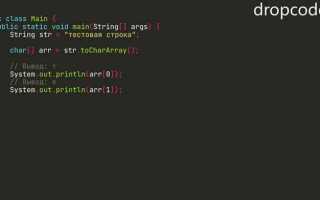
В Java строковые значения нередко служат входными данными для последующей обработки: параметры запросов, фрагменты JSON, содержимое файлов, результаты вычислений. Чтобы извлечь нужные элементы, разработчик опирается на методы класса String, регулярные выражения и дополнительные утилиты. Каждый подход решает отдельную задачу: поиск позиции символа, выделение участка текста, разделение по разделителям, проверка структуры формата.
Метод split() используется, когда строка содержит повторяющиеся разделители. Он подходит для обработки CSV-подобных структур или параметров, передаваемых через знак «&». Если требуется точное управление диапазонами, применяют substring(): этот вариант удобен при работе с фиксированными смещениями, например при чтении логов или протокольных сообщений.
Когда входные данные содержат вариативные шаблоны, используются регулярные выражения. Они позволяют выделять группы символов, проверять формат, извлекать значения по условию. Такой подход востребован при обработке e-mail адресов, номеров, токенов и параметров, содержащих сложные комбинации символов.
Разделение строки методом split() при обработке данных

Метод split() подходит для строк, в которых значения отделены повторяющимися символами или шаблонами. Например, при обработке строки «id=15;name=Alex;role=admin» можно использовать разделитель «;», чтобы получить массив с отдельными параметрами. После разбиения удобно выполнить дополнительный разбор каждого элемента через split(«=»), выделив ключ и значение.
Если строка содержит несколько подряд идущих разделителей, требуется учитывать регулярное выражение. Пример: при работе с пользовательским вводом вида «A;;C;D» выражение split(«;+») позволит избежать появления пустых элементов массива. Такой подход облегчает обработку данных, поступающих из форм, логов или внешних API.
При необходимости ограничить количество частей используется второй аргумент метода. Конструкция split(«:», 2) делит строку только один раз, оставляя вторую часть неизменной. Это полезно при работе с сообщениями, где содержимое после первого разделителя не должно быть фрагментировано.
Извлечение подстрок с помощью substring() для фиксации нужных фрагментов
Метод substring() используют, когда требуется получить участок строки по точным границам. Например, при обработке метки времени вида «2025-11-14T21:08» можно выделить год через substring(0, 4), а часы – через substring(11, 13). Такой подход удобен при работе с форматами, в которых позиции символов стабильны.
Перед вызовом метода стоит проверять длину строки, чтобы избежать StringIndexOutOfBoundsException. Часто это делают при чтении логов или протоколов, где возможны укороченные записи. Контроль длины позволяет корректно пропускать повреждённые строки.
При комбинировании indexOf() и substring() можно извлекать динамические фрагменты. Например, если требуется получить значение между двоеточием и пробелом в строке «level:WARN module:core», сначала вычисляют позицию символа «:», затем – следующего пробела, и формируют подстроку. Такой подход применяется для разбора структур, где длина участков не фиксирована.
Поиск символов и шаблонов через indexOf() и lastIndexOf()
Методы indexOf() и lastIndexOf() применяются для определения позиции символов или последовательностей, что упрощает выделение фрагментов строки и проверку её структуры. Оба метода возвращают индекс первого символа найденного совпадения либо -1, если совпадение отсутствует.
- Для строки «error:code=504;source=gateway» вызов indexOf(«code=») позволяет определить начало параметра. Далее можно вычислить границы следующего разделителя через indexOf(«;», start).
- При обработке путей вида «/home/user/docs/report.pdf» метод lastIndexOf(«/») помогает выделить имя файла, так как последний слэш указывает на границу каталога.
- Если строка содержит вложенные конструкции, например «[tag[value]]», то indexOf(«[«) и lastIndexOf(«]») помогают определить внешний диапазон, после чего можно выполнить дальнейший разбор.
Перед использованием результатов поиска стоит проверять возвращаемые индексы, чтобы избежать ошибок при некорректном формате данных. Такой контроль особенно важен при работе с логами, входными параметрами и текстовыми протоколами, где структура строки может меняться.
Применение регулярных выражений для выборки частей строки
Регулярные выражения удобны при разборе строк, где нужные значения встречаются в разных позициях. Например, для строки «order=5931; price=240.50; status=ok» можно использовать шаблон «price=([0-9.]+)», позволяющий извлечь числовое значение без ручного поиска границ.
При частом использовании одного и того же выражения целесообразно создавать объект Pattern, чтобы избежать повторной компиляции. Далее через Matcher выполняют поиск совпадений и обращаются к группам, указанным в круглых скобках. Такой подход применяется при обработке логов, протоколов и параметров запросов.
