GPU позволяет выполнять тысячи операций параллельно, что делает его незаменимым при обучении нейросетей, обработке больших массивов данных и моделировании. В Jupyter Notebook графический процессор можно подключить напрямую, используя библиотеки, поддерживающие вычисления на CUDA, такие как TensorFlow, PyTorch или CuPy.
Jupyter Notebook позволяет гибко управлять вычислительными ресурсами, поэтому можно легко переключать код между CPU и GPU. Например, в PyTorch достаточно указать device="cuda", чтобы перенести вычисления на графический процессор. Такой подход значительно ускоряет операции линейной алгебры, обучение моделей и работу с изображениями.
Использование GPU требует внимательного контроля потребления памяти и правильной версии драйверов. Несовместимость компонентов или нехватка видеопамяти часто приводит к ошибкам выполнения, которые можно устранить настройкой окружения и ограничением размера пакетов данных. Соблюдение этих правил позволяет получить стабильный прирост скорости без потери точности вычислений.
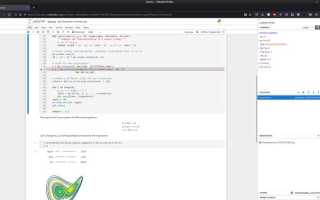
Проверка доступности GPU в среде Jupyter Notebook
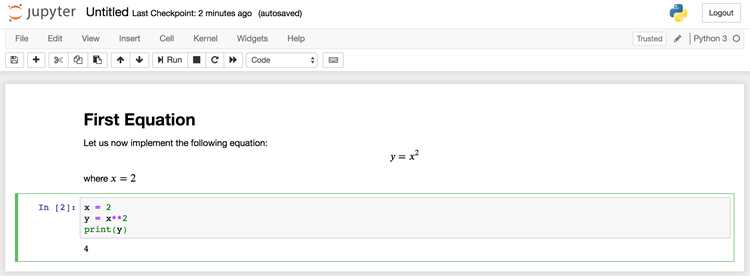
Перед началом работы с графическим процессором необходимо убедиться, что система его распознает. В Jupyter Notebook это можно сделать несколькими способами с помощью встроенных инструментов и библиотек Python.
Базовая проверка выполняется через системную утилиту NVIDIA:
!nvidia-smiДля проверки через Python можно использовать модуль torch или tensorflow:
import torch; torch.cuda.is_available()– возвращает True, если PyTorch видит GPU.
При успешном определении устройства стоит проверить его характеристики:
torch.cuda.get_device_name(0)– название используемого GPU.torch.cuda.get_device_properties(0)– сведения о частоте, количестве ядер и объёме памяти.
Если GPU не определяется, следует убедиться, что установлены совместимые версии CUDA Toolkit и драйверов NVIDIA. Проверить версии можно командами:
!nvcc --version– версия CUDA.!nvidia-smi– версия драйвера.
Совпадение версий CUDA и драйвера с требованиями используемой библиотеки гарантирует корректное использование GPU в Jupyter Notebook и предотвращает ошибки при запуске вычислительных задач.
Установка и настройка драйверов NVIDIA и CUDA Toolkit
Корректная работа GPU в Jupyter Notebook зависит от установленного драйвера NVIDIA и подходящей версии CUDA Toolkit. Сначала необходимо определить модель видеокарты командой !nvidia-smi и сверить поддерживаемые версии драйвера и CUDA на сайте developer.nvidia.com/cuda-gpus.
На системах Linux установка выполняется через репозиторий NVIDIA:
sudo apt update
sudo apt install nvidia-driver-535
sudo rebootПосле перезагрузки доступность GPU проверяется командой nvidia-smi. Отображение информации о видеокарте и версии драйвера означает, что установка прошла успешно.
Далее требуется установка CUDA Toolkit. Для Ubuntu пример последовательности действий:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-repo-ubuntu2204_12.4.0-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2204_12.4.0-1_amd64.deb
sudo apt update
sudo apt install cudaПосле установки необходимо добавить CUDA в системные переменные окружения:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATHПроверка корректности установки выполняется командой nvcc --version. При совпадении версии с ожидаемой можно переходить к настройке библиотек TensorFlow или PyTorch, поддерживающих вычисления на GPU. Несоответствие версий CUDA и драйвера вызывает ошибки при инициализации устройства и требует переустановки компонентов.
