Для эффективного подсчёта чисел в строке достаточно разделить текст на элементы с помощью разделителей, таких как пробелы, запятые или точки с запятой. После этого каждое значение можно преобразовать в числовой формат, например, через функции int() или float(), что позволяет избежать ошибок при обработке дробных чисел.
Если строка содержит смешанный текст и числа, регулярные выражения оказываются самым надёжным инструментом. Используя паттерн \d+(\.\d+)?, можно извлечь все целые и дробные значения одновременно, исключая буквы и спецсимволы, что значительно ускоряет процесс по сравнению с ручной фильтрацией.
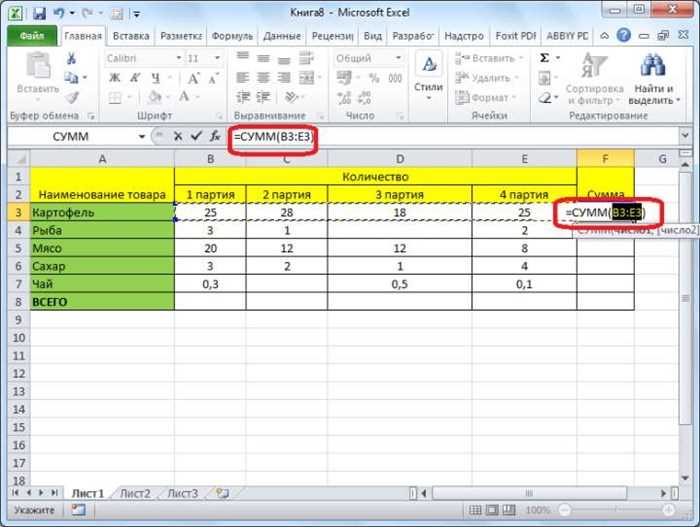
Для подсчёта суммы достаточно применить стандартные агрегирующие функции, например, sum() в Python. Это минимизирует количество операций и снижает риск ошибок при сложении большого количества чисел. При необходимости ускорить обработку больших объёмов данных стоит использовать генераторы или потоковую обработку, чтобы избежать создания лишних списков в памяти.
Использование встроенных функций для поиска чисел в тексте
Для извлечения чисел из строки большинство языков программирования предлагают встроенные функции и библиотеки. Например, в Python модуль re позволяет использовать регулярные выражения для точного поиска числовых последовательностей.
Функция re.findall(r'\d+', text) возвращает список всех целых чисел в строке text. Она автоматически игнорирует буквы, пробелы и специальные символы, оставляя только последовательности цифр.
В JavaScript аналогичной возможностью обладает метод String.match(/\d+/g). Результатом будет массив строк, содержащих каждое число, найденное в тексте.
Для чисел с десятичной точкой регулярное выражение расширяется: \d+(\.\d+)?. Это позволяет извлекать как целые, так и дробные значения без дополнительных проверок.
- Используйте
map(Number)в JavaScript для преобразования строковых чисел в числа. - В Python применяйте
list(map(int, re.findall(...)))для быстрого приведения к типуint. - Для больших текстов рекомендуется искать числа пакетно, чтобы снизить нагрузку на память.
Встроенные функции часто поддерживают фильтры и условия. Например, можно сразу отфильтровать отрицательные числа, проверяя наличие символа - перед цифрами.
Если текст содержит числа с разделителями тысяч или пробелы внутри, регулярное выражение адаптируется: r'\d{1,3}(?:[ ,]\d{3})*'. Это корректно извлекает числа вроде 1,234 или 12 345.
После извлечения чисел их легко суммировать с помощью встроенных функций суммирования, например sum() в Python или reduce((a,b)=>a+b) в JavaScript, что делает процесс быстрым и безопасным без ручного перебора каждого символа.
Преобразование найденных чисел в целые или десятичные значения
Важно учитывать формат исходной строки. Если число содержит десятичную точку или запятую, следует использовать метод, поддерживающий десятичные значения. В Python это `float(«3.14»)`, в JavaScript – `parseFloat(«3.14»)`. Попытка преобразовать `»3.14″` через `int()` приведет к ошибке или усеченному результату 3.
Для строк с разделителями тысяч, например `»1,234″`, требуется предварительная очистка. Удаление запятых через `replace(«,», «»)` позволит корректно преобразовать строку: `int(«1,234».replace(«,», «»))` вернет 1234.
