Содержание статьи

Словарь со списками подходит для задач, где требуется сгруппировать несколько значений под одним ключом: например, распределить данные по категориям, собрать результаты вычислений или организовать структуры для последующей фильтрации. Такой формат упрощает обработку информации, поскольку доступ к каждому набору значений осуществляется напрямую по ключу.
При работе с подобной структурой важно решить, каким способом создавать словарь: вручную, через цикл, с помощью defaultdict или через метод setdefault. Каждый вариант подходит для определённых сценариев, поэтому выбор зависит от ожидаемых операций – частоты добавления элементов, проверки ключей и объёмов данных.
Также имеет значение корректная обработка отсутствующих ключей. Ошибки возникают, когда программа пытается обратиться к несуществующему элементу. Грамотно выбранный метод инициализации позволяет избежать лишних проверок и упростить последующую логику.
Отдельного внимания требует способ добавления элементов в списки внутри словаря. Встроенные методы Python помогают исключить перезапись данных и поддерживать структуру в предсказуемом состоянии, что особенно важно при обработке динамических наборов значений.
Определение структуры словаря для хранения наборов данных

Перед созданием словаря важно определить тип ключей, формат списков и предполагаемые операции с данными. Чёткая структура облегчает последующую модификацию и уменьшает количество проверок во время выполнения программы.
Практичные параметры для планирования:
- тип ключей: строки для категорий, числа для индексов, кортежи для составных идентификаторов;
- тип элементов внутри списков: строки, числа, словари, пользовательские объекты;
- порядок добавления: фиксированный, произвольный или формируемый через циклы;
- ограничения: максимальная длина списка, уникальность элементов, допустимость пустых наборов;
- поведение при отсутствии ключей: создание автоматически или строгая проверка перед обращением.
Для удобства можно подготовить шаблон структуры, чтобы поддерживать единый формат данных во всём проекте:
- описать список необходимых ключей;
- назначить каждому ключу пустой список или стартовый набор значений;
- зафиксировать правила добавления и удаления элементов;
- определить, требуется ли сортировка или контроль уникальности;
- выбрать способ обработки неверных ключей.
Такая подготовка снижает вероятность непредсказуемых ситуаций при работе с данными и формирует понятную структуру, которую легко поддерживать и расширять.
Инициализация пустого словаря со списками разными способами
Пустой словарь можно создать через литерал {} и затем добавлять ключи по мере необходимости. Такой вариант подходит для случаев, когда структура формируется постепенно.
Второй способ – использование конструктора dict(). Он эквивалентен литералу, но удобен при передаче параметров или автоматической генерации структуры.
Для автоматического создания списка при первом обращении к ключу применяется defaultdict из модуля collections. Этот инструмент устраняет необходимость проверок и позволяет сразу добавлять элементы:
defaultdict(list) создаёт новый пустой список каждый раз, когда ключ используется впервые.
Альтернативный вариант – метод setdefault. Он добавляет в словарь ключ с пустым списком, если его не существует, и возвращает ссылку на созданный или существующий список. Такой подход удобен, когда требуется использовать обычный словарь без дополнительных классов.
При выборе способа инициализации важно учитывать частоту обращений к отсутствующим ключам и требования к контролю структуры. В ситуациях, где словарь активно наполняется в циклах, defaultdict(list) сокращает количество проверок, а при статичном наполнении достаточно литерала или конструктора.
Добавление новых списков в словарь по заданным ключам
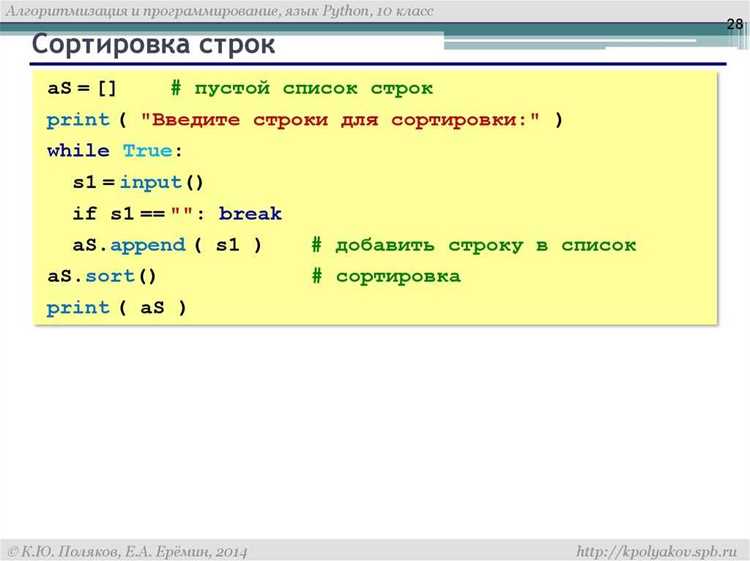
При добавлении нового списка важно убедиться, что ключ не используется ранее. Простая проверка через оператор in позволяет избежать перезаписи существующих данных. Если ключ отсутствует, ему можно назначить пустой список или заранее подготовленный набор элементов.
Для добавления списка вручную используется конструкция вида: data[key] = []. Такой способ подходит, когда структура словаря формируется заранее и набор ключей известен.
Если ключи создаются динамически, удобен метод setdefault. Он добавляет пустой список только при первом обращении, что позволяет безопасно инициализировать структуру без дополнительных проверок: data.setdefault(key, []).
В ситуациях, когда требуется автоматическое создание списка без ручных условий, можно использовать defaultdict(list). Он формирует новый список при первом появлении ключа, что снижает риск ошибок при наполнении словаря в циклах.
Если требуется сохранить предсказуемый порядок ключей, стоит инициализировать словарь заранее, перечислив все допустимые ключи. Такой подход удобен в задачах, где каждый список должен существовать независимо от того, получит он элементы или нет.
Пополнение существующих списков элементами без перезаписи данных
Перед добавлением элементов важно убедиться, что список уже создан. При обращении к несуществующему ключу возникнет ошибка, поэтому используется проверка через in или метод setdefault, возвращающий готовый список.
Для добавления одного элемента применяется метод append(). Он помещает значение в конец списка и не затрагивает уже сохранённые данные. Такой вариант подходит для последовательного накопления результатов.
Если требуется добавить сразу несколько элементов, удобен метод extend(). Он принимает любую итерируемую структуру и разворачивает её в текущий список. Это полезно при загрузке порций данных из внешних источников.
При необходимости вставить элемент в определённую позицию используется insert(). Он позволяет контролировать порядок значений, что важно при формировании структур, где положение элемента влияет на дальнейшие вычисления.
Чтобы исключить повторяющиеся значения, можно проводить проверку перед добавлением: if item not in data[key]. Такой подход сохраняет корректность списка, если он должен содержать только уникальные элементы.
Обработка отсутствующих ключей при работе со словарём списков

