Доверительный интервал (ДИ) – это статистическая мера, которая позволяет оценить диапазон значений, в котором с определенной вероятностью находится истинное значение параметра популяции. В Excel для вычисления ДИ используются встроенные функции, которые позволяют легко и точно рассчитать его на основе выборки данных. Основные параметры, которые влияют на расчет, – это среднее значение выборки, стандартное отклонение и размер выборки.
Для построения доверительного интервала в Excel важно понимать, как правильно использовать функцию CONFIDENCE или ее более актуальные версии, такие как CONFIDENCE.NORM и CONFIDENCE.T, которые отличаются по методу расчета в зависимости от того, известна ли стандартная ошибка и применяются ли данные о нормальном распределении. Важно выбрать правильную функцию в зависимости от ситуации: CONFIDENCE.NORM используется при больших выборках или известном распределении, а CONFIDENCE.T – для малых выборок.
Для начала необходимо подготовить данные: собрать выборку и вычислить среднее и стандартное отклонение. Для этого используются стандартные функции Excel: AVERAGE для среднего и STDEV.P или STDEV.S для стандартного отклонения (в зависимости от того, работаете ли вы с генеральной совокупностью или выборкой). После этого можно рассчитывать доверительный интервал по формуле, которая зависит от уровня доверия (например, 95% или 99%). Для 95% доверительного интервала коэффициент Z для нормального распределения составляет примерно 1.96, а для более точных вычислений – можно использовать функцию для t-распределения.
Как построить доверительный интервал в Excel шаг за шагом
Для начала определим, что такое доверительный интервал. Это диапазон значений, в котором с определённой вероятностью будет находиться истинное значение параметра генеральной совокупности. В Excel можно легко вычислить доверительный интервал для среднего значения выборки, используя встроенные функции.
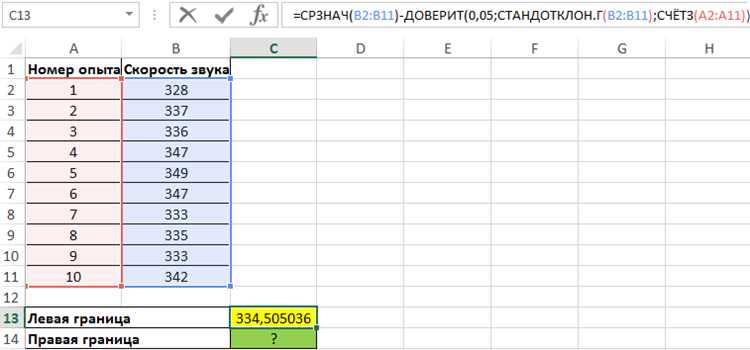
Шаг 1: Подготовка данных. Убедитесь, что ваши данные занесены в одну колонку Excel. Для вычислений доверительного интервала необходимо, чтобы все данные были числовыми. Если данные включают ошибки или пропуски, их нужно обработать или удалить.
Шаг 2: Рассчитаем среднее значение. Для этого используйте функцию AVERAGE. Например, если ваши данные находятся в ячейках A2:A11, введите в пустую ячейку: =AVERAGE(A2:A11). Это даст вам среднее значение выборки.
Шаг 3: Рассчитаем стандартное отклонение. Для этого используйте функцию STDEV.S (для выборки). Введите формулу: =STDEV.S(A2:A11). Стандартное отклонение покажет, насколько данные отклоняются от среднего.
Шаг 4: Определение объема выборки. Подсчитайте количество элементов в выборке, используя функцию COUNT. Для выборки в диапазоне A2:A11 это будет выглядеть так: =COUNT(A2:A11).
Шаг 5: Вычисление ошибки среднего. Ошибка среднего рассчитывается как стандартное отклонение, делённое на квадратный корень из размера выборки. Для этого используйте формулу: STDEV.S(A2:A11)/SQRT(COUNT(A2:A11)).
Шаг 6: Установите уровень доверия. Обычно для большинства задач используется уровень доверия 95%. Для этого используйте T.INV.2T, который вычисляет t-статистику для заданного уровня доверия. Формула будет выглядеть так: =T.INV.2T(0.05, COUNT(A2:A11)-1).
Шаг 7: Построение доверительного интервала. Теперь, когда у вас есть ошибка среднего и t-статистика, вычислим границы доверительного интервала. Верхняя граница будет равна: Среднее + (t-статистика * ошибка среднего), а нижняя: Среднее — (t-статистика * ошибка среднего). Примените эти формулы в Excel для вычисления границ.
Подготовка данных для расчета доверительного интервала
Для правильного расчета доверительного интервала необходимо иметь точные данные. Во-первых, нужно проверить корректность и полноту исходных данных. Это может включать удаление дубликатов, устранение пропущенных значений или замену выбросов, которые могут исказить результаты. В Excel для таких целей полезно использовать фильтры и инструменты для поиска и исправления ошибок, такие как «Удалить дубликаты» или «Заполнение пропусков».
