Содержание статьи

Кластер объединяет несколько компьютеров в общую систему, где все узлы работают как единое вычислительное пространство. Это позволяет распределять задачи, повышать производительность и использовать ресурсы более рационально. Для создания кластера не требуется специализированное оборудование – достаточно совместимых машин и стабильного сетевого соединения.
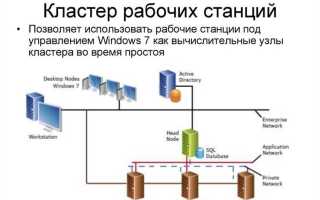
Базовая конфигурация включает управляющий узел и несколько рабочих. Управляющий отвечает за распределение заданий и контроль состояния системы, а рабочие выполняют вычисления или обслуживают запросы. Для организации такой структуры подойдут дистрибутивы Linux с поддержкой сетевых сервисов и инструментов автоматизации, например Ubuntu Server или Rocky Linux.
Перед сборкой стоит убедиться, что все компьютеры подключены к одной сети, имеют статические IP-адреса и доступ по SSH без пароля. Синхронизация времени через NTP предотвращает ошибки при распределённых вычислениях. После этого можно устанавливать программные пакеты для управления кластером – OpenMPI, Slurm или Kubernetes, в зависимости от задач.
Выбор архитектуры и типа кластера для конкретных задач

Перед сборкой кластера нужно определить его назначение. От этого зависит архитектура, программная среда и способ взаимодействия между узлами. Для вычислений подойдут решения на базе HPC (High Performance Computing), где задачи делятся на блоки и выполняются параллельно. Для хранения данных лучше выбрать файловый кластер с общей файловой системой, например GlusterFS или Ceph.
Вычислительные кластеры делятся на два типа: с общей памятью и с распределённой. Первый вариант проще в настройке, но требует совместимого оборудования и подходит для задач, где узлы обрабатывают одни и те же данные. Распределённая архитектура масштабируется гибче, позволяет использовать разнородные узлы и подходит для симуляций, обработки изображений и анализа больших массивов данных.
Для домашних или учебных проектов подойдут недорогие узлы на базе x86 или ARM, объединённые в сеть с гигабитным или быстрее подключением. При промышленном использовании стоит учитывать энергопотребление, отказоустойчивость и возможность замены узлов без остановки всей системы. Оптимальный выбор архитектуры определяется балансом между производительностью, масштабируемостью и целевыми задачами.
Подготовка оборудования и сетевого окружения

Стабильная работа кластера зависит от согласованной конфигурации всех узлов и надёжной сетевой инфраструктуры. Для начала следует определить минимальные требования к аппаратным ресурсам и убедиться в их совместимости.
- Процессоры и память: рекомендуется использовать одинаковые или близкие по характеристикам CPU и объём ОЗУ, чтобы избежать дисбаланса при распределении задач.
- Накопители: достаточно стандартных SSD или HDD, но важно, чтобы объём и скорость записи были сопоставимы между узлами.
- Сетевые карты: гигабитные интерфейсы – минимальный стандарт, однако при высокой нагрузке желательно 10 GbE или выше.
Для соединения узлов предпочтительна проводная сеть с коммутатором без ограничений по пропускной способности. Каждый компьютер должен иметь статический IP-адрес, уникальное имя хоста и одинаковые настройки времени BIOS.
На всех машинах стоит установить одинаковые версии операционной системы и пакетов. Это исключит несовместимости при обмене данными и при установке управляющего ПО. После сборки сети необходимо проверить доступность всех узлов командой ping и убедиться, что между ними возможен обмен по SSH без ввода пароля.
Настройка операционных систем и сетевых адресов
Для стабильной работы кластера все узлы должны использовать одинаковую операционную систему и одинаковые версии ключевых пакетов. Оптимальный выбор – минимальная установка Linux без графического интерфейса, например Ubuntu Server, Debian или Rocky Linux. Это снижает нагрузку и упрощает администрирование.
После установки ОС необходимо обновить систему и установить базовые пакеты:
sudo apt update && sudo apt upgrade -y
На каждом узле задаются уникальные имена хостов, например node1, node2, master. Эти имена должны быть прописаны в файле /etc/hosts для локального разрешения адресов без DNS. Пример записи:
192.168.0.10 master
192.168.0.11 node1
192.168.0.12 node2
Сетевые интерфейсы рекомендуется настраивать со статическими IP-адресами, чтобы обеспечить предсказуемость при подключении. Пример конфигурации для netplan в Ubuntu:
addresses: [192.168.0.11/24]
gateway4: 192.168.0.1
nameservers: [8.8.8.8]
Для беспрепятственного обмена данными между узлами необходимо настроить вход без пароля по SSH. Для этого на управляющем сервере создаётся ключ командой ssh-keygen и копируется на остальные машины с помощью ssh-copy-id. После проверки соединения можно переходить к установке управляющего программного обеспечения.
Установка и конфигурация программ для управления кластером

