PDF-файлы часто используют для передачи инструкций, договоров, отчётов и учебных материалов, где текст уже зафиксирован и не предназначен для редактирования. При попытке скопировать фрагмент пользователь может столкнуться с разрывами строк, невозможностью выделения или полным отсутствием текста, если документ создан из скана.
Перед вырезанием текста важно определить, какой тип PDF открыт: текстовый или графический. В первом случае данные хранятся в виде символов и доступны для выделения стандартными средствами. Во втором – каждая страница представляет собой изображение, и без распознавания символов текст получить не получится. Проверка занимает несколько секунд: достаточно попробовать выделить одно слово курсором.
Отдельную сложность представляют файлы с ограничениями на копирование. Такие PDF могут открываться без пароля, но блокировать буфер обмена. В подобных ситуациях помогают как настольные программы, так и браузерные инструменты, которые извлекают текст напрямую из структуры документа, игнорируя пользовательские ограничения.
После копирования часто возникает задача привести текст в рабочий вид: убрать лишние переносы, восстановить абзацы, сохранить таблицы или списки. Эти проблемы решаются настройками вставки, специализированными редакторами или промежуточным сохранением данных в текстовые форматы. Ниже разобраны способы вырезания текста из PDF для разных сценариев – от простого копирования до работы со сканами.
Определение типа PDF файла перед извлечением текста
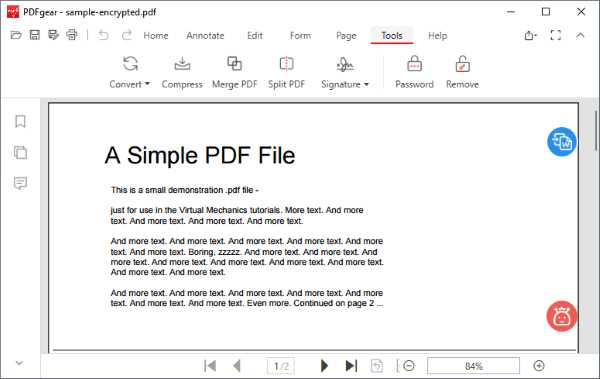
Перед вырезанием текста необходимо понять, как именно хранится содержимое внутри PDF. Существует два основных варианта: PDF с текстовым слоем и PDF, состоящий из изображений. От этого напрямую зависит выбор инструментов и порядок действий.
Самый простой способ проверки – попытаться выделить отдельное слово курсором мыши. Если символы выделяются посимвольно, копируются в буфер обмена и корректно вставляются в текстовый редактор, документ содержит текстовый слой. Такой PDF создаётся из Word, Excel, LaTeX или экспортируется из браузера.
Если при выделении захватывается вся строка, прямоугольная область или ничего не происходит, файл, скорее всего, является сканом. В подобных документах каждая страница – это растровое изображение, а видимый текст не существует как набор символов. Копирование в этом случае невозможно без распознавания.
Дополнительную информацию можно получить через свойства файла. В Adobe Acrobat или большинстве PDF-просмотрщиков достаточно открыть сведения о документе и проверить пункт Fonts или Шрифты. Наличие списка встроенных шрифтов указывает на текстовый PDF. Их отсутствие обычно означает скан.
Отдельно стоит учитывать PDF с ограничениями. Если текст выделяется, но не копируется, или вставляется в виде пустых строк, в файле активны запреты на извлечение. Это проверяется в разделе прав доступа, где указывается разрешение на копирование содержимого.
Точная идентификация типа PDF позволяет сразу выбрать нужный подход: стандартное копирование, обход ограничений или использование OCR. Пропуск этого шага часто приводит к потере времени и некорректному результату.
Выделение и копирование текста из PDF стандартными средствами
Для PDF с текстовым слоем не требуется установка дополнительных программ. Большинство задач решается средствами операционной системы, браузера или стандартного просмотрщика. Главное условие – отсутствие запрета на копирование и корректная структура документа.
