Содержание статьи

При работе с текстовыми данными в C часто возникает необходимость определить, в какой кодировке хранится строка. От правильного распознавания зависит корректность обработки символов, особенно при использовании UTF-8, Windows-1251 или ISO-8859-1.
Для анализа строки можно проверять байтовые последовательности на соответствие определённым шаблонам кодировок. Например, UTF-8 имеет строгие правила формирования многобайтовых символов, что позволяет выявлять несоответствия и исключать ошибки при конверсии.
Стандартные функции C, такие как strlen и memcpy, помогают получить длину строки и скопировать данные, но не могут определить кодировку напрямую. Для этого применяют анализ символов и проверку диапазонов байтов, а также сторонние библиотеки вроде iconv или uchardet.
Знание точной кодировки важно при чтении файлов, работе с сетевыми протоколами и взаимодействии с внешними API. Ошибки кодировки приводят к некорректному отображению текста и потенциальным сбоям в обработке данных.
Определение кодировки по байтам и символам
Кодировка строки напрямую связана с тем, как символы представлены в виде байтов. Анализ отдельных байтов и их последовательностей позволяет определить тип кодировки без внешних библиотек.
Основные подходы к анализу:
- Проверка диапазонов байтов: для ASCII допустимы значения от 0x00 до 0x7F. Любые байты за пределами этого диапазона указывают на использование расширенных кодировок, таких как UTF-8 или Windows-1251.
- Идентификация многобайтовых символов UTF-8: первый байт многобайтового символа всегда имеет старшие биты, соответствующие маске 110xxxxx, 1110xxxx или 11110xxx. Последующие байты должны соответствовать шаблону 10xxxxxx.
- Сравнение последовательностей с известными таблицами кодировок: для Windows-1251 каждый байт в диапазоне 0xC0–0xFF соответствует конкретной кириллической букве.
Практические рекомендации при проверке строк в C:
- Пройтись по каждому байту строки и зафиксировать байты, выходящие за диапазон ASCII.
- Если встречены последовательности, соответствующие правилам UTF-8, считать строку UTF-8. В противном случае проверять соответствие таблице Windows-1251 или ISO-8859-1.
- Использовать unsigned char при обработке байтов, чтобы корректно сравнивать значения выше 0x7F.
- В случае несоответствия всех шаблонов рекомендуется отметить строку как неопределённой и применить конвертацию с ручной проверкой.
Использование стандартных библиотек для анализа строк
Стандартная библиотека C предоставляет функции для работы с массивами байтов и символами, которые помогают анализировать строки перед определением кодировки.
Ключевые функции для анализа:
- strlen – возвращает длину строки до первого нулевого байта. Позволяет оценить размер данных перед проверкой кодировки.
- memcpy и memmove – копируют байтовые последовательности без интерпретации символов. Используются для временного хранения фрагментов строки при анализе.
- strncmp и memcmp – сравнивают байтовые последовательности. Помогают выявлять характерные шаблоны для конкретных кодировок.
- isalpha, isdigit и другие функции ctype.h – позволяют классифицировать символы ASCII, что важно для отделения базового текста от расширенных кодировок.
Рекомендации по применению:
- Использовать unsigned char при обработке байтов выше 127, чтобы избежать некорректных сравнений.
- Сначала анализировать байты на соответствие ASCII, затем проверять многобайтовые последовательности UTF-8 или диапазоны Windows-1251.
- Комбинировать функции memcmp и isalpha для выявления специфических символов, характерных для конкретной кодировки.
