Apache Kafka представляет собой распределённую систему обмена сообщениями, разработанную для обработки больших объёмов данных в режиме реального времени. В основе работы Kafka лежит модель публикации и подписки на топики, которые делятся на партиции для обеспечения параллельной обработки и масштабирования нагрузки. Каждый топик хранит данные последовательно, что позволяет потребителям считывать сообщения с любой позиции.
Kafka использует брокеры для хранения и передачи сообщений, а кластерная архитектура обеспечивает высокую доступность и отказоустойчивость. Данные реплицируются между узлами, что минимизирует риск потери информации при сбое отдельных брокеров. Конфигурация репликации и стратегия распределения партиций напрямую влияют на производительность и стабильность системы.
Для интеграции с приложениями Kafka предлагает клиентские библиотеки на популярных языках программирования. Процесс публикации сообщений осуществляется с контролем подтверждений, что позволяет выбрать уровень надёжности доставки – от минимальной до полной гарантии. Потребители могут организовывать группы для параллельного чтения сообщений, что увеличивает скорость обработки данных.
Применение Kafka особенно актуально для потоковой аналитики, мониторинга событий, синхронизации микросервисов и передачи данных между распределёнными системами. Настройка параметров задержки, размера партий и времени хранения сообщений позволяет адаптировать систему под конкретные нагрузки и требования приложений.
Архитектура Kafka и роль брокеров в передаче сообщений
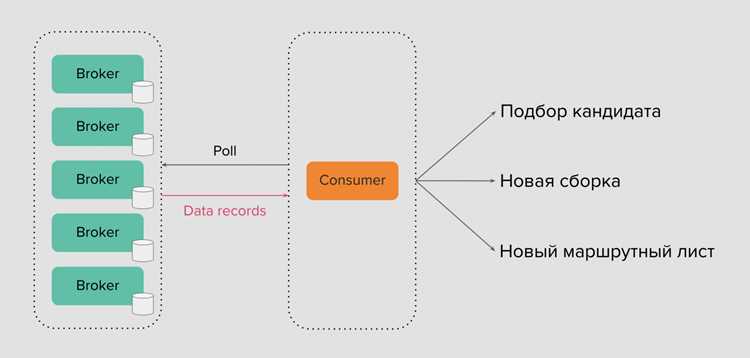
Kafka строится на принципе распределённого кластера, состоящего из одного или нескольких брокеров. Каждый брокер хранит данные топиков в виде партиций и отвечает за приём, хранение и передачу сообщений. Партиции делят нагрузку между брокерами, обеспечивая параллельную обработку и возможность горизонтального масштабирования.
Брокеры используют репликацию партиций для обеспечения отказоустойчивости. Реплика главной партиции (leader) обслуживает все запросы на запись и чтение, а реплики-следователи (followers) синхронизируются с лидером. При сбое лидера один из последователей автоматически становится новым лидером, что позволяет системе продолжать работу без потери данных.
Kafka хранит сообщения в логах с последовательной записью, что уменьшает нагрузку на диск и ускоряет чтение. Каждый брокер индексирует сообщения по смещению (offset), что позволяет потребителям считывать данные независимо и повторно при необходимости. Правильная настройка количества брокеров, репликаций и партиций критична для стабильной передачи данных и равномерного распределения нагрузки.
Для управления кластером применяются Zookeeper или встроенный Kafka Raft Metadata mode (KRaft), которые координируют распределение лидеров и следователей. Это обеспечивает согласованность состояния брокеров и предотвращает потерю сообщений при добавлении или удалении узлов.
Формат сообщений и работа с топиками и партициями
Сообщения в Kafka хранятся в бинарном формате с ключом, значением и метаданными, включая смещение (offset) и временную метку. Ключ используется для определения партиции, что позволяет направлять связанные сообщения в одну партицию для последовательной обработки. Значение может быть в формате JSON, Avro, Protobuf или любом другом, поддерживаемом клиентской библиотекой.
Топики представляют собой логические каналы передачи сообщений. Каждый топик делится на партиции, которые распределяются между брокерами. Партиции обеспечивают параллельное чтение и запись, а количество партиций влияет на скорость обработки и масштабируемость системы. При проектировании топиков важно учитывать нагрузку и распределение ключей для предотвращения «горячих» партиций.