Если строка содержит набор однотипных значений, например «tags:java,regex,parsing», можно применить шаблон «[a-zA-Z]+» и считать результаты в цикле matcher.find(). Это помогает выделить все элементы списка без предварительного разбиения строки на части.
Разбор формата CSV и похожих структур вручную и средствами Java
Для обработки CSV-строк стандартный метод split() подходит при отсутствии вложенных запятых и кавычек. Например, строка «John,Doe,25» корректно разделяется через split(«,»). Каждое значение помещается в массив для дальнейшей обработки или сохранения в объект.
Если значения заключены в кавычки и содержат запятые, требуется учитывать специальные правила. В таких случаях используют регулярные выражения вида «,(?=(?:[^\»]*\»[^\»]*\»)*[^\»]*$)», что позволяет разбивать строку только по разделителям вне кавычек. Такой подход предотвращает некорректное деление вложенных данных.
Для больших CSV-файлов целесообразно применять библиотеки, например OpenCSV или Apache Commons CSV. Они поддерживают чтение строк с кавычками, экранирование символов и преобразование в объекты Java. В ручном разборе важно учитывать пустые поля, двойные кавычки и возможные пробелы перед разделителями, чтобы сохранить корректность данных.
Преобразование строки в массивы и коллекции для дальнейшей обработки
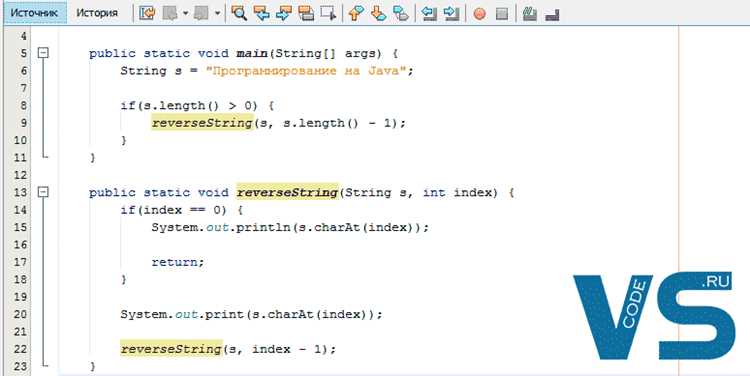
Преобразование строки в массивы и коллекции облегчает манипуляцию данными и их последующую обработку. Метод split() возвращает массив строк, который можно напрямую использовать или конвертировать в коллекцию через Arrays.asList(). Например, строка «apple,banana,orange» после split(«,») создаёт массив, а List<String> fruits = Arrays.asList(array) – список для операций фильтрации и сортировки.
Для динамического изменения набора элементов используют ArrayList. Пример преобразования:
| Действие | Пример |
|---|---|
| Разделение строки | String[] parts = input.split(«,»); |
| Преобразование в список | List<String> list = new ArrayList<>(Arrays.asList(parts)); |
| Фильтрация элементов | list.removeIf(s -> s.isEmpty()); |
| Преобразование обратно в строку | String result = String.join(«;», list); |
Такой подход особенно полезен при работе с вводом пользователя, CSV-параметрами или логами, где порядок и количество элементов заранее неизвестны. Конвертация в коллекцию позволяет применять стандартные методы сортировки, фильтрации и поиска, минимизируя ручной перебор массива.
Вопрос-ответ:
Как правильно разделить строку с несколькими разделителями в Java?
Для строк с повторяющимися или сложными разделителями используют метод split() с регулярным выражением. Например, строка «A;;B;C» разбивается через split(«;+»), что позволяет избежать пустых элементов массива. Такой подход удобен при обработке CSV-подобных данных или пользовательских форм, где возможны двойные или тройные разделители.
Когда стоит использовать substring() вместо split() для выделения части строки?
Метод substring() применяют, если известны точные позиции символов, которые нужно извлечь. Например, при разборе даты «2025-11-14T21:08» можно получить год через substring(0,4), месяц — substring(5,7). Такой способ подходит для фиксированных форматов логов или протоколов, где позиции значений стабильны.
Как с помощью регулярных выражений извлечь несколько числовых значений из строки?
Используют класс Pattern для компиляции выражения и Matcher для поиска совпадений. Для строки «item1:12, item2:45, item3:78» шаблон \\d+ позволит последовательно извлечь все числа в цикле while(matcher.find()). Это удобно при обработке логов, финансовых данных или любых текстов с повторяющимися числовыми элементами.
Какие способы преобразования строки в коллекции Java наиболее подходят для работы с CSV?
Строку можно разделить через split(), получить массив и затем преобразовать его в ArrayList с помощью Arrays.asList(). Для CSV со сложными кавычками и вложенными запятыми лучше применять специализированные библиотеки, например OpenCSV или Apache Commons CSV. Это позволяет корректно обработать экранированные значения, пустые поля и формировать коллекции для фильтрации и сортировки.