Содержание статьи

Git хранит данные в виде набора объектов, каждый из которых имеет уникальный идентификатор SHA-1. Основные типы объектов – коммиты, деревья и блобы. Коммиты фиксируют состояние репозитория и содержат ссылки на соответствующие деревья, которые представляют структуру каталогов. Блобы отвечают за хранение содержимого файлов без метаданных.
Изменения в рабочем каталоге сначала фиксируются в индексе (staging area), где Git создаёт новые объекты или обновляет существующие. Индекс служит промежуточным хранилищем между рабочей директорией и репозиторием, позволяя точно контролировать, какие изменения попадут в коммит.
Ветки и теги в Git реализованы как ссылки на коммиты. HEAD указывает на текущую позицию пользователя в истории, а система ссылок позволяет быстро переключаться между состояниями репозитория. Каждый коммит хранит ссылку на родительский коммит, что формирует цепочку изменений без дублирования данных.
Git использует pack-файлы для хранения большого количества объектов. При этом идентичные объекты не копируются, а ссылки на них повторно используются, что значительно сокращает размер репозитория. Такая организация данных обеспечивает надёжное хранение и быстрый доступ к истории изменений.
Что такое объекты Git и как они структурируют данные
Каждый объект неизменяем: при изменении файла Git создаёт новый blob и обновляет связанные tree и commit объекты. Это обеспечивает точную идентификацию состояния репозитория в любой момент времени. Структура объектов формирует граф, где commit-объекты связаны с родительскими, а tree-объекты описывают вложенные каталоги, позволяя быстро восстанавливать любую версию файлов.
Для оптимизации хранения Git использует индексацию объектов и pack-файлы. Pack-файлы объединяют несколько объектов, сокращая объём данных и ускоряя доступ. При работе с репозиторием рекомендуется регулярно выполнять git gc, чтобы уплотнять объекты и уменьшать фрагментацию. Понимание структуры объектов помогает управлять историей и предотвращает потерю данных при сложных слияниях.
Разница между коммитами, деревьями и блобами
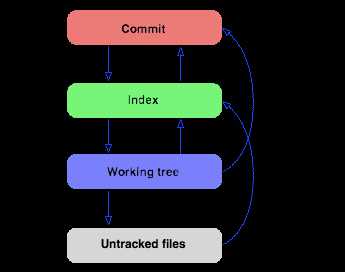
Tree описывает структуру каталогов и связывает имена файлов с соответствующими blob-объектами. Дерево может содержать ссылки на другие tree-объекты, формируя иерархию директорий. Это позволяет Git быстро восстанавливать состояние файловой системы репозитория на момент конкретного коммита.
Commit фиксирует состояние репозитория, указывая на корневое дерево и родительские коммиты. Коммит хранит метаданные: автора, дату и сообщение. Он образует цепочку истории изменений, позволяя отслеживать последовательность правок и возвращаться к любому состоянию репозитория.
Рекомендация: при анализе репозитория ориентируйтесь на commit как на точку фиксации состояния, tree – как на карту директорий, а blob – как на содержимое файлов. Такая структура минимизирует дублирование данных и упрощает восстановление истории.
Как Git использует хеши SHA-1 для идентификации объектов
Git присваивает каждому объекту уникальный идентификатор с помощью алгоритма SHA-1, который вычисляется на основе содержимого объекта и его типа. Это означает, что два объекта с одинаковым содержимым получат одинаковый хеш, а любое изменение в файле создаёт новый хеш.
Хеш служит ссылкой на объект в репозитории и используется для построения всех структур Git: коммитов, деревьев и blob-объектов. Commit хранит SHA-1 родительского коммита, что формирует неизменяемую цепочку истории. Tree ссылается на blob-объекты через их хеши, обеспечивая точное соответствие файловой структуре.
Использование SHA-1 позволяет Git быстро проверять целостность данных: при загрузке или извлечении объекта Git вычисляет его хеш и сравнивает с записанным значением. Рекомендация: избегать прямого редактирования объектов в каталоге .git, так как это нарушает хеш-ссылки и может привести к повреждению истории.