Потребители читают данные с помощью смещений, что позволяет повторно обрабатывать сообщения или начинать чтение с определённой позиции. Для групп потребителей Kafka автоматически распределяет партиции между участниками группы, обеспечивая, чтобы каждое сообщение обрабатывалось только одним потребителем внутри группы.
Рекомендовано использовать ключи сообщений для событий, требующих последовательной обработки, и настраивать количество партиций в зависимости от ожидаемого потока данных. Также стоит контролировать размер сообщений и время хранения, чтобы избежать переполнения дисков и поддерживать стабильную производительность кластера.
Процесс публикации и потребления данных в Kafka

Публикация сообщений в Kafka осуществляется через продюсеров, которые отправляют данные в определённый топик. Продюсер может использовать ключ для выбора партиции или позволить Kafka распределять сообщения автоматически. Основные параметры публикации включают:
- acks – уровень подтверждений от брокеров: 0 (без подтверждения), 1 (только лидер), all (все реплики);
- batch.size – размер пакета сообщений для отправки одним запросом;
- linger.ms – время ожидания накопления пакета перед отправкой.
Потребление данных организуется через группы потребителей. Kafka гарантирует, что каждая партиция распределяется между участниками группы, исключая дублирующую обработку. Основные элементы процесса потребления:
- Подключение к брокерам и выбор топиков для чтения;
- Чтение сообщений по смещению (offset) с возможностью ручного или автоматического подтверждения;
- Обработка сообщений и фиксация смещений для контроля состояния группы;
- Обновление баланса партиций при добавлении или удалении потребителей в группе.
Рекомендуется настраивать размер пакетов и частоту фиксации смещений с учётом объёма сообщений и требований к задержке. Для критически важных данных следует использовать подтверждения всех реплик и включать повторные попытки отправки в случае ошибок сети или отказов брокеров.
Гарантии доставки сообщений и настройка подтверждений
Kafka предоставляет три уровня гарантии доставки сообщений: at most once, at least once и exactly once. Настройка продюсеров и потребителей определяет, какой уровень будет обеспечен в конкретной системе.
Ключевые параметры для настройки подтверждений:
| Параметр | Описание | Рекомендации |
|---|---|---|
| acks | Количество подтверждений от брокеров перед считанием сообщения успешным | 0 – минимальная задержка, возможна потеря данных; 1 – подтверждение лидера; all – подтверждение всех реплик для максимальной надёжности |
| retries | Количество попыток повторной отправки при сбое | Устанавливать в зависимости от критичности данных, обычно 3–5 |
| enable.idempotence | Включение идемпотентной отправки для предотвращения дублирования сообщений | Рекомендуется включать для exactly once доставки |
Для потребителей важно настроить автоматическое или ручное подтверждение смещений (offsets). Автоматическое подтверждение ускоряет обработку, но увеличивает риск потери данных при сбое. Ручное подтверждение позволяет фиксировать смещения после успешной обработки сообщений, что обеспечивает контроль и надёжность.
Рекомендовано сочетать подтверждения всех реплик с идемпотентной отправкой и ручным фиксированием смещений для критически важных потоков данных, особенно при интеграции с микросервисами и аналитическими системами.
Использование Kafka в масштабируемых приложениях
Kafka позволяет строить приложения с высокой пропускной способностью и распределённой обработкой данных. Масштабирование достигается за счёт партиционирования топиков и горизонтального увеличения числа брокеров.
Основные принципы применения Kafka в масштабируемых системах:
- Разделение топиков на партиции для параллельной обработки сообщений различными потребителями.
- Использование групп потребителей для балансировки нагрузки между экземплярами приложения.
- Настройка репликации партиций для обеспечения доступности данных при сбое узлов.
- Идемпотентная отправка сообщений продюсерами для предотвращения дублирования при повторных попытках.
Рекомендации по конфигурации:
- Определять оптимальное количество партиций с учётом ожидаемого потока сообщений и числа потребителей.