В настольных PDF-просмотрщиках выделение выполняется инструментом выбора текста. После активации курсор принимает вид I-образной линии, что указывает на доступ к символам. Выделенный фрагмент копируется сочетанием клавиш или через контекстное меню.
- Выделение одного слова – двойной щелчок мышью.
- Выделение строки – тройной щелчок или протягивание курсора.
- Выделение абзаца – протягивание от начала до конца с зажатой кнопкой.
При работе с PDF в браузере алгоритм аналогичен. Chrome, Edge и Firefox корректно извлекают текст при открытии файла во вкладке. Если копирование даёт лишние переносы строк, рекомендуется вставлять текст сначала в простой редактор без форматирования, а затем переносить в рабочий документ.
Для сохранения порядка чтения полезно учитывать направление выделения. При сложной вёрстке с колонками текст следует копировать по блокам, двигаясь сверху вниз и слева направо. Это снижает риск перемешивания строк.
- Увеличить масштаб страницы до 125–150% для точного выделения.
- Копировать небольшие фрагменты вместо всей страницы.
- Проверять результат вставки сразу после копирования.
Если при копировании символы заменяются на пустые квадраты или знаки вопроса, документ использует нестандартные шрифты. В таком случае помогает вставка через буфер обмена без форматирования или экспорт текста в TXT через меню просмотра.
Вырезание текста из защищённого PDF без пароля
Некоторые PDF открываются без запроса пароля, но блокируют копирование текста. В таких файлах ограничения задаются на уровне прав доступа, а сами данные остаются в документе в виде обычного текстового слоя. Это означает, что текст можно получить без подбора пароля, используя альтернативные способы чтения содержимого.
Первый признак такого ограничения – текст визуально выделяется, но при копировании вставляется пустым или с искажениями. Проверка прав доступа выполняется через свойства документа: если указано «Копирование запрещено», файл защищён логически, а не криптографически.
Один из рабочих подходов – открытие PDF в браузере вместо настольного просмотрщика. В ряде случаев браузеры игнорируют флаг запрета копирования и позволяют перенести текст через стандартный буфер обмена. Результат зависит от того, как именно были заданы ограничения.
Другой вариант – экспорт текста через функции сохранения. Некоторые программы позволяют сохранить содержимое в формате TXT или DOCX, даже если прямое копирование недоступно. При этом извлекается исходный текст без участия пользователя в процессе выделения.
Важно учитывать правовую сторону вопроса. Ограничения на копирование могут быть установлены владельцем документа осознанно. Использование описанных способов допустимо только для файлов, на которые у пользователя есть законные права, например служебных материалов или личных архивов.
Извлечение текста из PDF с помощью онлайн-сервисов
Онлайн-сервисы подходят для разовых задач, когда нет доступа к настольным программам или требуется быстро получить текст без установки ПО. Работа строится по схеме загрузки файла на сайт, обработки на сервере и скачивания результата в виде TXT, DOCX или копируемого текста.
Наиболее предсказуемый результат дают сервисы, которые анализируют структуру PDF, а не выполняют простое визуальное копирование. При загрузке текстового PDF такие инструменты извлекают символы напрямую из документа, сохраняя порядок строк и абзацев. Для файлов со сканами автоматически подключается распознавание.
Перед использованием стоит проверить ограничения: бесплатные версии часто накладывают лимиты на размер файла, количество страниц или число обработок в день. Типичные ограничения – 5–10 МБ на файл и до 50 страниц за одну операцию.
Для документов с конфиденциальными данными важно учитывать способ обработки. Часть сервисов удаляет загруженные файлы через фиксированный интервал, другие хранят их дольше. Эта информация указывается в правилах использования и влияет на выбор инструмента.