После настройки сети и операционных систем необходимо установить инструменты, управляющие распределением задач и взаимодействием между узлами. Выбор зависит от цели кластера: вычислительные задачи, хранение данных или контейнеризация.
Для вычислительных кластеров подходит OpenMPI. Устанавливается командой sudo apt install openmpi-bin openmpi-common libopenmpi-dev -y. После установки нужно убедиться, что все узлы видят друг друга по SSH, и создать файл hosts со списком IP-адресов рабочих машин. Проверка выполняется командой mpirun -np 4 -hostfile hosts hostname.
Для управления заданиями и мониторинга используется Slurm. На управляющем узле ставится slurmctld, на рабочих – slurmd. В конфигурационном файле /etc/slurm/slurm.conf указываются параметры сети, имена узлов, количество процессоров и путь к логам. После запуска службы sudo systemctl start slurmctld slurmd можно проверять очередь командой sinfo.
Если кластер строится для работы с контейнерами, применяется Kubernetes. Устанавливаются компоненты kubeadm, kubelet и kubectl. На управляющем узле выполняется kubeadm init, затем к нему подключаются рабочие узлы с помощью сгенерированной команды kubeadm join. Для управления кластерами контейнеров подойдёт сетевой плагин Flannel или Calico.
После развертывания управляющего ПО нужно протестировать взаимодействие между узлами, запустив тестовое задание. Это подтвердит корректность сетевых путей и синхронизацию конфигураций.
Настройка общего хранилища и синхронизация данных
Для корректной работы кластера важно организовать общий доступ к данным и обеспечить их синхронизацию между узлами. Наиболее популярные решения – GlusterFS и Ceph, которые позволяют создавать распределённое файловое хранилище с отказоустойчивостью.
При использовании GlusterFS создаётся том, который монтируется на всех рабочих узлах. Пример команд:
gluster volume create cluster_volume replica 2 transport tcp node1:/data node2:/data
gluster volume start cluster_volume
mount -t glusterfs node1:/cluster_volume /mnt/cluster
Ceph подходит для более крупных кластеров и предоставляет интерфейсы RBD и CephFS. Необходимо развернуть мониторинг, менеджеры и хранилища объектов. После инициализации создаются пул и файловая система для монтирования на всех узлах.
Для синхронизации небольших каталогов можно использовать rsync. Таблица ниже показывает базовые параметры для копирования и проверки данных:
| Команда | Описание |
|---|---|
| rsync -avz /data/ node2:/data/ | Копирование каталога /data с node1 на node2 с сохранением прав и временных меток |
| rsync -avz —delete /data/ node2:/data/ | Полная синхронизация с удалением файлов на node2, которых нет на node1 |
| rsync -avz —progress /data/ node2:/data/ | Копирование с отображением прогресса передачи файлов |
После настройки общего хранилища и синхронизации данных важно регулярно проверять целостность файлов и скорость передачи между узлами, чтобы исключить задержки при выполнении распределённых задач.
Проверка соединения и распределения нагрузки между узлами
После установки управляющего ПО необходимо убедиться, что все узлы правильно соединены и задачи распределяются корректно. Для этого выполняется несколько проверок на сетевое взаимодействие и балансировку нагрузки.
- Проверка доступности узлов: используйте команду ping для каждого узла. Пример: ping 192.168.0.11. Отсутствие потерь пакетов подтверждает стабильное соединение.
- Тест SSH: убедитесь, что доступ без пароля работает для всех узлов: ssh node1 hostname.
- Проверка сетевого обмена данными: используйте iperf3 для измерения пропускной способности между узлами. Команда на сервере: iperf3 -s, на клиенте: iperf3 -c 192.168.0.11.
После проверки соединения выполняется тест распределения нагрузки:
- Создайте тестовую задачу для управляющего ПО, например mpirun -np 4 -hostfile hosts hostname для OpenMPI.
- Проверьте, что все узлы получили задания и отчитались о завершении.
- Для Slurm используйте srun -N2 -n4 hostname и squeue для отслеживания состояния задач.
При выявлении узлов с меньшей загрузкой проверьте их аппаратные параметры, сетевые настройки и конфигурацию управляющего ПО. После корректировки повторите тесты до равномерного распределения вычислительных ресурсов.
Мониторинг работы кластера и устранение сбоев

