Содержание статьи

PostgreSQL предоставляет мощные инструменты для работы с данными, но корректное выполнение запросов требует понимания структуры базы и особенностей синтаксиса. Неправильно составленный запрос может не только замедлить работу системы, но и привести к неверным результатам.
Перед выполнением запроса важно определить, какие именно данные нужны и из каких таблиц их следует получать. Использование индексов и правильно подобранных условий в WHERE позволяет снизить нагрузку на сервер и ускорить выборку. Например, фильтрация по колонке с индексом выполняется значительно быстрее, чем по обычному полю.
При объединении таблиц через JOIN следует учитывать тип соединения. INNER JOIN возвращает только совпадающие строки, а LEFT JOIN сохраняет все строки из основной таблицы. Неправильный выбор типа соединения может увеличить объем возвращаемых данных и замедлить выполнение.
Оптимизация запросов также включает проверку порядка фильтров, использование LIMIT для больших выборок и контроль агрегаций через GROUP BY. Даже простые ошибки, такие как отсутствие нужного индекса или неправильное условие, могут значительно увеличить время выполнения и нагрузку на базу данных.
Понимание этих принципов позволяет строить запросы, которые возвращают точные данные быстро и с минимальной нагрузкой на PostgreSQL, что особенно важно при работе с крупными таблицами и сложными аналитическими задачами.
Выбор подходящего типа запроса для задачи
В PostgreSQL существует несколько основных типов запросов: SELECT для выборки данных, INSERT для добавления новых записей, UPDATE для изменения существующих и DELETE для удаления. Выбор зависит от конкретной цели: извлечение данных требует SELECT, а корректировка информации – соответствующего модифицирующего запроса.
Для аналитических задач часто применяют агрегирующие запросы с GROUP BY и HAVING. Они позволяют подсчитывать суммы, средние значения и другие показатели по категориям. При этом важно учитывать объем данных: если таблица содержит миллионы строк, стоит использовать индексы по ключевым полям для ускорения агрегации.
Для операций с несколькими таблицами следует заранее определить необходимость JOIN. INNER JOIN подходит для строгой фильтрации совпадающих строк, LEFT JOIN сохраняет все записи из основной таблицы. Выбор типа соединения напрямую влияет на скорость выполнения и размер результирующего набора.
Если задача требует вставки или обновления больших объемов данных, эффективнее использовать bulk INSERT или UPDATE … FROM, чем выполнять множество отдельных команд. Это снижает нагрузку на журнал транзакций и ускоряет обработку.
Наконец, при сложных фильтрах и сортировках стоит предварительно оценить, какие поля должны быть индексированы, и использовать подготовленные выражения (prepared statements) для повторяющихся запросов. Такой подход сокращает время выполнения и предотвращает излишние блокировки таблиц.
Подключение к базе данных и настройка сессии

Для работы с PostgreSQL необходимо корректно установить соединение с сервером и настроить параметры сессии, которые влияют на выполнение запросов. Подключение выполняется с использованием psql, драйверов для приложений или через ORM.
Основные шаги подключения:
- Указание хоста, порта, имени базы данных, пользователя и пароля.
- Выбор метода аутентификации: md5, scram-sha-256 или peer для локальных подключений.
- Проверка доступности порта 5432 и корректности конфигурации pg_hba.conf.
После подключения важно настроить сессию для оптимального выполнения запросов:
- Установка схемы по умолчанию через SET search_path.
- Регулировка параметров транзакции: SET TRANSACTION ISOLATION LEVEL для контроля блокировок.
- Настройка локали и формата даты с помощью SET lc_time и SET datestyle для корректного анализа данных.
Для повторяющихся запросов рекомендуется использовать prepared statements или подключение с пулом соединений через pgbouncer, что сокращает время создания сессии и снижает нагрузку на сервер.
Синтаксис SELECT: как выбрать нужные данные
Запрос SELECT позволяет извлекать данные из одной или нескольких таблиц. Основной синтаксис включает указание колонок или * для всех полей, таблицы и дополнительные условия фильтрации.
Пример базового запроса:
SELECT имя, фамилия FROM сотрудники;
Для сокращения объема возвращаемых данных рекомендуется использовать конкретные колонки вместо *. Это уменьшает нагрузку на сеть и ускоряет выполнение, особенно при работе с крупными таблицами.
Выбор данных можно уточнять с помощью:
- DISTINCT для исключения повторов;
- WHERE для фильтрации по условиям;
- ORDER BY для сортировки по одной или нескольким колонкам;
- LIMIT и OFFSET для управления размером выборки.
Для динамических условий лучше использовать подготовленные выражения (prepared statements) или параметры в приложениях. Это предотвращает ошибки синтаксиса и повышает безопасность при работе с пользовательскими данными.
При извлечении данных из нескольких таблиц применяют JOIN с указанием точных условий объединения. Несоблюдение правил соединения может привести к дублированию строк или увеличению объема возвращаемых данных.
Фильтрация данных с помощью WHERE и условий

