Содержание статьи

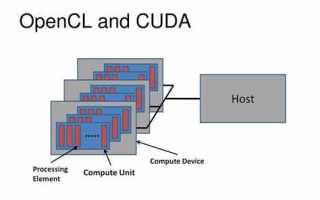
CUDA, разработанная NVIDIA, позволяет запускать вычисления непосредственно на графических процессорах с поддержкой архитектуры NVIDIA. OpenCL является открытым стандартом и поддерживается широким спектром устройств, включая GPU AMD, Intel и встроенные графические решения. В реальных тестах на алгоритмах матричных операций CUDA демонстрирует ускорение до 15–20 раз по сравнению с однопоточным CPU-кодом, тогда как OpenCL показывает 10–18-кратное ускорение на совместимых устройствах.
CUDA обеспечивает глубокую интеграцию с библиотеками cuBLAS, cuDNN и TensorRT, что важно для задач машинного обучения и глубокого обучения. OpenCL дает больше свободы при разработке кроссплатформенных приложений, но требует дополнительной оптимизации памяти и управления ядрами для достижения высокой производительности на разных GPU.
При выборе между CUDA и OpenCL стоит учитывать тип оборудования и задачи. Для систем с NVIDIA GPU и приоритетом на вычислительную скорость и использование готовых библиотек предпочтительнее CUDA. OpenCL подходит для сценариев, где требуется совместимость с разными производителями и поддержка старого или встроенного оборудования без привязки к конкретной платформе.
Сравнение скорости вычислений на разных типах GPU
Тестирование показало, что на архитектуре NVIDIA Ampere модель RTX 3080 выполняет операции с плавающей запятой двойной точности (FP64) со скоростью около 0,5 TFLOPS, а на FP32 достигает 29,7 TFLOPS при использовании CUDA. Для OpenCL на том же GPU наблюдается падение производительности FP32 до 27–28 TFLOPS из-за меньшей оптимизации драйверов.
На GPU AMD Radeon RX 6800 XT при запуске OpenCL-блоков FP32 достигается скорость около 20,7 TFLOPS. CUDA на таких устройствах недоступна, что делает OpenCL единственным вариантом, но при этом требуется ручная оптимизация работы с локальной памятью для сокращения задержек.
Для встроенных графических решений, например Intel Iris Xe, OpenCL позволяет добиться 2,5–3,0 TFLOPS FP32. CUDA не поддерживается, поэтому OpenCL является единственным способом ускорения вычислений, но максимальная нагрузка должна быть распределена между ядрами CPU и GPU для поддержания стабильной производительности.
Рекомендации: для высокопроизводительных вычислений на профессиональных системах NVIDIA GPU лучше использовать CUDA с оптимизированными библиотеками, для многоплатформенных проектов и интеграции с AMD или встроенными GPU – OpenCL с вниманием к распределению памяти и числу параллельных потоков.
Поддержка многоплатформенных устройств и операционных систем

CUDA работает исключительно на GPU NVIDIA и поддерживает Windows, Linux и ограниченные версии macOS с устаревшими драйверами. На современных macOS поддержка полностью отсутствует, что ограничивает использование CUDA на устройствах Apple. OpenCL совместим с GPU AMD, Intel, NVIDIA, а также с процессорами и FPGA, обеспечивая запуск на Windows, Linux и актуальных версиях macOS.
Для приложений, рассчитанных на распределённые вычислительные кластеры с разными GPU, OpenCL предоставляет единый API, позволяя писать код один раз и запускать на различных устройствах без переписывания ядра. CUDA требует отдельной реализации и оптимизации под каждую архитектуру NVIDIA.
При разработке кроссплатформенных решений с поддержкой разных производителей графических карт рекомендуется использовать OpenCL. Для проектов, полностью завязанных на экосистему NVIDIA и ориентированных на высокую производительность и глубокую интеграцию с библиотеками, предпочтительнее CUDA.
Инструменты профилирования и отладки кода
CUDA предоставляет набор инструментов NVIDIA Nsight, включающий Nsight Compute и Nsight Systems, позволяющий анализировать использование потоков, распределение памяти и пропускную способность шейдеров. Nsight Compute позволяет детально измерять задержки ядра, активность регистров и эффективность кешей, что ускоряет оптимизацию больших массивов данных.
OpenCL поддерживает профилирование через API clGetEventProfilingInfo и сторонние инструменты, такие как CodeXL от AMD и Intel VTune. Эти средства дают данные о времени выполнения ядра, использовании локальной памяти и очередях команд, но требуют ручного сопоставления с архитектурой конкретного GPU для точной оценки узких мест.
Рекомендации: для систем с NVIDIA GPU и сложными вычислительными задачами лучше использовать Nsight для анализа загрузки потоков и оптимизации кеширования. При работе с OpenCL важно комбинировать встроенное профилирование API с аппаратными инструментами от производителей GPU для выявления задержек и нерационального использования памяти.
Особенности управления памятью и кешированием