После извлечения текст следует проверить на ошибки разметки. Онлайн-сервисы нередко добавляют лишние переносы строк, особенно в многостраничных отчётах и файлах с колонками. Исправление проще выполнять в простом текстовом редакторе до дальнейшего форматирования.
Онлайн-извлечение удобно как временное решение, но для регулярной работы с PDF большого объёма более надёжным остаётся локальный софт, который даёт больший контроль над результатом и данными.
Использование Adobe Acrobat для точного вырезания текста
Adobe Acrobat предоставляет инструменты для точного извлечения текста из PDF любого типа, включая защищённые файлы и документы со сложной вёрсткой. Программное обеспечение работает с текстовым слоем напрямую и поддерживает экспорт в разные форматы, минимизируя ошибки форматирования.
Для копирования текста используется инструмент Выбор текста. При выделении можно ориентироваться на отдельные блоки, абзацы или колонки. Если документ содержит таблицы, Acrobat позволяет выделять их как единый объект и экспортировать в Excel или CSV.
Для документов со сканированными страницами применяется функция Распознавание текста (OCR). Она создаёт текстовый слой поверх изображения, после чего стандартное выделение и копирование становится доступным.
Пример структуры работы с таблицами в Adobe Acrobat:
| Действие | Описание |
|---|---|
| Выделение блока | Курсор выбирает весь фрагмент текста или таблицу целиком для последующей вставки |
| Экспорт таблицы | Сохранение в Excel или CSV для сохранения структуры строк и столбцов |
| Применение OCR | Распознавание текста на отсканированных страницах с созданием отдельного текстового слоя |
| Проверка форматирования | Исправление переносов строк и пробелов перед вставкой в рабочий документ |
Adobe Acrobat также позволяет пакетно извлекать текст из нескольких PDF, объединять результат и экспортировать в один файл. Это особенно полезно при работе с отчётами и большим объёмом документов.
Копирование текста из PDF через сторонние программы
Сторонние программы расширяют возможности извлечения текста из PDF, особенно если стандартные средства не справляются с защитой, сложной вёрсткой или сканированными страницами. Они позволяют работать как с одиночными файлами, так и пакетно с большим объёмом документов.
Популярные типы программ:
- PDF-редакторы – позволяют выделять текст, экспортировать его в TXT, DOCX, RTF, сохранять таблицы и списки.
- OCR-программы – распознают текст на отсканированных страницах, создавая текстовый слой поверх изображения.
- Утилиты для обхода защиты – снимают ограничения на копирование, при этом исходный текст остаётся неизменным.
Рекомендации по использованию сторонних программ:
- Выбирать программу с поддержкой форматов, которые нужны для дальнейшей работы (TXT, DOCX, Excel).
- Перед обработкой проверять, можно ли выделить текст стандартными средствами, чтобы не тратить ресурсы на OCR без необходимости.
- При пакетной обработке файлов задавать последовательность страниц и сохранять структуру документа.
- Проверять извлечённый текст на ошибки, особенно после OCR, и исправлять переносы строк и пробелы.
- Для конфиденциальных документов использовать локальные утилиты, избегая загрузки в облачные сервисы.
Сторонние программы сокращают время на извлечение текста и повышают точность при работе с нестандартными PDF, обеспечивая полный контроль над процессом и результатом.
Извлечение текста из отсканированного PDF с распознаванием
Отсканированные PDF содержат страницы в виде изображений, поэтому стандартное выделение текста недоступно. Для работы с такими документами требуется распознавание символов (OCR), которое создаёт текстовый слой поверх изображения, позволяя копировать и редактировать содержимое.
Выбор инструмента зависит от качества сканов и объёма текста. Для одиночных страниц подойдут встроенные функции PDF-редакторов с поддержкой OCR, таких как Adobe Acrobat. Для больших архивов удобнее использовать специализированные программы или пакеты командной строки, поддерживающие пакетную обработку.