Для выборки только нужных строк используется WHERE. Условия могут включать сравнения, диапазоны, шаблоны и логические операторы. Корректная фильтрация уменьшает объем обрабатываемых данных и ускоряет выполнение запроса.
Основные операторы фильтрации:
| Оператор | Пример | Описание |
|---|---|---|
| =, <>, <, >, <=, >= | salary > 50000 | Сравнение числовых и датовых значений |
| BETWEEN | date BETWEEN ‘2025-01-01’ AND ‘2025-12-31’ | Проверка попадания в диапазон |
| IN | department IN (‘IT’, ‘HR’) | Проверка принадлежности к списку значений |
| LIKE | name LIKE ‘A%’ | Поиск по шаблону |
| IS NULL / IS NOT NULL | bonus IS NOT NULL | Проверка наличия или отсутствия значения |
Для комбинирования условий используют AND, OR и скобки для явного порядка вычисления. Пример сложной фильтрации:
SELECT * FROM сотрудники WHERE department = ‘IT’ AND salary > 50000 OR hire_date > ‘2024-01-01’;
Для ускорения фильтрации критически важных колонок рекомендуется создавать индексы. Особенно это важно при работе с большим объемом данных и частыми запросами по конкретным полям.
Сортировка и группировка результатов
Для управления порядком возвращаемых строк используется ORDER BY. Можно указывать одну или несколько колонок и направление сортировки: ASC для возрастания и DESC для убывания.
Пример сортировки:
SELECT имя, фамилия, salary FROM сотрудники ORDER BY salary DESC, фамилия ASC;
Группировка данных выполняется с помощью GROUP BY. Она объединяет строки с одинаковыми значениями выбранных колонок и позволяет применять агрегатные функции: SUM, AVG, COUNT, MAX, MIN.
Рекомендации при группировке:
- Включать в GROUP BY только те колонки, по которым необходимо агрегировать.
- Использовать HAVING для фильтрации агрегированных данных вместо WHERE.
- Создавать индексы на колонках, участвующих в GROUP BY, чтобы ускорить обработку больших таблиц.
Пример группировки с фильтрацией:
SELECT department, COUNT(*) AS сотрудников, AVG(salary) AS средняя_зарплата FROM сотрудники GROUP BY department HAVING AVG(salary) > 50000;
Комбинирование сортировки и группировки позволяет получать удобные отчеты, например, список отделов по убыванию средней зарплаты с подсчетом количества сотрудников в каждом отделе.
Использование JOIN для объединения таблиц

Объединение таблиц в PostgreSQL выполняется с помощью JOIN. Существует несколько типов соединений, каждый из которых подходит для конкретной задачи.
Типы соединений:
- INNER JOIN возвращает только строки, которые совпадают по указанному условию в обеих таблицах. Используется, когда необходимы строго соответствующие данные.
- LEFT JOIN возвращает все строки из левой таблицы и соответствующие из правой; если совпадений нет, значения правой таблицы будут NULL.
- RIGHT JOIN аналогичен LEFT JOIN, но возвращает все строки из правой таблицы.
- FULL OUTER JOIN возвращает все строки из обеих таблиц, подставляя NULL там, где нет совпадений.
- CROSS JOIN создает декартово произведение, полезно для комбинаций всех значений, но требует осторожности при больших таблицах.
Рекомендации при использовании JOIN:
- Всегда указывать точные условия соединения через ON, чтобы избежать дублирования строк.
- Использовать индексы по колонкам, участвующим в соединении, для ускорения выборки.
- При объединении более двух таблиц строить запрос последовательно, проверяя результаты каждого JOIN.
- Для сложных фильтров применять WHERE после JOIN, чтобы минимизировать объем промежуточных данных.
Пример INNER JOIN:
SELECT сотрудники.имя, отделы.название FROM сотрудники INNER JOIN отделы ON сотрудники.department_id = отделы.id;
Такой подход позволяет получать согласованные наборы данных из нескольких таблиц без потери информации и избыточного объема выборки.
Проверка и отладка запросов перед выполнением