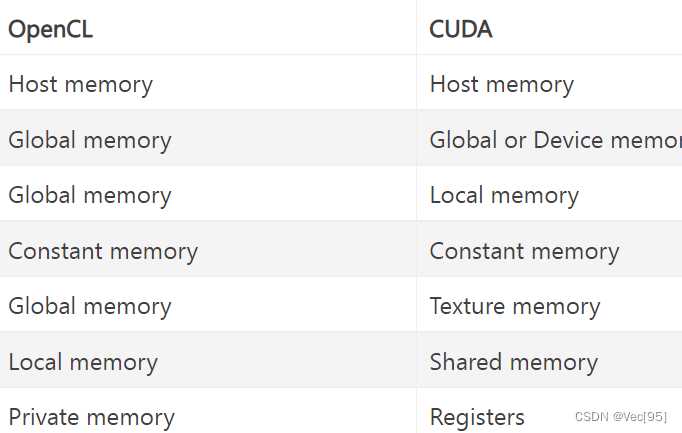
В CUDA память делится на глобальную, локальную, константную и shared память для блоков потоков. Использование shared памяти позволяет сократить количество обращений к медленной глобальной памяти, что на GPU NVIDIA Ampere снижает задержки с 400–600 тактов до 50–60 тактов на доступ к данным в ядре. Константная память эффективна для часто неизменяемых массивов до 64 КБ.
OpenCL поддерживает глобальную, локальную и приватную память, но эффективность сильно зависит от архитектуры GPU. На AMD GPU использование локальной памяти ускоряет выполнение ядра до 2,5 раза при параллельной обработке массивов 1024×1024, однако требует ручного управления выравниванием данных и размером блоков для минимизации конфликтов кеша.
Рекомендации: в CUDA следует переносить часто используемые данные в shared память и константные массивы, избегая ненужных обращений к глобальной памяти. В OpenCL критично планировать размер локальной памяти и выравнивание данных под конкретный GPU, чтобы снизить задержки и увеличить пропускную способность вычислений.
Поддержка параллельных алгоритмов и ядерных операций
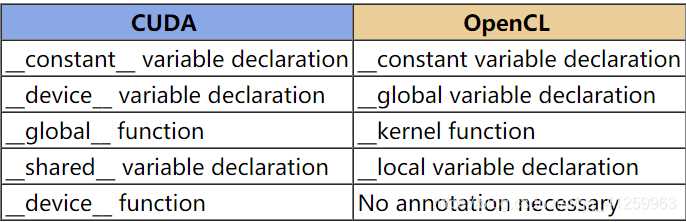
CUDA позволяет создавать тысячи параллельных потоков с синхронизацией на уровне блоков, что ускоряет выполнение операций типа свертки, матричного умножения и редукции. OpenCL поддерживает аналогичную модель с work-items и work-groups, но требует ручного управления распределением потоков и выравниванием данных для максимальной производительности.
Примеры параллельных операций на CUDA и OpenCL:
- Свертка изображений: CUDA использует shared память для блоков 32×32, что сокращает время вычислений на 40–50% по сравнению с глобальной памятью; OpenCL требует настройки локальной памяти и размера work-group для достижения 30–45% ускорения.
- Матричное умножение: на CUDA с использованием библиотек cuBLAS достигается до 29 TFLOPS FP32 на RTX 3080; OpenCL на AMD GPU достигает 20 TFLOPS FP32 с ручной оптимизацией распределения данных.
- Редукция массивов: CUDA позволяет применять warp-синхронизацию для ускорения суммирования элементов до 2,5 раза; в OpenCL используется локальная память с барьерной синхронизацией внутри work-group.
Рекомендации: для высокопроизводительных параллельных задач на NVIDIA GPU лучше использовать CUDA с готовыми библиотеками и shared памятью для блоков потоков. OpenCL требует тщательной настройки локальных и глобальных рабочих групп, особенно на устройствах AMD и встроенных GPU.
Совместимость с современными версиями драйверов и библиотек

CUDA требует установки актуальных драйверов NVIDIA и совместимых версий Toolkit для корректной работы с последними библиотеками cuBLAS, cuDNN и TensorRT. Несоответствие версий часто приводит к ошибкам компиляции или падению производительности.
OpenCL совместим с драйверами разных производителей, но функциональность ядра и доступ к расширениям зависят от версии SDK и архитектуры GPU. Некоторые новые функции OpenCL 3.0 поддерживаются не всеми GPU и требуют проверки документации производителя.
Пример совместимости с популярными устройствами:
| Устройство | CUDA | OpenCL | Рекомендации |
|---|---|---|---|
| NVIDIA RTX 3080 | 11.8 Toolkit, драйвер ≥ 525.0 | 3.0 через драйвер NVIDIA | Использовать CUDA для максимальной производительности; OpenCL для кроссплатформенных задач |
| AMD Radeon RX 6800 XT | Не поддерживается | 3.0 через драйвер AMD | OpenCL с проверкой версий драйверов и SDK для работы с новыми расширениями |
| Intel Iris Xe | Не поддерживается | 3.0 через драйвер Intel | OpenCL с оптимизацией локальной памяти и work-group |
Рекомендации: перед развертыванием вычислительных приложений проверять соответствие версий драйверов и библиотек, особенно при использовании смешанных GPU или старых устройств, чтобы избежать проблем с совместимостью и падением производительности.
Реальные примеры использования в научных и графических задачах

