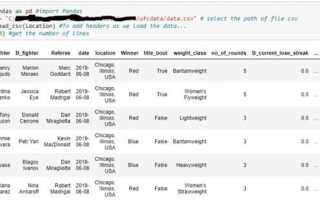
CSV (Comma-Separated Values) – один из самых распространённых форматов для хранения табличных данных. В Jupyter Notebook его открытие осуществляется с помощью библиотеки pandas, которая позволяет не только импортировать данные, но и сразу проводить анализ и преобразования.
Перед загрузкой файла важно убедиться, что установлены все необходимые пакеты: pandas и numpy. Их можно установить через команду pip install pandas numpy, что обеспечит корректное чтение данных и работу с числовыми и текстовыми столбцами.
При открытии CSV файла следует обращать внимание на кодировку и разделители. Стандартная кодировка UTF-8 подходит для большинства файлов, а разделитель чаще всего – запятая. Если данные используют другой символ, например точку с запятой, это нужно указать в параметре sep при чтении файла.
После загрузки данных полезно сразу проверить структуру таблицы: количество строк и столбцов, наличие пустых значений, типы данных. Это позволит выявить ошибки на раннем этапе и подготовить данные для анализа без потери информации.
Данное руководство покажет, как шаг за шагом открыть CSV файл в Jupyter Notebook, провести базовую проверку данных и подготовить их для дальнейшей обработки, используя минимальные настройки и стандартные функции pandas.
Открытие CSV файла в Jupyter Notebook пошаговое руководство
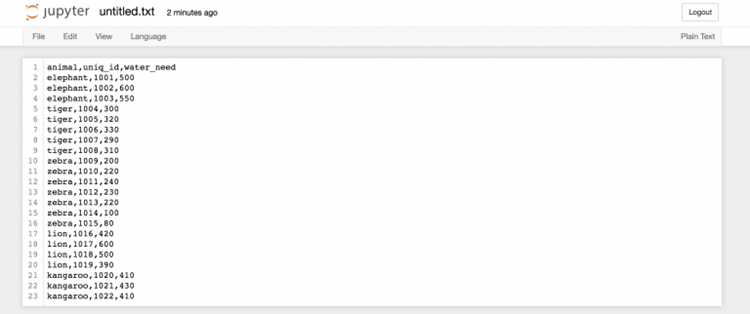
Для начала необходимо убедиться, что библиотека pandas установлена в вашей среде. В командной строке Jupyter Notebook выполните !pip install pandas для её установки. После этого импортируйте библиотеку командой import pandas as pd.
Выберите CSV файл и определите путь к нему. Для локальных файлов используйте относительный путь, например ‘data/sample.csv’. Если файл находится в другой директории, укажите полный путь: ‘C:/Users/ИмяПользователя/Documents/sample.csv’.
Откройте CSV файл с помощью функции pd.read_csv(). Для стандартного файла с запятыми в качестве разделителя достаточно: data = pd.read_csv(‘data/sample.csv’). Если используется другой разделитель, например точка с запятой, добавьте параметр: data = pd.read_csv(‘data/sample.csv’, sep=’;’).
Для корректного отображения символов проверьте кодировку файла. Если данные содержат кириллицу, используйте параметр encoding=’utf-8′ или encoding=’cp1251′ в зависимости от источника: data = pd.read_csv(‘data/sample.csv’, encoding=’utf-8′).
После загрузки данных проверьте структуру таблицы: количество строк и столбцов можно узнать через data.shape, а первые пять записей – через data.head(). Это позволит убедиться в правильности загрузки и выявить потенциальные проблемы с пропущенными значениями или типами данных.
При необходимости сохраните очищенный или изменённый CSV файл командой data.to_csv(‘data/processed.csv’, index=False), чтобы использовать его в дальнейшем без повторной загрузки и корректировки.
Установка Jupyter Notebook и подготовка среды
Для работы с CSV файлами в Jupyter Notebook рекомендуется использовать дистрибутив Anaconda, который содержит Python, Jupyter и основные библиотеки для анализа данных. Установите Anaconda с официального сайта, выбрав версию для вашей операционной системы.
После установки откройте Anaconda Navigator или выполните команду jupyter notebook в терминале для запуска сервера. Браузер откроет главную страницу Jupyter, где можно создавать новые ноутбуки с ядром Python.
