого символа.
Для перебора всех символов строки применяется цикл `for`, где в качестве границы используют функцию `strlen($string)`, возвращающую длину строки в символах. Это обеспечивает корректный обход, независимо от длины строки.
Пример кода:
$text = "Пример";
$length = strlen($text);
for ($i = 0; $i < $length; $i++) {
echo $text[$i] . "\n";
}
Если требуется работать с многобайтовыми символами, например кириллицей в UTF-8, стандартный индексный доступ может вернуть некорректные значения. В таких случаях используют функцию `mb_strlen()` для длины строки и `mb_substr()` для получения символа по позиции.
Пример для UTF-8:
$text = "Пример";
$length = mb_strlen($text, "UTF-8");
for ($i = 0; $i < $length; $i++) {
echo mb_substr($text, $i, 1, "UTF-8") . "\n";
}
Использование цикла с индексами позволяет применять фильтры, замену или подсчёт отдельных символов без создания дополнительных массивов, что повышает производительность при обработке длинных строк.
Работа с многобайтовыми строками через mb_str_split

Функция `mb_str_split()` позволяет разбивать строки с многобайтовыми символами на массив отдельных символов, корректно обрабатывая UTF-8 и другие кодировки. Она устраняет ошибки, возникающие при использовании обычного индексного доступа или `str_split()` с кириллицей и эмодзи.
Синтаксис: mb_str_split(string $string, int $split_length = 1, ?string $encoding = null): array. Параметр `$split_length` задаёт длину фрагмента, `$encoding` – кодировку, по умолчанию используется `mb_internal_encoding()`.
Пример для UTF-8 строки:
$text = "Привет";
$chars = mb_str_split($text, 1, "UTF-8");
foreach ($chars as $char) {
echo $char . "\n";
}
Функция также позволяет разбивать строку на блоки длиной больше одного символа, например: mb_str_split($text, 2, "UTF-8") вернёт массив с парами символов.
Для обработки текста с эмодзи или специфическими символами mb_str_split гарантирует, что каждый элемент массива соответствует реальному визуальному символу, что важно при подсчёте длины, замене и анализе текста.
Использование mb_str_split упрощает манипуляции с многобайтовыми строками и предотвращает потерю данных при работе с кириллицей и другими языками, где символ занимает более одного байта.
Сравнение подходов для ASCII и UTF-8 символов

В PHP методы разбиения строки зависят от типа символов. Для ASCII можно использовать индексный доступ и `str_split()`, для UTF-8 требуется поддержка многобайтовых символов через `mb_*` функции. Ниже приведено сравнение основных подходов.
| Метод | Подходит для | Пример | Особенности |
|---|---|---|---|
| Индексный доступ ($string[$i]) | ASCII | $text = "Hello"; echo $text[1]; // e |
Простая работа, высокая производительность, не поддерживает многобайтовые символы |
| str_split() | ASCII | $chars = str_split("Hello"); |
Возвращает массив символов, не подходит для UTF-8, ошибки при многобайтовых символах |
| mb_substr() + цикл | UTF-8, кириллица, эмодзи | mb_substr($text, $i, 1, "UTF-8") |
Позволяет безопасно получать отдельные символы, требует вычисления длины через mb_strlen() |
| mb_str_split() | UTF-8, кириллица, эмодзи | $chars = mb_str_split("Привет", 1, "UTF-8"); |
Разбивает строку на символы или блоки, корректно обрабатывает многобайтовые символы |
Для ASCII достаточно индексного доступа или `str_split()`. Для UTF-8 рекомендуется использовать `mb_str_split()` или цикл с `mb_substr()`, чтобы избежать искажений символов и корректно работать с длиной строки.
Вопрос-ответ:
Как получить отдельный символ строки в PHP через цикл?
В PHP строки можно рассматривать как массивы символов. Для получения отдельного символа используется индексный доступ: $string[$i]. Чтобы пройтись по всей строке, применяется цикл for с границей, равной длине строки, вычисляемой функцией strlen($string). Например, для $text = «Привет»:for ($i = 0; $i < strlen($text); $i++) { echo $text[$i]; }. Такой подход работает корректно для ASCII символов.
Почему индексный доступ не подходит для кириллицы и эмодзи?
Индексный доступ в PHP работает с байтами, а не с визуальными символами. В UTF-8 символы кириллицы и эмодзи занимают несколько байт, поэтому $string[$i] может вернуть неполный символ или случайный набор байтов. Для работы с многобайтовыми строками используют функции mb_substr() и mb_str_split(), которые учитывают кодировку и возвращают корректные символы.
Как использовать mb_str_split для разбиения строки на символы?
Функция mb_str_split() принимает три параметра: строку, длину фрагмента и кодировку. Для разбиения на отдельные символы длина фрагмента равна 1, кодировка задаётся явно, например, "UTF-8". Пример: $chars = mb_str_split("Привет", 1, "UTF-8"); foreach ($chars as $char) { echo $char; }. Это безопасный способ работы с кириллицей и эмодзи без потери символов.
Можно ли использовать str_split для UTF-8 строк?
str_split разделяет строку на массив символов, но учитывает только байты, а не реальные символы. Для ASCII это работает корректно, но для UTF-8 кириллица и эмодзи будут разделены некорректно, и массив может содержать части символов. Для таких случаев mb_str_split или комбинация mb_substr с циклом гарантируют правильное разбиение строки.
Как пройтись по строке с эмодзи и подсчитать количество символов?
Для строк с многобайтовыми символами длина строки вычисляется через mb_strlen($string, "UTF-8"), а отдельные символы получают через mb_substr($string, $i, 1, "UTF-8"). Пример подсчёта количества символов: $length = mb_strlen($text, "UTF-8"); echo $length;. Такой метод позволяет корректно обрабатывать кириллицу и эмодзи, не искажая символы.