Далее важно убедиться, что данные распределены нормально, так как многие статистические методы требуют нормальности. Чтобы проверить это, можно построить гистограмму или использовать функцию анализа данных в Excel для выполнения тестов на нормальность, например, с помощью критерия Шапиро-Уилка или других методов, доступных через надстройки Excel.
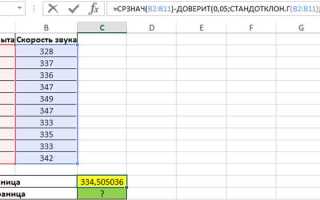
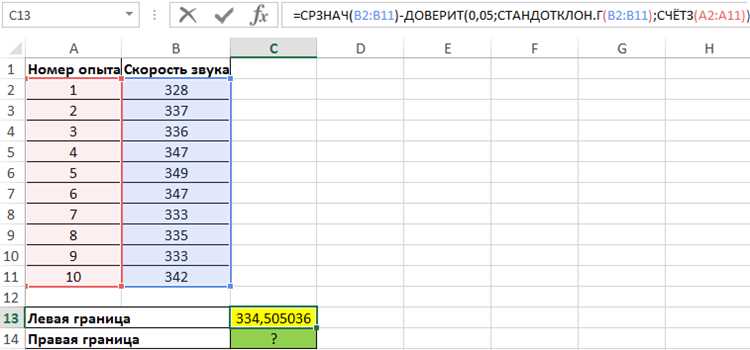
Для расчета доверительного интервала, в зависимости от ситуации, необходимо определить выборочную среднюю величину и стандартное отклонение. Если у вас есть доступ к полному набору данных, вычислите эти показатели вручную или с помощью стандартных функций Excel, таких как СРЗНАЧ и СТАНДОТКЛОН. Если же данные представлены в виде выборки, для получения правильных результатов следует использовать стандартное отклонение выборки (S), а не всего генерального населения.
Если вы работаете с выборочными данными, важно также определить размер выборки. Это можно сделать с помощью функции СЧЁТ в Excel, которая позволяет подсчитать количество элементов в диапазоне. Размер выборки влияет на точность расчетов доверительного интервала и необходим для правильного использования формул и статистических таблиц для нахождения критических значений, таких как t-статистика или z-статистика.
Выбор уровня значимости для интервала
Уровень значимости, обозначаемый как α, представляет собой вероятность того, что ошибочно отклонится гипотеза о точности интервала. Для уровня значимости 0.05 вероятность того, что истинное значение не попадет в интервал, составляет 5%. Это означает, что в 95% случаев мы будем уверены в том, что интервал охватывает реальный параметр.
При расчете доверительного интервала в Excel выбор уровня значимости влияет на ширину интервала. Чем ниже α, тем шире интервал, так как мы требуем большей уверенности в результатах. Например, для уровня значимости 0.01 интервал будет шире, чем для 0.05, что уменьшает риск ошибки первого рода (отклонение истинной гипотезы). Однако это также снижает точность, поскольку интервал становится более обширным.
Для специфических задач может потребоваться выбрать уровень значимости, отличающийся от стандартных 0.05 или 0.01. Например, в медицине или фармацевтике часто используют уровень значимости 0.01, чтобы минимизировать вероятность ошибки, в то время как в социальных науках уровень значимости 0.10 может быть вполне допустимым.
- 0.05 – самый распространенный выбор в научных исследованиях и экономике.
- 0.01 – используется, когда требуется высокая точность и минимизация ошибок.
- 0.10 – допустим в случаях, когда точность не является критической, например, в маркетинговых исследованиях.
В Excel для расчета доверительного интервала используется стандартная формула, где уровень значимости влияет на коэффициент t-критерия для заданного количества степеней свободы. Это ключевой момент, поскольку значение t-критерия непосредственно связано с выбранным уровнем значимости, который в свою очередь влияет на величину погрешности интервала.
Важно помнить, что выбор уровня значимости должен быть осознанным. Он зависит от специфики задачи, желаемой точности и допустимого риска ошибки. В случае сомнений, можно провести анализ для различных уровней значимости и сравнить результаты для более уверенного выбора.