Проверка UTF-8 и других популярных кодировок вручную
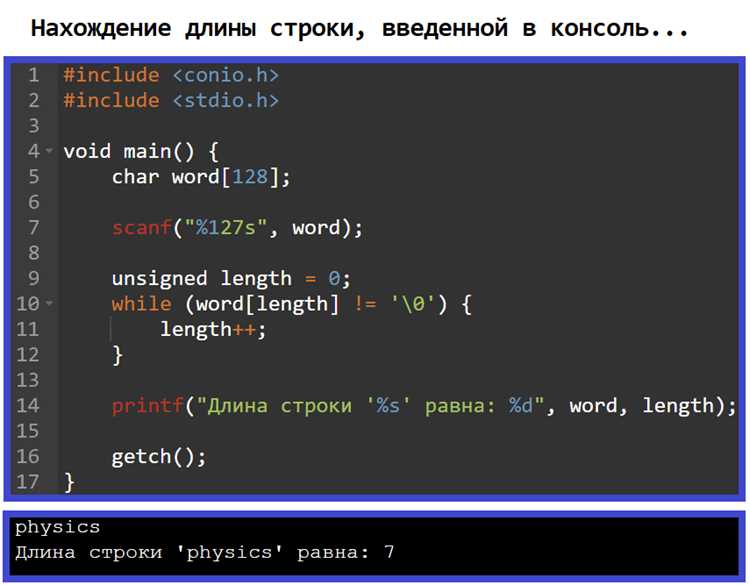
Для определения UTF-8 вручную необходимо анализировать структуру байтов многобайтовых символов. Первый байт указывает количество байтов в символе: 0xxxxxxx – 1 байт, 110xxxxx – 2 байта, 1110xxxx – 3 байта, 11110xxx – 4 байта. Последующие байты должны иметь вид 10xxxxxx.
Алгоритм проверки UTF-8 в C:
- Пройтись по каждому байту строки как unsigned char.
- Если байт < 0x80, продолжить проверку следующего.
- Если байт ≥ 0xC0, определить длину символа по шаблону первых битов.
- Проверить, что следующая последовательность байтов соответствует формату 10xxxxxx.
- Если нарушено правило, строка не является корректным UTF-8.
Для других популярных кодировок, например Windows-1251 или ISO-8859-1:
- Проверять диапазоны байтов: Windows-1251 использует 0xC0–0xFF для кириллических символов, ISO-8859-1 – 0xA0–0xFF для латиницы с диакритикой.
- Сравнивать каждый байт с таблицей соответствий символов.
- Фиксировать байты, не подходящие ни под одну известную кодировку, чтобы пометить строку как неопределённую.
Такой подход позволяет быстро идентифицировать распространённые кодировки без использования сторонних библиотек и минимизирует риск некорректного отображения текста.
Применение сторонних библиотек для распознавания кодировки
Для автоматического определения кодировки строк в C удобно использовать сторонние библиотеки, которые анализируют байтовые последовательности и выдают наиболее вероятную кодировку.
Популярные библиотеки:
| Библиотека | Описание | Особенности применения |
|---|---|---|
| uchardet | Распознаёт множество кодировок, включая UTF-8, Windows-1251, ISO-8859-1 | Простая интеграция, возвращает строку с названием кодировки, подходит для анализа текстовых файлов |
| libiconv | Предназначена для конвертации между кодировками и проверки валидности | Позволяет одновременно проверять корректность и преобразовывать строки в целевую кодировку |
| cchardet | Аналог Python-библиотеки chardet, порт на C/C++ | Возвращает вероятность кодировки, подходит для анализа потоков данных |
Рекомендации при использовании библиотек:
- Перед передачей строки в библиотеку убедиться, что она корректно представлена как массив unsigned char.
- Использовать функцию проверки ошибок библиотеки, чтобы обработать неопределённые или повреждённые последовательности.
- Комбинировать результат библиотеки с ручной проверкой критических символов для повышения точности распознавания.
Обработка ошибок при неправильной кодировке
Неправильная кодировка строки может привести к некорректному отображению текста, повреждённым символам и сбоям при обработке данных. В C необходимо предусмотреть проверку каждого байта перед использованием строки.
Методы обработки ошибок:
- Использовать контрольные функции, проверяющие соответствие байтовых последовательностей правилам UTF-8 или другим кодировкам.
- При обнаружении некорректного байта заменять его на символ замены (например, 0x3F для ‘?’) или пропускать.
- В логике программы хранить информацию о позиции ошибки для дальнейшей диагностики.
- При чтении файлов использовать буфер с дополнительной проверкой границ, чтобы избежать выхода за пределы массива.
Рекомендации:
- Обрабатывать строки как unsigned char * для корректного сравнения байтов выше 127.
- Комбинировать автоматические проверки с ручной обработкой критических символов.