Для поддержания стабильной работы кластера необходимо регулярно отслеживать состояние узлов, загрузку ресурсов и доступность сервисов. На уровне операционной системы используются утилиты top, htop, vmstat и iostat для контроля процессора, памяти и дисковой подсистемы.
Для мониторинга распределённых задач применяются встроенные инструменты управляющего ПО:
- OpenMPI: проверка выполнения задач через лог-файлы и mpirun с ключом —report-bindings для контроля распределения процессов.
- Slurm: команды squeue для очереди задач, sinfo для состояния узлов и sprio для приоритетов.
- Kubernetes: kubectl get nodes и kubectl get pods позволяют отслеживать состояние контейнеров и узлов.
При обнаружении сбоев сначала проверяют сетевое соединение и доступность узлов по ping и SSH. Если проблема в ресурсах, выполняется перераспределение задач или добавление вычислительных узлов. Для автоматического уведомления о сбоях можно настроить cron-скрипты с проверкой логов и отправкой сообщений на e-mail или в мессенджеры.
Регулярная проверка файлового хранилища и синхронизации данных помогает избежать ошибок при обработке задач. Для GlusterFS и Ceph используются команды gluster volume status и ceph status. При выявлении расхождений выполняется пересинхронизация или восстановление реплик.
Вопрос-ответ:
Какие компьютеры подходят для сборки кластера дома или в учебных целях?
Для небольшого домашнего или учебного кластера подходят обычные настольные ПК или ноутбуки с одинаковой архитектурой процессоров. Важно, чтобы они имели достаточный объём оперативной памяти для выполняемых задач и сетевые интерфейсы с поддержкой гигабитного соединения. SSD-диски ускоряют работу, но для экспериментов можно использовать стандартные HDD. Разнородные узлы допустимы, но их производительность будет определять слабейшее звено кластера.
Как правильно настроить сеть для кластера, чтобы узлы видели друг друга?
Необходимо подключить все узлы к одному коммутатору или роутеру с проводными соединениями. Каждому компьютеру присваивается статический IP-адрес, а в файле /etc/hosts прописываются имена всех узлов с соответствующими адресами. Настройка SSH без пароля обеспечивает удобный обмен данными и выполнение команд на удалённых узлах. Дополнительно рекомендуется синхронизировать время через NTP, чтобы исключить ошибки при распределённых вычислениях.
Какие инструменты использовать для управления задачами в кластере?
Для распределённых вычислений подходит OpenMPI, который делит задачи между узлами и отслеживает их выполнение. Для очередей задач и планирования используется Slurm, позволяющий контролировать распределение процессов и приоритеты. Если кластер ориентирован на контейнеры, применяются Kubernetes и сетевые плагины вроде Flannel или Calico. Важно проверить соединение всех узлов и доступность по SSH перед запуском управляющего ПО.
Как проверить, что кластер работает корректно и распределяет нагрузку равномерно?
Для проверки используют тестовые задания. В OpenMPI запускают mpirun -np N -hostfile hosts hostname, чтобы увидеть, какие узлы выполняют задачи. В Slurm проверяют очередь командой squeue и выполняют srun для тестовой нагрузки. В Kubernetes проверяют состояние контейнеров через kubectl get nodes и kubectl get pods. Если отдельные узлы выполняют меньше задач, следует проверить их сетевые настройки, процессорную нагрузку и доступность ресурсов.