Содержание статьи

Деревья решений являются мощным инструментом для классификации и регрессии, но без визуализации их структура может оставаться непонятной. В Python визуализация дерева позволяет сразу оценить, какие признаки наиболее значимы, какие условия приводят к разветвлениям и как распределяются классы на листьях.
Библиотека scikit-learn предоставляет встроенные методы для построения деревьев и их экспорта в графические форматы. Команда export_graphviz позволяет создать описание дерева в формате DOT, которое можно конвертировать в PNG или PDF с помощью Graphviz. Это дает возможность визуально отследить все ветвления, значения порогов и долю объектов в каждом узле.
Альтернативный подход – использовать plot_tree из sklearn.tree, который строит график прямо в Python без промежуточных файлов. Этот метод особенно полезен при быстрой проверке модели на небольших датасетах, таких как Iris или Breast Cancer, где наглядно видны критерии разделения и глубина дерева.
Кроме того, визуализация упрощает анализ переобучения. Глубокие деревья с большим количеством листьев можно быстро идентифицировать по сложной графической структуре, а чрезмерное количество разветвлений указывает на необходимость ограничения параметров max_depth и min_samples_split. Практическое применение таких графиков ускоряет выбор оптимальной конфигурации модели и повышает интерпретируемость решений.
Установка и подключение необходимых библиотек для графического отображения
На Windows рекомендуется скачивать официальные бинарные сборки Graphviz с сайта https://graphviz.org/download/ и добавлять путь к исполняемым файлам в переменную окружения PATH. Это позволяет Python автоматически находить движок рендеринга dot.
Для macOS удобнее использовать Homebrew: brew install graphviz. Такой подход минимизирует конфликты версий и гарантирует корректную работу всех визуализационных функций библиотеки.
В средах Linux достаточно выполнить sudo apt-get install graphviz для систем на базе Debian/Ubuntu или sudo yum install graphviz для CentOS/Fedora. После установки системного пакета подключение через Python будет прозрачным.
Для интеграции с библиотеками машинного обучения стоит подключить scikit-learn. Она предоставляет функции export_graphviz для экспорта структуры дерева в формат DOT. Установка через pip: pip install scikit-learn, версия должна быть не ниже 0.24, чтобы поддерживались последние улучшения визуализации.
Для интерактивной визуализации можно использовать pydot или pydotplus. Они позволяют конвертировать DOT-файлы в изображения PNG или SVG прямо в Python, без внешнего рендеринга. Команды установки: pip install pydot или pip install pydotplus.
После установки всех компонентов рекомендуется проверить работу библиотек простым примером: экспортировать дерево решений через export_graphviz, затем загрузить через pydot и сгенерировать PNG. Если изображение создаётся без ошибок, значит окружение готово к полноценной визуализации.
Создание простого дерева решений на основе sklearn
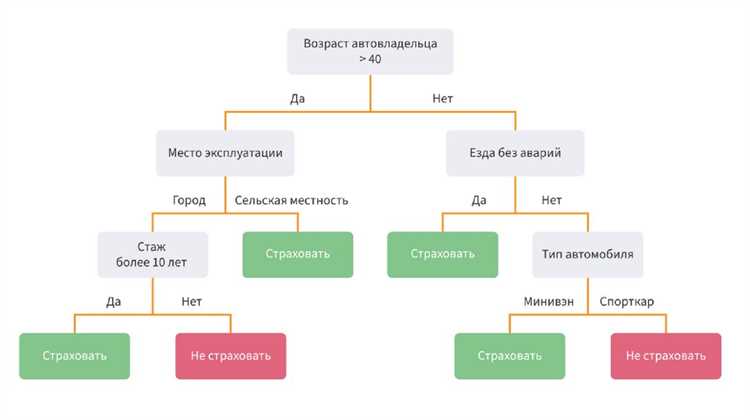
Для начала работы с деревьями решений в Python удобно использовать библиотеку scikit-learn. Основной класс – DecisionTreeClassifier для задач классификации и DecisionTreeRegressor для регрессии. Он позволяет строить модели без необходимости ручного разделения данных на правила.
Первый шаг – подготовка данных. На практике используют train_test_split из sklearn.model_selection для разбиения набора данных на обучающую и тестовую части. Например, набор iris из sklearn.datasets содержит 150 объектов, разделенных по 4 признакам, что делает его удобным для демонстрации.