Для работы с CSV файлами необходимы библиотеки pandas и numpy. Установите их командой в терминале:
pip install pandas numpy
Проверьте установку, импортировав библиотеки в новом ноутбуке:
import pandas as pd
import numpy as np
Рекомендуется создать отдельную рабочую папку для проекта и поместить туда CSV файлы. Это упростит указание путей при загрузке и снижает риск ошибок.
Пример организации файлов:
| Папка | Описание |
|---|---|
| notebooks | Jupyter Notebook для работы с данными |
| data | CSV файлы и другие источники данных |
| output | Результаты анализа и обработанные файлы |
Такое структурирование среды облегчает навигацию, позволяет быстро открывать файлы и сохранять результаты анализа без смешивания данных и ноутбуков.
Импорт необходимых библиотек для работы с CSV
Для эффективной работы с CSV файлами в Jupyter Notebook используются следующие библиотеки:
- pandas – основной инструмент для чтения, анализа и преобразования табличных данных.
- numpy – обеспечивает работу с числовыми массивами и позволяет выполнять быстрые математические операции.
- os – помогает управлять путями к файлам и папкам, проверять их существование.
Импорт библиотек выполняется в начале ноутбука следующими командами:
- import pandas as pd – для работы с DataFrame и чтения CSV файлов.
- import numpy as np – для работы с числовыми данными и массивами.
- import os – для проверки и указания корректного пути к файлу.
Для загрузки CSV файлов с нестандартной кодировкой или разделителем достаточно использовать дополнительные параметры функции pd.read_csv():
- encoding=’utf-8′ или encoding=’cp1251′ – выбор кодировки.
- sep=’,’ или sep=’;’ – указание разделителя столбцов.
При импорте библиотек рекомендуется сразу проверять их версии для совместимости с текущей версией Python и pandas:
- pd.__version__ – версия pandas
- np.__version__ – версия numpy
Это обеспечивает корректную работу функций и предотвращает ошибки при чтении или обработке CSV файлов.
Выбор и загрузка CSV файла в проект

Для корректной работы с CSV файлами важно сначала определить их расположение и структуру. Рекомендуется хранить все файлы данных в отдельной папке проекта, например data/, чтобы избежать ошибок с путями и обеспечить удобную навигацию.
Перед загрузкой файла проверьте его размер и количество строк. Для больших CSV файлов (>100 МБ) стоит использовать параметр chunksize в функции pd.read_csv() для поэтапной загрузки данных, что снижает нагрузку на оперативную память.
Загрузка файла выполняется с помощью команды:
data = pd.read_csv(‘data/имя_файла.csv’)
Если CSV файл использует нестандартный разделитель или содержит специфическую кодировку, необходимо указать соответствующие параметры:
data = pd.read_csv(‘data/имя_файла.csv’, sep=’;’, encoding=’cp1251′)
Для проверки правильности загрузки сразу после чтения файла используйте команды:
data.head() – просмотр первых 5 строк
data.tail() – просмотр последних 5 строк
При работе с несколькими CSV файлами в проекте рекомендуется использовать цикл или словарь для последовательной загрузки всех файлов, что упрощает дальнейший анализ и объединение данных.
Чтение CSV файла с помощью pandas
Функция pd.read_csv() библиотеки pandas позволяет загружать CSV файлы в DataFrame для дальнейшего анализа. Минимальный синтаксис: data = pd.read_csv(‘data/файл.csv’), где data – объект DataFrame.
Если CSV файл содержит заголовки в первой строке, pandas автоматически использует их как имена столбцов. Для файлов без заголовков укажите параметр header=None и при необходимости задайте свои имена столбцов через names=[‘col1’, ‘col2’, …].
Для файлов с большим количеством строк рекомендуется использовать параметр nrows, чтобы загрузить только первые строки для предварительной проверки: data_preview = pd.read_csv(‘data/файл.csv’, nrows=100).
Если данные содержат пустые значения, pandas автоматически заменяет их на NaN. Для специфического обозначения пропусков можно использовать параметр na_values=[‘NULL’, ‘–’].
Функция pd.read_csv() также поддерживает настройку разделителя через sep, кодировки через encoding и пропуск строк с комментариями через comment=’#’, что позволяет корректно обрабатывать разнообразные CSV форматы без предварительной подготовки файла.
Просмотр первых и последних строк данных

После загрузки CSV файла важно сразу проверить корректность данных. Для этого используются методы head() и tail() объекта DataFrame.