Обращение к отсутствующему ключу вызывает KeyError. Чтобы этого избежать, используется проверка через оператор in: if key in data. Такой подход позволяет добавлять новые списки только при необходимости и контролировать структуру.
Метод get() возвращает значение по ключу или указанное значение по умолчанию. Для списков это удобно: data.get(key, []). При этом важно помнить, что временный список не добавляется в словарь автоматически.
Метод setdefault() создаёт новый список, если ключ отсутствует, и возвращает его для последующего заполнения: data.setdefault(key, []). Это снижает количество проверок при динамическом добавлении элементов.
Использование defaultdict(list) автоматически создаёт пустой список при первом обращении к отсутствующему ключу. Такой способ удобен при обработке циклов и больших наборов данных, когда набор ключей заранее неизвестен.
Для фиксированных структур словарь можно инициализировать заранее всеми ключами с пустыми списками. Это исключает появление неожиданных ключей и упрощает контроль данных при дальнейшей обработке.
Перебор словаря со списками для извлечения и анализа значений
Для обработки словаря со списками чаще всего используется цикл for по ключам или элементам пары ключ–значение. Такой перебор позволяет последовательно получать списки и выполнять с ними нужные операции: суммирование, фильтрацию, сортировку.
Пример перебора с использованием items():
for key, values in data.items():
for item in values:
# обработка каждого элемента
Для наглядного анализа данных удобно представлять словарь в виде таблицы, где строки – ключи, а столбцы – элементы списков. Это облегчает сравнение и поиск закономерностей:
| Ключ | Элемент 1 | Элемент 2 | Элемент 3 |
|---|---|---|---|
| Категория A | 10 | 15 | 20 |
| Категория B | 5 | 7 | 12 |
| Категория C | 8 | 14 | 19 |
Для динамических списков можно использовать функцию enumerate(), чтобы одновременно получать индекс элемента и его значение, что полезно при подсчёте или изменении элементов внутри списка.
При необходимости объединения данных из всех списков используют генераторы списков или функции chain из модуля itertools. Это ускоряет анализ больших наборов данных и позволяет применять агрегирующие функции без промежуточных структур.
Вопрос-ответ:
Как создать словарь со списками в Python с заранее известными ключами?
Если ключи известны заранее, можно инициализировать словарь так: data = {‘ключ1’: [], ‘ключ2’: [], ‘ключ3’: []}. Каждый ключ сразу получает пустой список, который потом заполняется данными. Такой подход удобен для фиксированных категорий и упрощает проверку наличия ключей при добавлении элементов.
Можно ли добавлять элементы в список словаря без проверки существования ключа?
Да, если использовать setdefault или defaultdict(list). Например, data.setdefault(key, []).append(value) создаёт пустой список для отсутствующего ключа и добавляет элемент. Это позволяет добавлять данные динамически, не проверяя вручную наличие ключа.
Как объединить все элементы списков в словаре в один общий список?
Можно использовать генератор списков или функцию chain из модуля itertools. Например: from itertools import chain; all_values = list(chain.from_iterable(data.values())). Это создаёт плоский список из всех значений словаря, удобный для подсчёта или фильтрации данных.
Как избежать дублирования элементов при добавлении в списки словаря?
Перед добавлением элемента можно проверять его наличие в списке: if value not in data[key]: data[key].append(value). Для больших наборов данных альтернативой служат множества: data[key] = set(), затем data[key].add(value). Это гарантирует уникальность значений и ускоряет поиск повторов.