Роль индекса (staging area) в хранении изменений

Индекс Git, или staging area, служит промежуточным слоем между рабочей директорией и репозиторием. Он хранит информацию о том, какие изменения будут включены в следующий коммит. Индекс облегчает точный контроль над историей и позволяет собирать изменения из разных файлов в один коммит.
Основные функции индекса:
- Фиксация изменений перед коммитом без немедленного сохранения в истории.
- Обеспечение согласованности между файлами рабочей директории и репозиторием.
- Возможность частичного добавления изменений с помощью git add -p, что создаёт более осмысленные коммиты.
Рекомендации по использованию индекса:
- Добавляйте только завершённые изменения, чтобы коммит отражал логическую единицу работы.
- Регулярно проверяйте состояние индекса через git status перед фиксацией коммита.
- Используйте staged файлы для разделения больших изменений на несколько коммитов для удобства анализа истории.
Индекс играет ключевую роль в управлении данными Git, позволяя контролировать, какие объекты создаются и как они интегрируются в структуру репозитория.
Механизм ссылок: ветки, теги и HEAD

Git использует ссылки для отслеживания состояния репозитория. Основные виды ссылок:
- Ветки – указывают на последний коммит определённой линии разработки. Каждая ветка хранит SHA-1 коммита, на который она указывает.
- Теги – фиксированные указатели на конкретные коммиты. Они часто используются для обозначения версий или релизов.
- HEAD – специальная ссылка, которая показывает текущую позицию пользователя в истории репозитория. Обычно HEAD указывает на ветку или напрямую на коммит.
Рекомендации по работе с механизмом ссылок:
- Используйте ветки для изоляции новых функций или исправлений, чтобы не нарушать основную историю.
- Создавайте теги для релизов и ключевых версий, чтобы легко идентифицировать стабильные состояния репозитория.
- Следите за состоянием HEAD с помощью git status, чтобы избежать нежелательного коммита в неправильную ветку.
Система ссылок позволяет Git управлять историей без дублирования данных, обеспечивая быстрый переход между коммитами и контроль за версионированием.
Принцип работы Git с удалёнными репозиториями и push/pull
Удалённый репозиторий в Git хранит копию данных, доступную другим пользователям. Основные операции для синхронизации:
- git push – отправляет коммиты из локальной ветки в удалённую. Git передаёт только новые объекты (blobs, trees, commits), что экономит трафик и ускоряет процесс.
- git pull – получает изменения из удалённого репозитория и автоматически выполняет слияние с текущей веткой. По умолчанию используется комбинация fetch + merge.
- git fetch – загружает объекты и ссылки без слияния, позволяя изучить изменения перед интеграцией.
Рекомендации по работе с удалёнными репозиториями:
- Регулярно синхронизируйте локальную ветку с удалённой через git fetch или git pull, чтобы избегать конфликтов.
- Перед push проверяйте актуальность ветки и разрешайте конфликты локально.
- Используйте отдельные ветки для новых функций, чтобы минимизировать риск слияния с основной веткой на сервере.
Git передаёт данные на уровне объектов, что позволяет быстро интегрировать изменения без пересылки всего репозитория, обеспечивая точность и консистентность истории.
Использование pack-файлов для хранения больших объёмов данных
Pack-файлы в Git объединяют множество объектов в один сжатый файл для экономии пространства и ускорения передачи данных. При добавлении новых коммитов Git может упаковывать объекты, минимизируя дублирование и сохраняя только уникальные данные.
Основные характеристики pack-файлов:
| Свойство | Описание |
|---|---|
| Сжатие | Объекты хранятся в формате delta, где сохраняются только различия между похожими файлами. |
| Идентификация | Каждый объект внутри pack-файла имеет SHA-1, позволяющий проверять целостность данных. |
| Передача | При push/pull Git пересылает pack-файлы, что сокращает объём передаваемых данных. |
| Оптимизация | Команда git gc уплотняет объекты и создает новые pack-файлы, уменьшая фрагментацию. |
Рекомендации:
- Регулярно выполнять git gc для поддержания компактности репозитория.