- Сохранять небольшие партии сообщений для снижения задержки, но не менее 1–5 КБ для уменьшения нагрузки на сеть.
- Использовать мониторинг задержки и пропускной способности через метрики брокеров для своевременной балансировки нагрузки.
- При горизонтальном масштабировании добавлять брокеры и перераспределять партиции, минимизируя влияние на работу приложений.
Применение этих подходов позволяет поддерживать стабильную обработку больших потоков данных и обеспечивает гибкость при росте нагрузки или расширении функциональности системы.
Мониторинг и управление производительностью кластера Kafka
Эффективный мониторинг кластера Kafka обеспечивает стабильную работу и своевременное обнаружение узких мест. Основные показатели для отслеживания:
- Throughput – количество сообщений и объём данных, передаваемых на продюсер и потребитель в секунду;
- Lag потребителей – задержка между последним записанным смещением и текущим смещением группы потребителей;
- Использование диска – уровень заполнения логов партиций на брокерах;
- Репликация – состояние синхронизации лидеров и следователей для каждой партиции;
- Сетевые метрики – задержки и пропускная способность между брокерами и клиентами.
Инструменты для мониторинга:
- JMX-метрики Kafka для интеграции с системами Prometheus, Grafana, Zabbix;
- Kafka Cruise Control для автоматического балансирования партиций и управления нагрузкой;
- Логи брокеров для анализа ошибок, повторов и временных пиков нагрузки.
Рекомендации по управлению производительностью:
- Регулярно проверять нагрузку на отдельные партиции и при необходимости перераспределять их между брокерами.
- Контролировать размер сообщений и параметры batch.size и linger.ms у продюсеров для снижения задержек.
- Настраивать репликацию и минимальное количество синхронизированных реплик с учётом требований к надёжности.
- Использовать горизонтальное масштабирование брокеров при увеличении потока данных.
Комплексный мониторинг и своевременная оптимизация параметров кластера позволяют поддерживать стабильную обработку потоков данных и предотвращать потерю сообщений при пиковых нагрузках.
Вопрос-ответ:
Как Kafka обеспечивает надёжную доставку сообщений между продюсером и потребителем?
Kafka использует систему партиций и репликаций для гарантированной передачи данных. Сообщения записываются в лог партиции, а каждая партиция имеет лидера и один или несколько последователей. Продюсер может выбрать уровень подтверждения (acks): 0 — без подтверждения, 1 — подтверждение лидера, all — подтверждение всех реплик. Потребители отслеживают смещения (offset) и могут фиксировать их вручную после обработки, что позволяет предотвратить потерю или дублирование сообщений.
В чём разница между топиком и партицией в Kafka и как их правильно использовать?
Топик в Kafka представляет собой логический канал для публикации сообщений, а партиции — физические разделы топика, которые распределяются между брокерами. Партиции позволяют обрабатывать данные параллельно и масштабировать систему. Для равномерного распределения нагрузки рекомендуется использовать ключи сообщений, чтобы связанные события попадали в одну партицию, и настраивать количество партиций с учётом числа потребителей и объёма данных.
Какие методы мониторинга кластера Kafka помогают предотвращать перегрузки и сбои?
Мониторинг включает отслеживание throughput, задержки потребителей, заполнения дисков, синхронизации реплик и сетевых задержек. Для анализа используют JMX-метрики, интеграцию с Prometheus и Grafana, Kafka Cruise Control для балансировки партиций и логи брокеров. Регулярная проверка этих параметров позволяет вовремя перераспределять партиции, корректировать параметры batch.size и linger.ms, а также добавлять брокеры при увеличении нагрузки.
Как настроить продюсер и потребителя Kafka для работы с большими объёмами сообщений?
Продюсер должен использовать параметры batch.size и linger.ms для формирования оптимальных пакетов сообщений, включать идемпотентную отправку (enable.idempotence) и повторные попытки (retries) для надёжности. Потребители лучше объединять в группы для параллельного чтения партиций и фиксировать смещения вручную, чтобы избежать потери сообщений при сбоях. Также рекомендуется контролировать размер сообщений и репликацию партиций для поддержания стабильной пропускной способности при высоких объёмах данных.