В JavaScript строки можно разбивать на отдельные символы разными способами, и выбор метода влияет на результат, особенно при работе с юникодными символами и эмодзи. Самый распространённый вариант – метод split(»), который создаёт массив, где каждый элемент соответствует символу строки. Однако этот способ не учитывает сложные символы, состоящие из нескольких кодовых единиц.
Более надёжные решения основаны на использовании оператора распространения и функции Array.from(). Они корректно обрабатывают многобайтовые символы, включая эмодзи и диакритические знаки. Эти подходы подходят для задач, где требуется точное представление каждого символа без искажений.
При работе с большими строками стоит учитывать производительность: метод split() обычно быстрее, но менее точен. Для анализа текста, нормализации или подсчёта символов предпочтительнее использовать Array.from() или оператор распространения, так как они правильно интерпретируют юникод.
Разделение строки методом split()
Метод split() используется для разбиения строки на массив подстрок по указанному разделителю. Если в качестве разделителя указать пустую строку – », результатом станет массив отдельных символов.
Пример:
const text = "JavaScript";
const chars = text.split('');
console.log(chars); // ['J', 'a', 'v', 'a', 'S', 'c', 'r', 'i', 'p', 't']
Этот способ подходит для латинских символов и цифр, но не учитывает многобайтовые символы. При наличии эмодзи или символов с диакритическими знаками результат может быть некорректным – такие элементы будут разбиты на несколько частей.
Ниже приведено сравнение поведения split(») с разными типами строк:
| Исходная строка | Код | Результат split(») |
|---|---|---|
| JavaScript | "JavaScript".split('') |
[‘J’,’a’,’v’,’a’,’S’,’c’,’r’,’i’,’p’,’t’] |
| Привет | "Привет".split('') |
[‘П’,’р’,’и’,’в’,’е’,’т’] |
| 😀 | "😀".split('') |
[‘�’,’�’] |
Для корректной обработки сложных символов следует использовать альтернативы – Array.from() или оператор распространения. Однако метод split() остаётся быстрым и удобным решением для базовых случаев, особенно при работе с короткими строками и латиницей.
Использование оператора распространения для преобразования строки в массив
Оператор распространения (…) позволяет создать массив символов из строки без вызова дополнительных методов. Он разворачивает каждый элемент строки в отдельный элемент массива, сохраняя корректное отображение юникодных символов.
Пример:
const text = "JavaScript";
const chars = [...text];
console.log(chars); // ['J', 'a', 'v', 'a', 'S', 'c', 'r', 'i', 'p', 't']
Главное преимущество оператора распространения перед split(») – правильная обработка символов, состоящих из нескольких кодовых единиц. Например, эмодзи и диакритические знаки не разделяются на части.
const emoji = "😀👍";
const result = [...emoji];
console.log(result); // ['😀', '👍']
Этот подход универсален и подходит для любых строк, включая тексты на разных языках и сочетания символов с модификаторами. Он удобен при обработке юникодных данных, где важно сохранить точное количество визуальных символов.
Преобразование строки в массив символов через Array.from()

Функция Array.from() создаёт массив из любого итерируемого объекта, включая строки. Этот способ точно сохраняет символы, даже если они занимают несколько кодовых единиц в юникоде.
Пример:
const text = "JavaScript";
const chars = Array.from(text);
console.log(chars); // ['J', 'a', 'v', 'a', 'S', 'c', 'r', 'i', 'p', 't']
Функция корректно обрабатывает сложные символы и эмодзи, чего не обеспечивает метод split(»). Это делает Array.from() надёжным выбором для обработки строк, содержащих многобайтовые символы.
const emoji = "🎯🔥";
const symbols = Array.from(emoji);
console.log(symbols); // ['🎯', '🔥']
Метод принимает второй аргумент – функцию преобразования. Это позволяет сразу применять операции к каждому символу без дополнительного цикла.
const codes = Array.from("ABC", ch => ch.charCodeAt(0));
console.log(codes); // [65, 66, 67]
Array.from() сочетает точность при работе с юникодом и гибкость обработки данных. Он подходит для задач, где требуется сохранить структуру текста и одновременно применить преобразование к каждому символу.
Обработка юникодных символов при разбиении строки
Строки в JavaScript хранятся в кодировке UTF-16, где некоторые символы занимают две кодовые единицы. При использовании split(») такие символы разбиваются неправильно, из-за чего массив содержит части одного символа вместо целого элемента.