После загрузки данных создаем экземпляр дерева решений. Рекомендуется явно задавать параметр max_depth, чтобы предотвратить переобучение. Например, clf = DecisionTreeClassifier(max_depth=3, random_state=42) ограничивает глубину дерева тремя уровнями, что облегчает визуализацию и интерпретацию.
Далее модель обучается методом fit, передавая признаки и целевую переменную. В случае iris это X_train и y_train. После обучения дерево готово к предсказаниям и оценке точности на тестовом наборе.
Если нужна графическая визуализация, применяют plot_tree из sklearn.tree. Параметры feature_names и class_names делают диаграмму читаемой, а filled=True окрашивает узлы по преобладающему классу, облегчая восприятие распределения данных.
Для практических проектов важно контролировать переобучение. Помимо max_depth, полезны параметры min_samples_split и min_samples_leaf. Например, min_samples_leaf=5 гарантирует, что листья дерева содержат хотя бы пять объектов, что повышает устойчивость модели.
В завершение, простое дерево решений на sklearn строится за несколько шагов: загрузка данных, разбиение на тренировочную и тестовую выборки, создание экземпляра модели с ограничением глубины, обучение методом fit и визуализация через export_text или plot_tree. Такой подход обеспечивает прозрачность алгоритма и быстрый анализ результатов.
Построение графика дерева с использованием plot_tree

Для визуализации дерева решений в Python удобно использовать функцию plot_tree из библиотеки sklearn.tree. Она позволяет сразу отобразить структуру узлов, условия разбиений и значения целевой переменной. Например, при работе с классификацией ирисов можно передать аргументы feature_names=df.columns[:-1] и class_names=iris.target_names, чтобы на графике были подписаны признаки и классы. Настройка параметров filled=True и rounded=True помогает быстро отличать ветви с разной чистотой узлов и визуально выделять распределение классов. Для больших деревьев рекомендуется дополнительно указать max_depth, чтобы ограничить количество уровней и сохранить читаемость.
Пример организации данных для графика может выглядеть так:
| Параметр plot_tree | Описание |
|---|---|
| feature_names | Список названий признаков |
| class_names | Список классов целевой переменной |
| filled | Закрашивание узлов в зависимости от класса |
| rounded | Закругленные узлы для удобства чтения |
| max_depth | Ограничение глубины визуализируемого дерева |
| proportion | Отображение доли образцов в узлах |
После вызова plot_tree(clf, feature_names=..., class_names=..., filled=True) график можно сохранить через plt.savefig() или показать с помощью plt.show(). Это упрощает анализ важности признаков и контроль структуры модели без обращения к текстовому описанию дерева.
Настройка отображения узлов и ветвей дерева

Для точного контроля визуализации дерева решений в Python библиотека graphviz позволяет изменять форму узлов через параметр node_attr, устанавливая, например, shape=’ellipse’ или shape=’box’ для улучшенной читаемости. Цветовое кодирование можно задать через fillcolor и fontcolor, где листья с конечными классами выделяются lightblue, а промежуточные решения – lightgray. Толщину и стиль ветвей настраивают через edge_attr, указывая penwidth=2 для важных разделений и style=’dashed’ для менее значимых переходов, что помогает визуально отделять ключевые пути классификации.
При работе с деревьями больших размеров рекомендуется использовать max_depth для ограничения отображаемого уровня узлов, одновременно применяя label=’feature: value\\n samples: n’ для информативного отображения каждого разветвления. Оптимальный размер шрифта определяется через fontsize, где 10–12pt подходит для компактных диаграмм, а для презентаций лучше 14–16pt. Комбинация этих настроек гарантирует, что даже глубокие ветви остаются читаемыми и легко интерпретируемыми при анализе данных.