Примеры использования:
- data.head() – просмотр первых пяти строк.
- data.head(10) – просмотр первых десяти строк для более детального анализа.
- data.tail() – просмотр последних пяти строк.
- data.tail(15) – проверка последних пятнадцати строк большого файла.
Регулярная проверка начала и конца таблицы позволяет выявить ошибки форматирования, лишние строки или пустые значения до начала полноценного анализа.
Проверка структуры и типов данных в CSV
После загрузки CSV файла важно убедиться, что данные имеют корректную структуру и подходящие типы для анализа. Для этого используются методы DataFrame библиотеки pandas.
Основные инструменты проверки:
- data.info() – отображает количество строк и столбцов, количество непустых значений в каждом столбце и тип данных.
- data.shape – возвращает кортеж с числом строк и столбцов ((rows, columns)), что помогает оценить масштаб данных.
- data.dtypes – показывает тип данных каждого столбца (int64, float64, object и др.).
- data.describe() – предоставляет сводную статистику для числовых столбцов: минимум, максимум, среднее, стандартное отклонение, квартильные значения.
Если столбцы имеют неправильный тип данных, их можно преобразовать с помощью метода astype():
data[‘column_name’] = data[‘column_name’].astype(‘float64’)
Регулярная проверка структуры и типов данных позволяет выявить ошибки на этапе загрузки и подготовить CSV файл для корректного анализа, фильтрации и визуализации.
Сохранение изменений и экспорт обработанного файла

После анализа и обработки CSV файла в Jupyter Notebook результаты можно сохранить для дальнейшей работы или передачи другим пользователям. Для этого используется метод to_csv() объекта DataFrame.
Простейший способ сохранения:
data.to_csv(‘data/обработанный_файл.csv’, index=False)
Параметр index=False предотвращает запись индекса DataFrame в CSV, что делает файл чистым для последующего использования.
Если необходимо сохранить данные с определённой кодировкой, используйте параметр encoding:
data.to_csv(‘data/обработанный_файл.csv’, index=False, encoding=’utf-8′)
Для больших файлов рекомендуется разбивать данные на части с помощью параметра chunksize:
for i, chunk in enumerate(np.array_split(data, 5)):
chunk.to_csv(f’data/часть_{i}.csv’, index=False)
Сохранение обработанных файлов в отдельной папке, например output/, упрощает управление проектом и предотвращает случайное перезаписывание исходных CSV.
Вопрос-ответ:
Как правильно указать путь к CSV файлу в Jupyter Notebook?
Для загрузки CSV файла важно использовать корректный путь. Если файл находится в той же папке, что и ноутбук, достаточно указать его имя: ‘файл.csv’. Для файлов в другой директории используйте относительный путь, например ‘data/файл.csv’, или полный путь ‘C:/Users/Имя/Документы/файл.csv’. Проверка существования файла через os.path.exists(‘путь_к_файлу’) помогает избежать ошибок при загрузке.
Как открыть CSV файл с нестандартным разделителем?
Если CSV файл использует не запятую, а, например, точку с запятой или табуляцию, необходимо указать параметр sep при чтении: data = pd.read_csv(‘файл.csv’, sep=’;’). Для табуляции используют sep=’\t’. Это обеспечивает корректное разделение столбцов и предотвращает слияние данных в одну колонку.
Что делать, если в CSV файле есть пустые значения или специфические обозначения пропусков?
Пустые значения автоматически распознаются как NaN. Если пропуски обозначены другими символами, например ‘NULL’ или ‘—’, их можно указать через параметр na_values: data = pd.read_csv(‘файл.csv’, na_values=[‘NULL’,’—’]). Это позволит корректно обрабатывать данные без ошибок в вычислениях.
Как проверить типы данных и структуру загруженного CSV файла?
Используйте data.info() для отображения количества строк, столбцов, непустых значений и типов данных. Метод data.dtypes покажет точный тип каждого столбца. Для числовых данных полезна функция data.describe(), которая предоставляет минимальные, максимальные, средние значения и квартильные показатели.
Как сохранить обработанный CSV файл без индексов и с нужной кодировкой?
После анализа или изменения данных используйте метод to_csv() для сохранения: data.to_csv(‘output/обработанный.csv’, index=False, encoding=’utf-8′). Параметр index=False исключает индекс DataFrame из файла, а encoding обеспечивает корректное отображение символов, например кириллицы, при открытии в других программах.