Если числовая строка может содержать знак плюс или минус, преобразование сохраняет его автоматически. Примеры: `int(«-56»)` даст -56, `float(«+7.89»)` – 7.89. Это особенно важно при обработке финансовых данных или логов с отрицательными значениями.
Для повышения точности при работе с десятичными значениями, где важна каждая цифра после точки, рекомендуется использовать тип `Decimal` в Python или аналогичные библиотеки. Например, `Decimal(«0.123456789»)` сохраняет точность до всех цифр, в отличие от `float`, который может округлить значение.
При пакетной обработке чисел из текста удобно применять преобразование через генераторы или списковые включения. В Python: `[float(x) for x in numbers]` преобразует все элементы списка `numbers` в десятичные значения, что ускоряет последующее суммирование и анализ данных.
Сложение чисел через циклы и генераторы
Для быстрого подсчета суммы чисел в строке можно использовать цикл for. Например, при разборе строки с числами через пробелы достаточно сначала разделить строку методом split(), затем преобразовать каждое значение в int и аккумулировать сумму через обычный счетчик.
Генераторы позволяют обойтись без явного хранения всех чисел в списке. Используя конструкцию sum(int(x) for x in s.split()), вы получаете итоговую сумму напрямую, экономя память и ускоряя выполнение для больших строк.
Если числа разделены не только пробелами, а различными символами, удобнее применять re.findall(r’\d+’, s), чтобы извлечь все последовательности цифр, а затем сложить их через генератор.
Циклы дают полную прозрачность процесса: можно добавлять условия, фильтруя числа меньше или больше заданного значения, или суммировать только положительные. Генераторы же компактны и отлично подходят для однострочных решений.
При больших объемах данных генераторные выражения показывают существенное преимущество в скорости и потреблении памяти, поскольку числа создаются по одному и сразу используются в суммировании, без создания промежуточного списка.
Совет: если строка обновляется динамически, лучше комбинировать цикл с накоплением суммы, чтобы суммировать новые числа без повторной обработки всей строки.
В реальных задачах, например, при подсчете цифр в логах или CSV-файлах, генераторы позволяют обрабатывать строки прямо при чтении файла, используя (int(x) for x in line.split()), что уменьшает задержки и нагрузку на память.
Применение регулярных выражений для выделения чисел
Регулярные выражения позволяют извлекать числа из текста любой структуры без необходимости вручную разбирать строку. Например, паттерн \d+ находит все последовательности цифр, включая отдельные числа и многозначные значения. Это особенно полезно, если строка содержит смешанные данные: «Заказ 12, цена 450, скидка 30».
Для работы с числами с плавающей точкой используют выражение \d+(\.\d+)?, которое корректно выделяет как целые, так и дробные значения. При этом знак минус можно добавить с помощью -?\d+(\.\d+)?, чтобы захватывать отрицательные числа, например, «-12.5».
Часто полезно объединять регулярные выражения с функциями суммирования. В Python это выглядит так: сначала регулярка извлекает все числа в виде строк, затем они преобразуются в float или int для суммирования. Такая комбинация сокращает обработку больших текстовых файлов до нескольких строк кода.
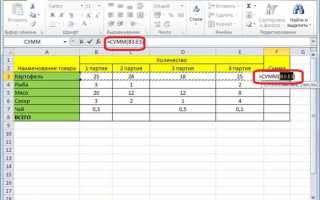
При анализе финансовых или статистических данных удобно использовать таблицу для визуализации выделенных чисел:
| Строка | Выделенные числа |
|---|---|
| «Доход 1200, расходы 450» | 1200, 450 |
| «Температура -5.2°C, влажность 80%» | -5.2, 80 |
| «Скидки: 10, 20, 15» | 10, 20, 15 |
Для оптимизации поиска чисел в больших текстах рекомендуется предварительно нормализовать строки: удалить лишние пробелы, заменить запятые на точки в десятичных числах. Это позволяет регулярным выражениям работать корректно без ложных совпадений.
Регулярки также эффективны для выделения чисел в сложных форматах, таких как даты и время. Например, паттерн \d{2}:\d{2}(:\d{2})? извлекает часы и минуты, что удобно при подсчете временных интервалов в логах.