- При массовой обработке текстов вести отчёт о количестве и типах ошибок кодировки для анализа качества данных.
Примеры программ для автоматического определения кодировки

Для автоматического определения кодировки строки или файла в C можно использовать готовые библиотеки и утилиты. Ниже приведены примеры с конкретными инструментами и способами их использования.
- libcharset (часть GNU libiconv)
Библиотека предоставляет функции для конвертации и проверки кодировок. Для определения кодировки строки используется функция
charset_detect()(или аналогичные функции, обёртки над iconv). Пример использования:#include <charset.h> const char* detect_encoding(const char* str, size_t len) { const char* enc = charset_detect(str, len); return enc ? enc : "unknown"; }Поддерживаются UTF-8, ISO-8859-*, Windows-125*, KOI8-R и др.
- uchardet
Библиотека, порт Mozilla Universal Charset Detector. Позволяет автоматически распознавать кодировку текста. Пример использования:
#include <uchardet/uchardet.h> uchardet_t ud = uchardet_new(); uchardet_handle_data(ud, str, len); uchardet_data_end(ud); const char* charset = uchardet_get_charset(ud); uchardet_delete(ud);Поддерживает более 100 кодировок, подходит для обработки текстовых файлов любого формата.
- ICU (International Components for Unicode)
ICU предоставляет функции
ucnv_detectUnicodeдля анализа байтов строки и определения вероятной кодировки. Пример:#include <unicode/ucnv.h> UErrorCode status = U_ZERO_ERROR; UCharsetDetector* cd = ucsdet_open(&status); ucsdet_setText(cd, str, len, &status); const UCharsetMatch* match = ucsdet_detect(cd, &status); const char* name = ucsdet_getName(match, &status); ucsdet_close(cd);Подходит для сложных текстов, где необходимо высокое качество распознавания.
- file + chardet в командной строке
Хотя это не C-библиотека напрямую, можно вызвать системную команду
file -i filenameили использовать Python-библиотекуchardetиз C черезpopen(). Подходит для быстрого анализа файлов перед обработкой.
Для практического использования рекомендуется сочетать библиотеку uchardet или ICU с локальной проверкой через libiconv, чтобы гарантировать корректность конверсии и минимизировать ошибки распознавания.
Вопрос-ответ:
Какие методы существуют для определения кодировки строки в C?
В C для определения кодировки строки используют сторонние библиотеки и алгоритмы анализа байтов. Основные варианты: библиотека uchardet, основанная на Mozilla Universal Charset Detector; ICU с функцией ucnv_detectUnicode; GNU libcharset (часть libiconv). Также возможен анализ вручную по диапазонам байтов для UTF-8 или ASCII.
Можно ли определить кодировку строки без сторонних библиотек?
Да, но с ограничениями. Для простых кодировок, таких как UTF-8 или ASCII, можно проверять байты на соответствие шаблонам: например, UTF-8 имеет определённые правила для многобайтовых символов. Для сложных кодировок, таких как Windows-1251 или ISO-8859-*, точного определения без библиотеки почти невозможно.
Как использовать библиотеку uchardet для анализа строки в C?
Сначала подключают uchardet.h и создают объект детектора через uchardet_new(). Далее передают строку и её длину в uchardet_handle_data(), после чего вызывают uchardet_data_end(). Получить результат можно через uchardet_get_charset(), а после работы объект удаляют через uchardet_delete(). Этот способ позволяет определить десятки популярных кодировок.
Как проверить, правильно ли определена кодировка?
После получения предполагаемой кодировки строку можно попробовать перекодировать в UTF-8 с помощью libiconv или ICU. Если конвертация проходит без ошибок и текст отображается корректно, значит определение верное. При ошибках стоит проверить результат другой библиотекой или использовать несколько методов одновременно.
Какие ограничения есть у автоматических методов распознавания кодировки?
Автоматическое определение кодировки может ошибаться при коротких строках или при смешении нескольких кодировок в одном тексте. Некоторые кодировки имеют одинаковые байтовые диапазоны, что затрудняет точное определение. Поэтому для критически важного текста рекомендуется проверять результат через несколько инструментов или явно задавать кодировку при чтении данных.