Подключение GPU через библиотеку CuPy
Библиотека CuPy предоставляет интерфейс, совместимый с NumPy, но выполняет все операции на GPU через CUDA. Это позволяет ускорять вычисления без переписывания кода, если в проекте уже используется NumPy. Установка выполняется через pip:
pip install cupy-cuda12xВерсию CUDA в названии пакета необходимо выбирать в соответствии с установленной на системе (например, cupy-cuda11x для CUDA 11). Проверка корректности установки выполняется в Jupyter Notebook:
import cupy as cp
cp.show_config()
cp.arange(5)
import numpy as np, cupy as cp, time
a_cpu = np.random.rand(107)
start = time.time()
np.sqrt(a_cpu)
print("CPU:", time.time() - start)
a_gpu = cp.random.rand(107)
cp.cuda.Stream.null.synchronize()
start = time.time()
cp.sqrt(a_gpu)
cp.cuda.Stream.null.synchronize()
print("GPU:", time.time() - start)
При корректной настройке вычисления на GPU занимают в несколько раз меньше времени. Если при импорте CuPy возникает ошибка CUDARuntimeError, необходимо проверить соответствие версий драйвера, CUDA Toolkit и установленного пакета CuPy.
Для работы с несколькими устройствами можно указать активный GPU через контекст:
with cp.cuda.Device(0):
x = cp.ones((1000, 1000))CuPy также поддерживает управление памятью, профилирование и интерфейс с библиотеками cuBLAS и cuDNN, что делает её удобным инструментом для ускорения численных вычислений в Jupyter Notebook без перехода на сложные фреймворки.
Использование TensorFlow с поддержкой GPU

TensorFlow автоматически использует GPU, если система поддерживает CUDA и установлены необходимые компоненты. Проверить наличие GPU можно командой:
import tensorflow as tf
print(tf.config.list_physical_devices('GPU'))| Версия TensorFlow | Версия CUDA | Версия cuDNN |
|---|---|---|
| 2.10 | 11.2 | 8.1 |
| 2.11 | 11.8 | 8.6 |
| 2.12–2.15 | 12.0+ | 8.9+ |
Установка TensorFlow с поддержкой GPU выполняется через pip:
pip install tensorflow[and-cuda]Пакет tensorflow[and-cuda] включает нужные зависимости и автоматически связывает TensorFlow с установленной средой CUDA. Проверить корректность вычислений можно командой:
tf.debugging.set_log_device_placement(True)При выполнении операций в журнале появится информация о том, что вычисления выполняются на GPU.
Для контроля распределения ресурсов можно ограничить использование памяти видеокарты:
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
TensorFlow использует GPU для всех операций линейной алгебры, что особенно заметно при обучении нейросетей. Поведение системы можно отследить с помощью команды !nvidia-smi, где отображается загрузка GPU, потребление памяти и активные процессы.
Оптимизация вычислений с помощью PyTorch на GPU
Для использования GPU в PyTorch необходимо указать устройство при создании тензоров или модели:
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
x = torch.randn(1000, 1000, device=device)
model = MyModel().to(device)Перед выполнением вычислений стоит проверить доступную память и загрузку GPU через torch.cuda.memory_allocated() и torch.cuda.memory_reserved(). Это позволяет избежать ошибок, связанных с переполнением памяти при обработке больших массивов данных.
Для ускорения операций рекомендуется использовать функции с inplace-операциями и переносить все промежуточные данные на GPU:
y = x.mul_(2) # inplace-умножениеPyTorch поддерживает асинхронное выполнение операций, поэтому для точного измерения времени необходимо синхронизировать GPU:
torch.cuda.synchronize()
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
output = model(x)
end.record()
torch.cuda.synchronize()
print(start.elapsed_time(end), "ms")Оптимизация обучения нейросетей включает использование mixed precision через torch.cuda.amp, что снижает потребление памяти и ускоряет вычисления без потери точности:
scaler = torch.cuda.amp.GradScaler()
with torch.cuda.amp.autocast():
output = model(x)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()Эти методы позволяют максимально использовать ресурсы GPU в Jupyter Notebook, ускоряя обучение моделей и обработку больших данных.
Сравнение скорости выполнения задач на CPU и GPU

Для оценки ускорения вычислений в Jupyter Notebook полезно сравнивать время выполнения одинаковых операций на CPU и GPU. Пример на PyTorch:
import torch, time
x_cpu = torch.randn(107)
start = time.time()
y_cpu = x_cpu 2
print("CPU:", time.time() - start, "секунд")
device = torch.device('cuda')
x_gpu = x_cpu.to(device)
torch.cuda.synchronize()
start = time.time()
y_gpu = x_gpu 2
torch.cuda.synchronize()
print("GPU:", time.time() - start, "секунд")На современных видеокартах с 8 ГБ памяти ускорение для массивов размером 107 элементов составляет от 15 до 50 раз по сравнению с CPU. Для операций с меньшими массивами выигрыш менее заметен из-за накладных расходов на передачу данных между памятью CPU и GPU.