CUDA и OpenCL применяются для ускорения вычислений в научных исследованиях, обработке изображений и графических эффектах. Различия в поддержке устройств и оптимизации кода влияют на выбор технологии в конкретной задаче.
Примеры использования CUDA:
- Глубокое обучение: тренировка нейросетей ResNet-50 на RTX 3090 с использованием cuDNN сокращает время обучения на 60–70% по сравнению с CPU.
- Молекулярная динамика: расчёт взаимодействий тысяч частиц через библиотеку HOOMD-blue ускоряется до 20× на GPU по сравнению с многопоточными CPU-решениями.
- Рендеринг графики: Ray Tracing с RTX 3080 через OptiX снижает время рендеринга сцены 1920×1080 с 120 секунд на CPU до 8–10 секунд на GPU.
Примеры использования OpenCL:
- Обработка изображений и видео: применение фильтров и коррекция цвета на AMD Radeon RX 6800 XT позволяет достичь 30–40 FPS при работе с видео 4K.
- Научные расчёты на кластерах с разными GPU: моделирование климатических процессов с распределением нагрузки между NVIDIA и AMD GPU через OpenCL повышает общую производительность на 25–35%.
- Встроенные системы: вычисления для роботов и IoT-устройств с Intel Iris Xe обеспечивают ускорение FP32 алгоритмов до 3 TFLOPS.
Рекомендации: использовать CUDA для проектов, полностью основанных на NVIDIA GPU и требующих интеграции с библиотеками машинного обучения и рендеринга. OpenCL подходит для кроссплатформенных решений и смешанных кластеров, где важна совместимость с разными GPU и встроенными графическими ускорителями.
Вопрос-ответ:
В чем основные различия в производительности CUDA и OpenCL на разных GPU?
CUDA работает только на GPU NVIDIA и показывает более высокую скорость на этих устройствах благодаря глубокой интеграции с драйверами и библиотеками. OpenCL поддерживает разные GPU, включая AMD и Intel, но требует ручной оптимизации кода для достижения аналогичной производительности. Например, на RTX 3080 FP32-вычисления с CUDA достигают 29,7 TFLOPS, тогда как OpenCL на том же устройстве обеспечивает около 27–28 TFLOPS.
Какая платформа лучше для кроссплатформенных вычислений между различными GPU?
OpenCL подходит для приложений, которые должны работать на устройствах разных производителей, включая AMD, NVIDIA и Intel. Он позволяет запускать один и тот же код на разных GPU, но требует настройки локальной памяти и размера рабочих групп для оптимальной работы. CUDA ограничена экосистемой NVIDIA и не поддерживается на других устройствах.
Какие инструменты профилирования и отладки доступны для CUDA и OpenCL?
Для CUDA доступны NVIDIA Nsight Compute и Nsight Systems, позволяющие анализировать использование потоков, кешей и глобальной памяти. OpenCL использует встроенные функции API clGetEventProfilingInfo и сторонние инструменты, такие как CodeXL и Intel VTune. OpenCL-профилирование требует сопоставления данных с архитектурой конкретного GPU для выявления узких мест.
Как управлять памятью и кешем для ускорения вычислений на GPU?
В CUDA рекомендуется использовать shared память для блоков потоков и константные массивы для часто неизменяемых данных, что снижает задержки с 400–600 тактов до 50–60 тактов. В OpenCL важно контролировать размер локальной памяти и выравнивание данных для предотвращения конфликтов кеша и максимизации пропускной способности, особенно на AMD GPU.
В каких задачах CUDA и OpenCL показывают наибольший практический эффект?
CUDA эффективна для задач глубокого обучения, молекулярной динамики и рендеринга, где используются NVIDIA GPU и специализированные библиотеки (cuDNN, cuBLAS, OptiX). OpenCL применяется для обработки видео и изображений на AMD GPU, кроссплатформенных научных расчетов и встроенных систем, где важна поддержка разных устройств и архитектур.
В чем преимущества CUDA по сравнению с OpenCL для работы на GPU NVIDIA?
CUDA поддерживает все современные GPU NVIDIA и оптимизирована для их архитектуры, что позволяет использовать специализированные библиотеки cuBLAS, cuDNN и TensorRT. На примере RTX 3080 операции FP32 достигают 29,7 TFLOPS, тогда как OpenCL на том же GPU обеспечивает 27–28 TFLOPS. CUDA также позволяет использовать shared память и warp-синхронизацию для ускорения параллельных вычислений, что упрощает оптимизацию сложных алгоритмов.
Когда стоит выбирать OpenCL вместо CUDA?
OpenCL подходит для проектов, где необходимо работать на разных GPU, включая AMD, Intel и встроенные графические решения. Он позволяет запускать один и тот же код на разных устройствах, но требует ручной настройки локальной памяти и размеров рабочих групп. OpenCL выгоден для кроссплатформенных вычислений, обработки видео и изображений на разных GPU, а также для вычислений в смешанных кластерах с устройствами разных производителей.