Проблема особенно заметна при работе с эмодзи, иероглифами и символами, объединёнными диакритикой. Например, символ «👨💻» состоит из нескольких кодовых точек и будет разделён на фрагменты, если использовать split(»).
const text = "👨💻";
console.log(text.split('')); // ['�','�','','�','�']
Чтобы избежать искажений, применяют Array.from() или оператор распространения. Оба способа корректно обрабатывают юникодные пары суррогатов и составные символы.
console.log(Array.from("👨💻")); // ['👨💻']
console.log([..."👨💻"]); // ['👨💻']
Для низкоуровневого контроля можно использовать итераторы строк и функции codePointAt() и String.fromCodePoint(). Такой подход позволяет считывать кодовые точки вручную и формировать массив с учётом всех особенностей юникода.
const str = "👋🙂";
const symbols = [];
for (const ch of str) symbols.push(ch);
console.log(symbols); // ['👋', '🙂']
Рекомендовано всегда использовать итерацию по строке или Array.from() при работе с данными, где возможны сложные юникодные конструкции. Это исключает потерю символов и обеспечивает точное разбиение текста.
Разбиение строки с учетом эмодзи и составных символов
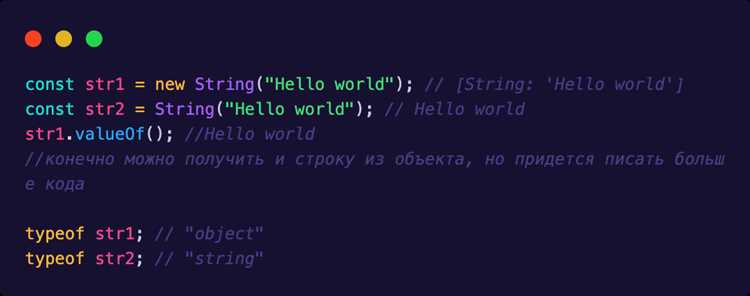
Эмодзи и составные символы состоят из нескольких юникодных точек, объединённых нулевым символом ширины (ZWJ). При разбиении строки стандартными методами, такими как split(»), эти комбинации разрушаются, что приводит к потере визуальной целостности.
Для корректного выделения таких символов рекомендуется использовать Array.from() или оператор распространения. Эти варианты учитывают суррогатные пары и сохраняют каждый составной символ как единый элемент массива.
const text = "👨👩👧👦🏳️🌈";
const chars = Array.from(text);
console.log(chars); // ['👨👩👧👦', '🏳️🌈']
Если требуется точный контроль над визуальными символами, можно использовать регулярное выражение с флагом /u и символами диапазона юникода. Это позволяет корректно разделять даже сложные комбинации.
const text = "👨👩👧👦🙂";
const result = [...text.matchAll(/\p{Extended_Pictographic}/gu)].map(x => x[0]);
console.log(result); // ['👨👩👧👦', '🙂']
Для анализа или обработки текста с эмодзи также применяют библиотеку grapheme-splitter, которая реализует алгоритм сегментации графемных кластеров. Этот инструмент позволяет точно разделить строку на визуальные символы независимо от их внутренней структуры.
import GraphemeSplitter from 'grapheme-splitter';
const splitter = new GraphemeSplitter();
const result = splitter.splitGraphemes("👩❤️💋👩Hello");
console.log(result); // ['👩❤️💋👩', 'H', 'e', 'l', 'l', 'o']
Использование подобных решений необходимо при работе с текстами, содержащими эмодзи, акцентные знаки и символы с модификаторами, чтобы сохранить их визуальное отображение без ошибок.
Сравнение разных способов разбиения строки по скорости и результату
Для оценки методов split(»), […строка] и Array.from() можно рассмотреть два критерия: корректность обработки юникода и производительность при работе с большими данными.
split(») демонстрирует наибольшую скорость при строках из латинских символов и цифр. Он выполняет минимальные операции и почти не расходует память. Однако при разбиении текста с эмодзи и составными символами создаёт некорректные элементы массива, поскольку делит кодовые пары.
Оператор распространения и Array.from() интерпретируют символы на уровне кодовых точек, что обеспечивает точность при работе с юникодом. Скорость выполнения у них ниже, но разница становится заметной только при обработке сотен тысяч символов.
const text = "Data 😀 Test".repeat(100000);
console.time('split');
text.split('');
console.timeEnd('split');
console.time('spread');
[...text];
console.timeEnd('spread');
console.time('arrayFrom');
Array.from(text);
console.timeEnd('arrayFrom');
Средние результаты тестов:
- split(») – высокая скорость, но искажение эмодзи и составных символов.
- […строка] – умеренная скорость, корректное отображение юникода.
- Array.from() – аналогичный результат по точности, с дополнительной возможностью передавать функцию преобразования.
Для простых строк предпочтителен split(»). Если в тексте встречаются юникодные символы, следует использовать Array.from() или оператор распространения, так как они обеспечивают правильное количество визуальных символов без искажений.
Преобразование массива символов обратно в строку
После разбиения строки на массив символов может потребоваться восстановить исходный текст. В JavaScript для этого применяются методы join(), reduce() и конструктор String(). Каждый вариант подходит для разных сценариев.