Рекомендации по распознаванию:
- Перед запуском OCR убедитесь, что скан имеет достаточное разрешение – оптимально 300 dpi или выше.
- Используйте языковые пакеты для корректного распознавания специфических символов и пунктуации.
- Для таблиц и форм выбирайте режимы, сохраняющие структуру строк и столбцов.
- После распознавания проверяйте текст на ошибки, особенно если скан содержит размытые участки или рукописные вставки.
- Сохраняйте промежуточный результат в текстовом формате, чтобы при необходимости быстро исправить ошибки.
При правильной настройке OCR процесс извлечения текста становится быстрым и точным, позволяя работать с отсканированными документами так же удобно, как с обычными PDF с текстовым слоем.
Исправление ошибок форматирования после копирования текста
После копирования текста из PDF часто возникают лишние переносы строк, неправильные пробелы и нарушение структуры абзацев. Эти проблемы особенно заметны при извлечении из документов с колонками, таблицами или сложной версткой.
Для приведения текста в рабочий вид применяются несколько методов:
- Использование функций «Найти и заменить» для удаления лишних переносов строк и двойных пробелов.
- Склеивание разбитых абзацев с сохранением смысловых блоков через редакторы текста или специальные утилиты для обработки текста.
- Проверка списков и нумерации: часто нумерованные пункты при копировании теряют формат, поэтому их восстанавливают вручную или с помощью правил форматирования.
- Для таблиц рекомендуется экспортировать их в Excel или CSV, чтобы сохранить структуру строк и столбцов и избежать слияния ячеек.
- Использование редакторов с функцией очистки форматирования: позволяет удалить скрытые символы и сохранить только текст.
После корректировки важно проверить текст на пропуски и искажения, особенно если PDF содержал специальные символы или нестандартные шрифты. Правильная обработка экономит время при дальнейшем редактировании и подготовке документов к публикации или печати.
Вопрос-ответ:
Можно ли вырезать текст из PDF, если он защищён от копирования?
Да, но стандартное выделение может не сработать. Для таких файлов используют обход ограничений через сторонние программы, функции экспорта в PDF-редакторах или печать в новый PDF. Если документ содержит текстовый слой, эти методы позволяют извлечь текст без изменения исходного содержимого. Для документов с активной защитой всегда учитывайте правовую сторону вопроса.
Как узнать, является ли PDF текстовым или сканированным?
Для проверки попробуйте выделить курсором одно слово. Если символы можно копировать напрямую, PDF текстовый. Если выделяется только область или ничего не копируется, файл представляет собой скан. Дополнительно информацию можно посмотреть в свойствах документа: наличие встроенных шрифтов указывает на текстовый PDF, их отсутствие — на изображение.
Какие онлайн-сервисы лучше использовать для извлечения текста из PDF?
Для текстовых PDF подходят сервисы, которые напрямую извлекают символы, сохраняя структуру строк и абзацев. Для сканов выбирайте инструменты с функцией OCR. Важно учитывать размер файла, ограничения на количество страниц и условия хранения загруженных данных. После обработки текст следует проверять на корректность форматирования.
Почему после копирования текста из PDF появляются лишние переносы и пробелы?
Это связано с особенностями верстки и структурой документа. PDF фиксирует позиции символов, а не формат абзацев. При вставке в текстовый редактор появляются разрывы строк там, где они визуально разделяют текст. Решение — использование функций «Найти и заменить», склеивание абзацев и проверка списков или таблиц, чтобы восстановить читаемость.
Как правильно извлечь текст из отсканированного PDF с таблицами?
Для таких файлов требуется OCR. Рекомендуется выбрать программу или сервис, который распознаёт текст и сохраняет структуру таблиц. Перед обработкой убедитесь, что скан имеет достаточное разрешение (300 dpi и выше), а язык распознавания соответствует содержимому. После распознавания проверьте строки и столбцы на корректность и при необходимости исправьте ошибки вручную или через Excel.