Расчет средней выборки в Excel
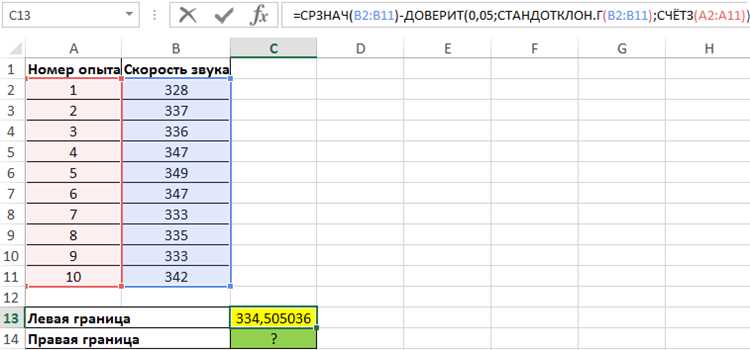
Для расчета средней выборки в Excel используется функция СРЗНАЧ. Это один из самых простых методов для определения центральной тенденции данных, и он доступен в любой версии программы. Средняя выборка рассчитывается как сумма всех значений выборки, деленная на количество этих значений.
Предположим, у вас есть набор данных в диапазоне ячеек A1:A10, и вам нужно вычислить среднее значение. В ячейке B1 просто введите формулу: =СРЗНАЧ(A1:A10). Эта формула даст вам среднее арифметическое всех чисел в указанном диапазоне.
Если вы работаете с выборкой данных, важно помнить, что для корректного вычисления средней выборки следует исключать из анализа пустые ячейки или текстовые значения. Excel сам их игнорирует, но для точности можно использовать формулу с проверкой данных, например, =СРЗНАЧЕСЛИ(A1:A10;»<>0″), которая исключает нулевые значения.
При наличии пропусков или ошибок в данных используйте функцию ЕСЛИОШИБКА. Например, чтобы избежать ошибки при делении на ноль в формуле среднего, используйте =ЕСЛИОШИБКА(СРЗНАЧ(A1:A10);0). Эта формула заменит ошибку на ноль, если она возникнет.
При расчете средней выборки полезно также понимать, как работает функция для данных с разными типами распределений. Например, если вы имеете дело с выборкой с выбросами, среднее может быть сильно искажено. Для такой ситуации стоит рассматривать другие статистические меры, такие как медиана или мода.
В Excel также доступны инструменты для визуализации данных, которые помогают лучше понять, как средняя выборка соотносится с другими показателями. Например, диаграммы с точками, такие как диаграмма рассеяния, позволяют наглядно увидеть, как распределяются данные относительно среднего значения.
| Ячейка | Значение |
|---|---|
| A1 | 5 |
| A2 | 8 |
| A3 | 10 |
| A4 | 4 |
| A5 | 7 |
| A6 | 6 |
| A7 | 9 |
| A8 | 3 |
| A9 | 2 |
| A10 | 6 |
Если среднее значение нужно рассчитать для выборки с различными весами, используйте функцию СРЗНАЧ.ВЕС. Например, для весов в диапазоне B1:B10 можно использовать формулу =СРЗНАЧ.ВЕС(A1:A10;B1:B10). Это полезно, когда значения в выборке имеют разное значение для анализа, и нужно учесть вес каждого наблюдения.
Вычисление стандартного отклонения выборки
В Excel расчет стандартного отклонения выборки можно выполнить с помощью встроенной функции STDEV.S. Для этого достаточно указать диапазон ячеек, содержащих данные. Например, если ваши данные находятся в ячейках A1:A10, формула будет выглядеть так: =STDEV.S(A1:A10).
Однако важно учитывать, что Excel по умолчанию использует корректировку на степень свободы, деля на n — 1, а не на n, как это делается в случае для всей популяции. Эта корректировка необходима, чтобы уменьшить смещение оценки стандартного отклонения для выборки, особенно при малом размере выборки.
Если у вас есть данные для всего населения, то следует использовать функцию STDEV.P, которая рассчитывает стандартное отклонение по формуле, деля на n, а не на n — 1.
Также, важно помнить, что если в данных присутствуют выбросы или ошибки измерений, стандартное отклонение может сильно измениться, что сделает анализ менее точным. Поэтому рекомендуется предварительно проверять данные на наличие аномальных значений.
Для более глубокого анализа можно сравнивать стандартные отклонения различных выборок, что поможет оценить степень вариации в разных группах данных. Это особенно полезно при проведении статистических тестов и построении доверительных интервалов.
Определение размера выборки для интервала
Для расчёта размера выборки используется формула, которая зависит от желаемой точности интервала (погрешности), уровня значимости и стандартного отклонения. Это позволяет сбалансировать качество и стоимость исследования. Размер выборки можно определить с помощью следующей формулы:
- n = (Z * σ / E)^2
где n – размер выборки, Z – критическое значение для заданного уровня доверия, σ – стандартное отклонение популяции, E – погрешность (точность) интервала.
Для более точных расчётов в реальных условиях часто используется оценка стандартного отклонения из данных выборки, если полное стандартное отклонение неизвестно. В этом случае формула немного изменяется, и вместо σ используется s – выборочное стандартное отклонение. Важно понимать, что использование точного значения критической точки Z, которое зависит от уровня доверия (например, для 95% Z = 1.96), критично для расчётов.