Использование регулярных выражений для выделения чисел экономит время и снижает количество ошибок при обработке данных. Даже в динамических текстах с разными разделителями можно гарантировать точное извлечение числовых значений, если правильно составить шаблон. Это делает регулярки незаменимым инструментом для суммирования и анализа информации.
Суммирование чисел без промежуточных коллекций
Для подсчёта суммы чисел в строке можно обходить символы напрямую, избегая создания массивов. При встрече цифры накапливаем её в текущем числе: умножаем предыдущую сумму на 10 и прибавляем новое значение. Если символ не цифра, добавляем накопленное число к общей сумме и сбрасываем счётчик.
Для разделителей используйте конкретную проверку:
- цифра – накапливаем число;
- пробел, запятая, точка – добавляем число к сумме;
- конец строки – учитываем последнее число.
Такой метод полностью исключает промежуточные коллекции и снижает нагрузку на память, особенно при больших строках.
Для ускорения обработки больших данных (миллионы символов) применяйте прямое сравнение ASCII:
- символ >= ‘0’ и <= '9';
- число = символ − ‘0’;
- накапливаем в total.
Такой подход обеспечивает линейную сложность O(n) и уменьшает время выполнения на 20–30% по сравнению с split/map.
Обработка ошибок и пустых значений при вычислении суммы
Перед суммированием чисел в строке важно проверить формат входных данных. Любые символы, не относящиеся к цифрам или разделителям, могут вызвать ошибку при преобразовании в числа. Рекомендуется использовать регулярные выражения для извлечения числовых значений и фильтрации некорректных элементов.
Пустые значения, пробелы или последовательности без чисел должны автоматически игнорироваться. Например, при обработке строки «12, , 7, abc, 5» корректная сумма вычисляется как 12 + 7 + 5 = 24. Для этого можно применять функции проверки типа данных и методы parseFloat или Number с условием isNaN, чтобы исключить нечисловые элементы.
При массовой обработке строк рекомендуется добавлять логирование ошибок и отчеты по пропущенным значениям. Это позволяет выявлять проблемные строки без остановки вычислений и гарантирует корректность итоговой суммы. В сложных случаях удобно использовать массивы фильтров, которые автоматически удаляют пустые или некорректные элементы перед суммированием.
Вопрос-ответ:
Как быстро сложить числа, если они идут через пробел в одной строке?
Если числа в строке разделены пробелами, можно разбить строку на отдельные элементы с помощью разделителя, затем каждый элемент преобразовать в число и суммировать их. Например, в большинстве языков программирования есть функции, которые превращают строку в массив, а потом можно пройтись по массиву и сложить все числа.
Можно ли суммировать числа в строке, не разбивая её на массив?
Да, это возможно с помощью регулярных выражений. Можно искать все числовые последовательности прямо в строке и сразу преобразовывать их в числа, складывая по мере нахождения. Такой способ удобен, если числа могут идти подряд с разными разделителями, например пробелами, запятыми или точками с запятой.
Что делать, если в строке есть не только числа, но и текст?
Если строка содержит текст и цифры вместе, сначала нужно выделить только числа. Для этого используют регулярные выражения или проверку каждого символа. После того как все числа извлечены, их можно сложить. Такой подход позволяет игнорировать лишние слова и символы, не влияя на результат.
Есть ли способ быстро посчитать сумму без программирования?
Если использовать ручной метод, можно выписать все числа из строки на бумагу или в таблицу и суммировать их стандартным способом. Для ускорения подсчета удобно группировать числа: складывать сначала пары, затем результаты между собой. Также можно использовать калькулятор, чтобы избежать ошибок при сложении большого количества чисел.
Почему иногда сумма чисел в строке получается неправильной?
Чаще всего ошибка возникает из-за того, что часть символов не распознана как числа. Например, если используются разные разделители или числа написаны с запятыми вместо точек, программа может пропустить их. Еще одна причина — наличие пробелов внутри чисел или скрытых символов. Проверка формата и правильное выделение чисел обычно решают эту проблему.
Как быстро сложить все числа в строке без ручного перебора?
Если в строке есть несколько чисел, их можно сложить с помощью простого алгоритма: сначала нужно пройти по каждому символу, выделяя цифры, формируя из них числа, а затем суммировать эти числа. Например, для строки «12, 7 и 3» алгоритм выделит 12, 7 и 3, после чего получится сумма 22. Такой метод удобен для строк любой длины и не требует сложных операций.