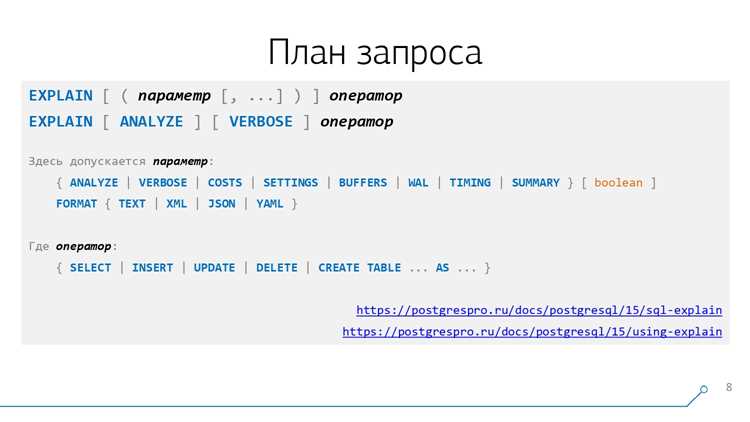
Перед выполнением запросов в PostgreSQL важно проверить синтаксис и оценить план выполнения. Это снижает вероятность ошибок и позволяет оптимизировать работу с базой данных.
Для анализа запроса используют команду EXPLAIN. Она отображает последовательность операций, включая сканирование таблиц, использование индексов и порядок соединений.
Пример проверки запроса:
EXPLAIN SELECT * FROM сотрудники WHERE salary > 50000;
Для получения более подробной информации о затратах и времени выполнения применяют EXPLAIN ANALYZE. Она фактически выполняет запрос и показывает статистику по каждому шагу.
Рекомендации по отладке:
- Проверять условия WHERE и JOIN ON на корректность, чтобы исключить дублирование или потерю данных.
- Использовать LIMIT для тестовой выборки больших таблиц, чтобы ускорить проверку.
- Разбивать сложные запросы на части, проверяя промежуточные результаты.
- Применять pg_stat_statements для мониторинга часто выполняемых запросов и выявления узких мест.
Регулярная проверка и анализ планов выполнения позволяет своевременно выявлять неэффективные конструкции и корректно подбирать индексы, что снижает нагрузку на сервер и ускоряет работу с данными.
Вопрос-ответ:
Какие типы запросов PostgreSQL стоит использовать для разных задач?
В PostgreSQL существуют основные типы запросов: SELECT для выборки данных, INSERT для добавления новых записей, UPDATE для изменения существующих и DELETE для удаления. Для аналитики используют агрегирующие запросы с GROUP BY, для объединения таблиц применяют JOIN. Выбор зависит от того, нужно извлечь данные, обновить их или получить сводку.
Как правильно подключаться к базе и настраивать сессию?
Подключение выполняется с указанием хоста, порта, имени базы, пользователя и пароля. После соединения следует настроить схему через SET search_path, установить уровень изоляции транзакций через SET TRANSACTION ISOLATION LEVEL и формат даты с помощью SET datestyle. Для повторяющихся запросов рекомендуется использовать подготовленные выражения или пул соединений через pgbouncer.
Как фильтровать данные с помощью WHERE и условий?
Для фильтрации применяют WHERE с операторами сравнения (=, <>, <, >=), BETWEEN для диапазонов, IN для списков значений, LIKE для поиска по шаблону и IS NULL для проверки отсутствующих значений. Логические операторы AND и OR позволяют комбинировать условия, а использование индексов ускоряет выборку.
В чем отличие INNER JOIN, LEFT JOIN и FULL OUTER JOIN?
INNER JOIN возвращает только совпадающие строки из обеих таблиц. LEFT JOIN сохраняет все строки из левой таблицы, подставляя NULL для правой, если совпадений нет. FULL OUTER JOIN возвращает все строки из обеих таблиц, заполняя NULL там, где нет совпадений. Выбор типа соединения влияет на количество возвращаемых данных и время выполнения.
Как проверить и оптимизировать запрос перед выполнением?
Для анализа запроса используют EXPLAIN и EXPLAIN ANALYZE, чтобы увидеть план выполнения, порядок сканирования таблиц, использование индексов и нагрузку на сервер. Разбивка сложных запросов на части, использование LIMIT для тестовой выборки и проверка условий WHERE и JOIN ON помогают выявить ошибки и ускорить обработку.
Как правильно использовать индексы для ускорения запросов в PostgreSQL?
Индексы в PostgreSQL позволяют ускорять выборку данных по конкретным колонкам. Для фильтрации через WHERE или соединений JOIN стоит создавать B-tree индексы на числовых, строковых и датовых полях. Для текстового поиска используют GIN или GiST индексы. При больших таблицах полезно проверять план выполнения через EXPLAIN, чтобы убедиться, что запрос использует индекс, иначе PostgreSQL выполнит полное сканирование таблицы, что увеличит время обработки.