При работе с TensorFlow сравнение можно выполнять аналогично, используя tf.device:
import tensorflow as tf, time
x_cpu = tf.random.normal([107])
with tf.device('/CPU:0'):
start = time.time()
y_cpu = x_cpu 2
print("CPU:", time.time() - start)
with tf.device('/GPU:0'):
x_gpu = tf.identity(x_cpu)
tf.experimental.async_scope().sync() # синхронизация
start = time.time()
y_gpu = x_gpu 2
tf.experimental.async_scope().sync()
print("GPU:", time.time() - start)Рекомендация: для больших массивов и сложных моделей использование GPU значительно сокращает время обучения и обработки данных. При мелких задачах CPU может быть предпочтительнее из-за отсутствия затрат на копирование данных на видеокарту.
Типичные ошибки при работе с GPU и способы их устранения
При использовании GPU в Jupyter Notebook часто встречаются ошибки, связанные с настройкой среды и ограничениями видеокарты. Основные проблемы и методы их устранения:
- GPU не определяется
- Причины: отсутствует драйвер NVIDIA, несовместимая версия CUDA или библиотека не поддерживает GPU.
- Решение: установить или обновить драйвер, проверить соответствие версии CUDA требованиям используемой библиотеки (TensorFlow, PyTorch, CuPy).
- Недостаток видеопамяти
- Причины: слишком большой массив данных, одновременное выполнение нескольких моделей.
- Решение: уменьшить размер батча, использовать mixed precision, освобождать память с помощью
torch.cuda.empty_cache()или аналогичных функций.
- CUDARuntimeError
- Причины: несовпадение версий драйвера и CUDA, поврежденные установки библиотек.
- Решение: проверить версии
nvcc --versionиnvidia-smi, переустановить CUDA Toolkit и библиотеки.
- Медленное выполнение на GPU
- Причины: частые передачи данных между CPU и GPU, маленькие массивы данных.
- Решение: переносить все вычисления на GPU, объединять операции в батчи, использовать асинхронные вызовы и синхронизацию при необходимости.
- Ошибка несовместимости библиотек
- Причины: PyTorch, TensorFlow или CuPy используют разные версии CUDA.
- Решение: согласовать версии библиотек и CUDA, использовать официальные пакеты с поддержкой конкретной версии CUDA.
Соблюдение этих рекомендаций позволяет минимизировать сбои при работе с GPU и ускоряет вычисления в Jupyter Notebook без потери стабильности и точности.
Вопрос-ответ:
Как проверить, видит ли Jupyter Notebook мой GPU?
Для проверки доступности GPU можно использовать команду !nvidia-smi в ячейке Notebook. Она выводит информацию о видеокарте, объёме памяти и текущей загрузке. В Python также можно проверить через PyTorch: torch.cuda.is_available() или через TensorFlow: tf.config.list_physical_devices('GPU'). Если устройства нет в списке, нужно убедиться в правильной установке драйвера NVIDIA и версии CUDA.
Какая версия CUDA нужна для работы TensorFlow на GPU?
Каждая версия TensorFlow поддерживает определённые версии CUDA и cuDNN. Например, TensorFlow 2.11 требует CUDA 11.8 и cuDNN 8.6. Несоответствие версий вызывает ошибки при инициализации GPU. Проверить установленные версии можно через команды nvcc --version для CUDA и !nvidia-smi для драйвера.
Почему код на GPU иногда работает медленнее, чем на CPU?
Медленное выполнение на GPU часто связано с передачей небольших объёмов данных между CPU и GPU. Для малых массивов накладные расходы на копирование могут превышать выигрыш от параллельных вычислений. Оптимизация требует переноса всех операций на GPU и объединения данных в большие батчи.
Какие ошибки чаще всего возникают при работе с PyTorch на GPU?
Типичные ошибки включают Недостаток памяти, когда батчи слишком большие, и CUDARuntimeError, связанный с несовпадением версий драйвера и CUDA. Решения: уменьшить размер батча, использовать mixed precision, очистку памяти через torch.cuda.empty_cache(), проверить соответствие версий библиотек и CUDA.
Как оценить ускорение вычислений на GPU по сравнению с CPU?
Можно измерить время выполнения одинаковых операций на CPU и GPU. Например, в PyTorch создать массивы размером 107 элементов и выполнить возведение в квадрат. На современных видеокартах ускорение может достигать 15–50 раз. Для точного замера на GPU необходимо синхронизировать устройство через torch.cuda.synchronize().