- При работе с большими файлами рассматривать возможность использования Git LFS, чтобы pack-файлы не увеличивались чрезмерно.
- Следить за размером репозитория и периодически проверять наличие старых или редко используемых объектов, чтобы оптимизировать хранение.
Как Git оптимизирует хранение и предотвращает дублирование объектов
Git использует механизм неизменяемых объектов и идентификаторов SHA-1 для предотвращения дублирования. Каждый blob, tree или commit хранится один раз; если содержимое повторяется, Git не создаёт новый объект, а использует ссылку на существующий.
Оптимизация достигается с помощью pack-файлов, которые объединяют несколько объектов и сохраняют только различия между ними (deltas). Это сокращает размер репозитория и ускоряет операции push/pull.
Дополнительные механизмы:
- Индексирование – Git хранит ссылки на объекты в индексе, что ускоряет поиск и предотвращает повторное создание идентичных объектов.
- Garbage Collection – команда git gc удаляет ненужные объекты и уплотняет pack-файлы, минимизируя фрагментацию.
- Delta Compression – при сжатии Git сохраняет только различия между версиями файлов, снижая дублирование данных на уровне содержимого.
Рекомендации: при работе с большими репозиториями регулярно выполнять git gc и избегать ручного копирования объектов, чтобы не нарушать уникальность и целостность данных.
Вопрос-ответ:
Что такое объекты Git и как они используются в репозитории?
Объекты Git — это базовые единицы хранения данных: blob для содержимого файлов, tree для структуры каталогов, commit для фиксации состояния репозитория и tag для ссылок на коммиты. Каждый объект имеет уникальный идентификатор SHA-1, который позволяет Git точно отслеживать изменения и строить историю без дублирования данных.
В чём разница между коммитами, деревьями и блобами?
Blob хранит содержимое файла без метаданных, tree описывает структуру каталогов и связывает имена файлов с blob-объектами, а commit фиксирует состояние репозитория, указывая на корневое дерево и родительские коммиты. Это разделение позволяет Git быстро восстанавливать состояние файловой системы и отслеживать изменения на уровне отдельных файлов и каталогов.
Как Git использует хеши SHA-1 для идентификации объектов?
Каждый объект получает уникальный хеш SHA-1, вычисленный по содержимому и типу объекта. Это обеспечивает точную идентификацию и проверку целостности данных: при любой модификации создаётся новый хеш. Commit хранит SHA-1 родительского коммита, tree ссылается на blob-объекты через их хеши, что формирует граф изменений.
Для чего нужен индекс (staging area) и как он влияет на коммиты?
Индекс хранит изменения перед фиксацией в коммит. Он позволяет выбрать, какие файлы или их части будут включены в коммит, создавая более точную историю. Команда git add добавляет файлы в индекс, а git commit фиксирует именно их. Это упрощает управление изменениями и предотвращает случайное включение незавершённых правок.
Как Git предотвращает дублирование данных и оптимизирует хранение?
Git хранит каждый объект один раз и использует ссылки на существующие объекты при повторном содержимом. Pack-файлы объединяют объекты и применяют delta-сжатие, сохраняя только различия между версиями. Команда git gc уплотняет объекты и удаляет ненужные, уменьшая размер репозитория и ускоряя работу с ним.
Как Git хранит историю изменений без дублирования данных?
Git использует объекты с уникальными хешами SHA-1. Каждый blob, tree и commit создаются один раз: если содержимое повторяется, Git не создаёт новый объект, а использует ссылку на существующий. Pack-файлы дополнительно объединяют объекты и применяют delta-сжатие, храня только различия между версиями, что сокращает объём данных и ускоряет работу с репозиторием.
Как индекс (staging area) помогает управлять изменениями перед коммитом?
Индекс позволяет выбрать, какие изменения попадут в следующий коммит. Файлы и отдельные фрагменты добавляются в индекс с помощью git add. Команда git commit фиксирует только то, что находится в индексе, что даёт точный контроль над историей. Это полезно для разделения больших правок на логические коммиты и предотвращает случайное включение незавершённых изменений.