Добавление меток и цветовой схемы для разных классов
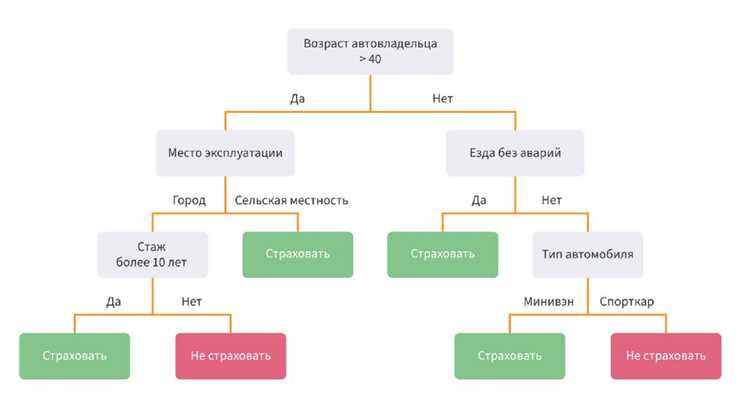
Для четкой идентификации классов в дереве решений в Python важно назначать уникальные цвета каждому классу. В библиотеке matplotlib можно использовать параметр filled=True вместе с аргументом class_names, передавая список имен классов, например ['Setosa', 'Versicolor', 'Virginica']. Это автоматически раскрасит вершины дерева в соответствии с принадлежностью объектов к классам.
При необходимости более точного контроля можно определить собственную цветовую палитру через словарь, где ключ – имя класса, а значение – цвет в формате HEX или RGB. Например:
colors = {'Setosa':'#FF9999', 'Versicolor':'#99FF99', 'Virginica':'#9999FF'}- Использовать функцию
apply_color(node_class), чтобы каждой вершине присваивался соответствующий цвет.
Метки узлов добавляются через аргумент label='all' в plot_tree(), что позволяет отображать и класс, и критерий разбиения, и количество образцов. Для повышения читаемости рекомендуется сочетать метки с цветовой схемой: классы с высокой частотой объектов можно выделять насыщенными оттенками, а редкие – более светлыми.
Для больших деревьев стоит использовать легенду с привязкой цвета к классу. В matplotlib достаточно создать список Patch объектов с соответствующими цветами и именами классов, а затем добавить plt.legend(handles=patches). Такой подход делает визуализацию информативной и позволяет быстро ориентироваться в распределении классов по ветвям.
Экспорт дерева в формат PNG или PDF через export_graphviz
Для визуализации дерева решений в формате PNG или PDF в Python чаще всего используется функция export_graphviz из библиотеки sklearn.tree. Она создает описание дерева в формате DOT, которое затем можно преобразовать в графическое изображение с помощью утилиты Graphviz. Основная команда: export_graphviz(decision_tree, out_file="tree.dot", feature_names=features, class_names=classes, filled=True).
После генерации DOT-файла можно экспортировать дерево в PNG или PDF через Graphviz. Например, для PNG используется команда терминала dot -Tpng tree.dot -o tree.png, а для PDF – dot -Tpdf tree.dot -o tree.pdf. Этот метод сохраняет все визуальные атрибуты, включая раскрашенные узлы по классам и метки признаков.
Чтобы избежать слишком мелких шрифтов на больших деревьях, рекомендуется задавать параметр fontsize в export_graphviz или масштабировать выходной файл через Graphviz с ключом -Gsize=10,10. Для деревьев с большим числом признаков удобнее использовать PDF, так как он сохраняет четкость линий при масштабировании.
Если нужно автоматизировать процесс прямо в Python, можно подключить библиотеку graphviz: import graphviz; graph = graphviz.Source.from_file("tree.dot"); graph.render("tree", format="png"). Такой подход позволяет сразу получать изображение без ручного запуска команд в терминале и интегрируется в скрипты анализа данных.
Для улучшения читаемости дерева полезно включать параметры filled=True, rounded=True и special_characters=True в export_graphviz. Это делает узлы цветными, закругленными и поддерживает корректное отображение символов в названиях признаков, что особенно важно при работе с неанглоязычными данными.
Визуализация сложных деревьев с graphviz
Для деревьев решений с глубиной более 5 уровней стандартные инструменты matplotlib становятся неэффективными из-за наложения узлов и ветвей. Graphviz позволяет генерировать графы в формате DOT, обеспечивая компактное расположение узлов и удобное управление стилями. Рекомендуется использовать функции export_graphviz из библиотеки scikit-learn с параметрами filled=True и rounded=True, чтобы автоматически раскрашивать классы и сглаживать углы узлов, улучшая читаемость сложных деревьев.
При построении больших деревьев полезно:
- Устанавливать
max_depthпри генерации визуализации, чтобы временно скрыть нижние уровни. - Использовать
graph_attrсrankdir="TB"для вертикальной ориентации илиrankdir="LR"для горизонтальной, что уменьшает пересечения ветвей. - Сохранять граф в формате PDF или SVG вместо PNG – это обеспечивает масштабируемость без потери качества при детальном рассмотрении сотен узлов.