Кроме того, для определения размера выборки полезно учесть целевую погрешность, которая должна быть задана заранее. Если погрешность слишком велика, доверительный интервал будет слишком широким, что уменьшит точность прогнозов. С другой стороны, слишком малая погрешность потребует значительных затрат на сбор данных.
В Excel для определения необходимого размера выборки можно использовать функцию, которая рассчитает требуемый объём данных при заданных параметрах. Рассчитать это вручную возможно, но Excel упростит процесс, предоставив точные данные для всех параметров.
Помимо формулы для теоретических расчётов, существует практическое правило: при недостаточности данных или отсутствии информации о популяции, часто используют подходы с предварительным анализом выборки, проводя пилотные исследования, которые могут помочь уточнить параметры для окончательного расчёта.
Таким образом, корректно определённый размер выборки влияет на качество построенного доверительного интервала. Он должен быть достаточно большим, чтобы результат был статистически значимым, но не слишком большим, чтобы не увеличивать затраты и сложность анализа.
Вопрос-ответ:
Что такое доверительный интервал и зачем он нужен?
Доверительный интервал — это диапазон значений, который используется для оценки неизвестного параметра в статистике, например, среднего значения. Он помогает понять, насколько точно полученные данные могут отражать реальное значение в популяции. Например, если мы проводим исследование по росту людей в стране, доверительный интервал даст нам представление о том, в каком диапазоне находится истинное среднее значение роста.
Как в Excel построить доверительный интервал для среднего?
Для того чтобы построить доверительный интервал в Excel, нужно выполнить несколько шагов. Сначала вычислить среднее значение выборки, затем стандартное отклонение. Далее с помощью функции CONFIDENCE.T можно найти половину ширины интервала. Для этого нужно указать уровень значимости (например, 0,05 для 95% доверительного интервала), стандартное отклонение и размер выборки. Полученную величину нужно добавить и вычесть от среднего значения, чтобы получить нижнюю и верхнюю границы интервала.
Какие данные мне нужно иметь для расчета доверительного интервала в Excel?
Для расчета доверительного интервала вам нужно иметь выборку данных, из которой будет вычисляться среднее значение и стандартное отклонение. Также важно знать размер выборки (количество элементов). Если вы хотите построить интервал для среднего значения, этих данных достаточно. Если же рассчитываете для других параметров, то могут понадобиться дополнительные расчеты.
Как интерпретировать полученный доверительный интервал?
Доверительный интервал показывает диапазон значений, в котором с определенной вероятностью (например, 95%) находится истинное значение исследуемого параметра. Если интервал для среднего роста людей составляет от 170 до 175 см, это означает, что с вероятностью 95% средний рост в популяции будет находиться в этом диапазоне. Чем уже интервал, тем точнее наша оценка. Однако стоит учитывать, что доверительный интервал не дает точного значения, а лишь указывает на возможный диапазон.
Как вычислить доверительный интервал в Excel?
Чтобы построить доверительный интервал в Excel, нужно выполнить несколько шагов. Сначала необходимо собрать данные, которые будут использованы для вычислений (например, выборка чисел). После этого в Excel можно использовать функцию СТЕПЕНЬОШИБКИ (STDEVP или STDEV.P для полной совокупности и STDEV.S для выборки), чтобы найти стандартное отклонение. Затем вычисляется среднее значение с помощью функции СРЕДНЕЕ (AVERAGE). Далее, для расчета доверительного интервала, нужно использовать формулу: среднее ± (критическое значение t) * (стандартная ошибка), где критическое значение t зависит от уровня значимости и числа наблюдений. В Excel для получения критического значения t можно использовать функцию ТРАМТРАМ (T.INV.2T). Это значение зависит от степени свободы и уровня значимости, например, для 95% доверительного интервала обычно берется значение 1.96 для нормального распределения.
Как выбрать уровень значимости для построения доверительного интервала в Excel?
Выбор уровня значимости для доверительного интервала зависит от того, насколько строгие критерии точности вам необходимы. Для большинства статистических анализов обычно выбирают уровень значимости 0.05, что соответствует 95%-му доверительному интервалу (это означает, что вероятность ошибки не больше 5%). Если вам нужно больше уверенности в точности, можно выбрать уровень значимости 0.01, что даст 99%-ный интервал. В Excel для работы с различными уровнями значимости вам нужно использовать соответствующие критические значения t, которые можно найти через функцию ТРАМТРАМ (T.INV.2T), указав нужное значение уровня значимости. Чем ниже уровень значимости, тем шире будет ваш интервал, что дает больше уверенности, но менее точные данные.