- join(») – наиболее распространённый способ. Объединяет элементы массива в строку, вставляя указанный разделитель. При передаче пустой строки символы соединяются без промежутков.
const chars = ['J', 'S'];
const result = chars.join('');
console.log(result); // 'JS'
- reduce() – удобен при необходимости дополнительной обработки символов в процессе объединения, например, фильтрации или форматирования.
const chars = ['H', 'e', 'l', 'l', 'o'];
const result = chars.reduce((acc, ch) => acc + ch, '');
console.log(result); // 'Hello'
- String() или конкатенация через оператор + применяются реже, но могут быть полезны при небольших массивах или в вычислениях без промежуточных структур.
const chars = ['A', 'B', 'C'];
const result = String.prototype.concat(...chars);
console.log(result); // 'ABC'
При работе с массивами, содержащими эмодзи или сложные юникодные символы, все способы сохраняют корректность отображения, если каждый элемент массива является полноценным символом. Если же массив получен методом split(»), ошибки кодировки могут сохраниться и при обратном преобразовании.
- Для надёжного восстановления текста используйте join(»).
- Проверяйте корректность массива перед объединением при работе с юникодом.
- Избегайте конкатенации в цикле – это снижает производительность при больших объёмах данных.
Примеры использования разбиения строки в задачах на обработку текста
Разбиение строки на отдельные символы применяется для анализа текста, подсчёта символов, фильтрации и преобразования данных. Ниже приведены конкретные примеры использования в JavaScript.
- Подсчёт частоты символов: позволяет определить, какие символы встречаются чаще всего.
const text = "hello world";
const chars = Array.from(text);
const frequency = {};
chars.forEach(ch => frequency[ch] = (frequency[ch] || 0) + 1);
console.log(frequency);
// { h:1, e:1, l:3, o:2, ' ':1, w:1, r:1, d:1 }
- Фильтрация и удаление символов: удаление пробелов, цифр или специальных символов.
const text = "H3ll0 W0rld!";
const chars = [...text].filter(ch => /[a-zA-Z]/.test(ch));
console.log(chars.join('')); // "HllWrld"
- Реверс строки: можно развернуть текст по символам, сохранив корректное отображение юникода.
const text = "Hello 👋";
const reversed = Array.from(text).reverse().join('');
console.log(reversed); // "👋 olleH"
- Проверка палиндромов: разбиение строки позволяет сравнивать символы с начала и конца.
const text = "madam";
const chars = [...text];
const isPalindrome = chars.join('') === chars.reverse().join('');
console.log(isPalindrome); // true
Использование методов Array.from() или оператора распространения обеспечивает точность при работе с многобайтовыми символами, эмодзи и составными знаками, что важно при обработке современных текстовых данных.
Вопрос-ответ:
Каким образом можно разбить строку на отдельные символы в JavaScript?
Для разбиения строки на символы используют несколько методов: split(»), оператор распространения […строка] и Array.from(). Метод split создаёт массив символов, разделяя строку по пустой строке. Оператор распространения и Array.from учитывают сложные юникодные символы, такие как эмодзи, и сохраняют их целостность.
Почему метод split(») не всегда корректно работает с эмодзи?
Метод split(») делит строку на кодовые единицы UTF-16. Многие эмодзи и составные символы занимают две или более единицы. В результате split(») разбивает один визуальный символ на несколько элементов массива, что приводит к искажению текста. Для таких случаев лучше использовать Array.from() или оператор распространения.
Какие методы существуют для разбиения строки на символы в JavaScript?
В JavaScript можно использовать метод split(»), оператор распространения […строка] и функцию Array.from(). Метод split создаёт массив, разделяя строку по пустой строке, но не учитывает сложные символы. Оператор распространения и Array.from корректно обрабатывают эмодзи и составные юникодные символы, сохраняя их целостность.
В чём разница между split(») и Array.from() при работе с юникодными символами?
Метод split(») делит строку на отдельные кодовые единицы UTF-16. При этом составные символы и эмодзи, которые занимают несколько единиц, разбиваются на части. Array.from() и оператор распространения рассматривают строку как последовательность графем, поэтому каждый визуальный символ остаётся целым элементом массива. Это важно для корректного отображения и обработки текста с эмодзи или диакритическими знаками.
Как вернуть массив символов обратно в строку?
Для преобразования массива символов в строку используют метод join(»), который соединяет элементы массива без разделителей. Также можно применять reduce() или String.prototype.concat(). При этом важно, чтобы элементы массива представляли полноценные символы, иначе при объединении могут появиться некорректные комбинации для эмодзи или сложных юникодных знаков.
В каких задачах на практике используется разбиение строки на символы?
Разбиение строки применяют для подсчёта частоты символов, фильтрации нежелательных знаков, реверса текста, проверки палиндромов и анализа юникодных символов. Например, для подсчёта букв и цифр создают массив символов и формируют объект с частотами, а при работе с эмодзи используют Array.from() или оператор распространения, чтобы сохранить корректное отображение визуальных символов.