- Добавлять подписи
node_ids=Trueиfeature_names, чтобы отслеживать конкретные признаки, влияющие на решения модели.
Эти подходы позволяют анализировать сложные структуры, выявлять глубоко вложенные закономерности и создавать наглядные отчёты для презентаций или публикаций.
Интерактивная визуализация с помощью dtreeviz
Библиотека dtreeviz позволяет создавать наглядные и интерактивные деревья решений с визуализацией распределений классов в каждом узле. В отличие от статических графиков, она отображает плотность признаков и вероятность исходов, что облегчает анализ модели на уровне конкретных решений.
Для работы требуется модель, обученная на scikit-learn, а также набор данных. Dtreeviz поддерживает классификацию и регрессию, автоматически строя цветовую кодировку узлов и показывая гистограммы распределений признаков. Например, для датасета Iris можно визуально увидеть, как признаки Sepal Length и Petal Width влияют на разделение видов.
Создание интерактивного дерева происходит через функцию dtreeviz(model, X, y, target_name, feature_names, class_names). Она возвращает объект SVG, который можно масштабировать, просматривать подробные значения узлов и исследовать вероятности каждого класса. Особенность dtreeviz в том, что при наведении курсора на узел отображается детальная информация о разделении и ошибках классификации.
Рекомендуется перед визуализацией нормализовать признаки и убрать категориальные данные с большим количеством уникальных значений, чтобы график оставался читаемым. Для больших деревьев полезно использовать параметр max_depth при обучении модели, иначе интерактивная визуализация будет перегружена узлами и потеряет информативность.
Для сохранения интерактивной версии можно экспортировать дерево в SVG-файл или встроить его в Jupyter Notebook с помощью display(). Dtreeviz также поддерживает цветовую адаптацию для различных схем визуализации, что позволяет сравнивать несколько моделей на одном наборе данных, фиксируя различия в структуре разделений и распределении вероятностей. Этот подход значительно ускоряет интерпретацию сложных деревьев решений.
Вопрос-ответ:
Как построить дерево решений на Python с использованием библиотеки scikit-learn?
Для построения дерева решений сначала необходимо импортировать нужные классы из scikit-learn: DecisionTreeClassifier или DecisionTreeRegressor в зависимости от задачи. Затем данные разделяются на признаки (X) и целевую переменную (y). После этого создается объект дерева с настройками, такими как критерий разбиения и максимальная глубина. Модель обучается методом fit на тренировочных данных, после чего можно делать прогнозы методом predict.
Какие способы визуализации дерева решений доступны в Python?
В Python есть несколько подходов к отображению дерева решений. Один из них — функция plot_tree из sklearn.tree, которая строит графическое представление узлов, ветвей и условий разбиения. Еще один вариант — экспорт в формат DOT с помощью export_graphviz и последующая визуализация через Graphviz. Также можно использовать библиотеки, такие как matplotlib или pydotplus, чтобы получать более детализированные и стилизованные схемы дерева.
Как можно подписать узлы дерева, чтобы было понятно, по каким критериям происходит разветвление?
При визуализации через plot_tree можно задать параметры label, feature_names и class_names. feature_names позволяет отображать названия признаков в узлах, class_names — классы целевой переменной. Также есть параметры filled и rounded, которые помогают лучше различать узлы с разными классами и делают визуализацию более читаемой. Такой подход облегчает анализ того, какие признаки наиболее влияют на прогноз.
Как контролировать глубину дерева и что это даёт?
Глубину дерева можно ограничить через параметр max_depth при создании объекта DecisionTreeClassifier или DecisionTreeRegressor. Ограничение глубины помогает избежать переобучения, когда модель слишком точно подстраивается под тренировочные данные, и делает дерево более интерпретируемым. Чем меньше глубина, тем проще структура и легче понять, какие признаки важны для принятия решений.
Можно ли визуализировать дерево для регрессии, а не классификации?
Да, визуализация дерева регрессии возможна. Методы plot_tree и export_graphviz работают как для классификаторов, так и для регрессоров. Разница заключается в том, что в узлах отображается предсказанное численное значение, а не класс. Это позволяет видеть, как дерево делит пространство признаков и к каким средним значениям приводит разбиение на каждом уровне.