Содержание статьи

Парсинг HTML с помощью Python позволяет извлекать текст из веб-страниц без необходимости вручную копировать содержимое. Для этого чаще всего используют библиотеки BeautifulSoup и lxml, которые обеспечивают удобное обращение к тегам и атрибутам. BeautifulSoup подходит для небольших и средних проектов, а lxml демонстрирует высокую скорость обработки больших HTML-документов.
Регулярные выражения помогают отбирать текст по определенным шаблонам, например, извлечь только заголовки или ссылки с конкретными классами. Такой подход полезен, когда структура HTML нестабильна и требуется фильтрация по контенту, а не по тегам.
При работе с таблицами и списками важно учитывать вложенность тегов. Python позволяет проходить по каждому элементу, извлекать текст и сразу удалять лишние пробелы и переносы строк. Это повышает точность получаемых данных и облегчает последующую обработку.
Для сайтов с динамическим контентом используется Selenium, который управляет браузером и позволяет получить окончательный HTML после выполнения скриптов. Полученный текст можно сохранять в файлы или базы данных для дальнейшего анализа и обработки.
Использование библиотеки BeautifulSoup для извлечения текста из тегов

Для начала работы с BeautifulSoup необходимо установить библиотеку через pip: pip install beautifulsoup4. После этого HTML-документ загружается с помощью BeautifulSoup(html_content, ‘html.parser’), где html_content – строка с исходным кодом страницы.
Метод find_all позволяет выбрать все теги определенного типа, например, soup.find_all(‘p’) извлечет все абзацы. Чтобы получить текст внутри тега, используется свойство .text или .get_text(). Для фильтрации по атрибутам применяется параметр attrs, например: soup.find_all(‘div’, attrs={‘class’: ‘content’}).
Для работы с вложенными тегами рекомендуется использовать метод select с CSS-селекторами. Например, soup.select(‘div.content > p’) выбирает все абзацы внутри div с классом content, исключая текст из других блоков.
При извлечении текста важно сразу удалять лишние пробелы и переносы строк с помощью .strip() или регулярных выражений. Это повышает точность анализа и позволяет сразу сохранять данные в нужном формате, будь то CSV или база данных.
Применение регулярных выражений для выборочного отделения текста
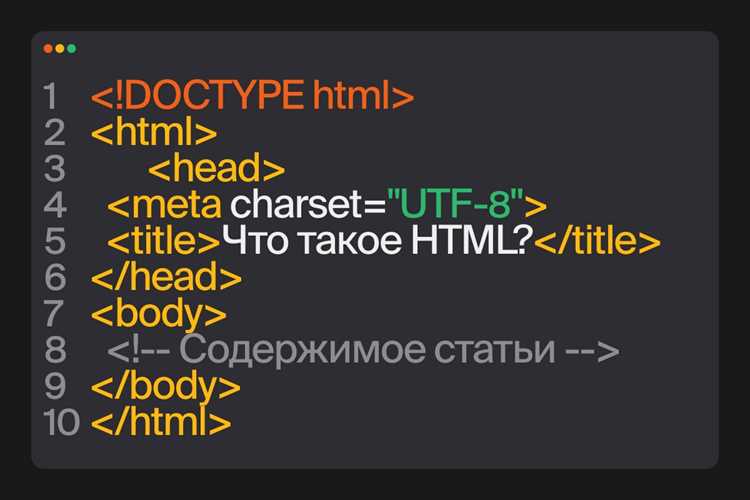
Библиотека re в Python позволяет извлекать текст по заданным шаблонам. Для поиска всех совпадений используется функция re.findall(pattern, text), где pattern – регулярное выражение, а text – HTML-код или уже очищенный текст.
Примеры шаблонов включают извлечение ссылок: r’href=»([^»]+)»‘ найдет все значения атрибута href, или заголовков: r’
(.*?)

‘. Для выбора элементов с определенным классом используют выражения вида r’
‘, что позволяет отделять текст внутри конкретных блоков.
Чтобы избежать захвата лишнего текста при использовании жадных квантификаторов, рекомендуется применять ? после * или +, например: r'(.*?)’. Для последующей очистки текста от HTML-тегов используют re.sub(r’<[^>]+>’, », matched_text), удаляя оставшиеся элементы разметки.
Регулярные выражения эффективны при нестабильной структуре HTML, когда необходимо извлечь только конкретные фрагменты текста, не полагаясь на дерево тегов. Их удобно комбинировать с BeautifulSoup для предварительной фильтрации блоков.
Работа с lxml для парсинга и фильтрации HTML-содержимого
Библиотека lxml позволяет быстро и точно разбирать HTML-документы. Для начала нужно установить пакет через pip: pip install lxml. Основной объект создается с помощью from lxml import html; tree = html.fromstring(html_content), где html_content – строка с HTML-кодом.
Основные возможности:
- Выбор элементов через XPath: tree.xpath(‘//div[@class=»content»]/p/text()’) возвращает текст всех абзацев внутри div с классом content.
- Фильтрация по атрибутам и тегам: tree.xpath(‘//a[@href]’) выбирает все ссылки с атрибутом href.
- Извлечение вложенного текста: tree.xpath(‘//ul/li/text()’) позволяет получить список элементов списка без HTML-тегов.
Рекомендации при работе с lxml:
- Сначала фильтруйте блоки с помощью XPath, затем извлекайте текст. Это ускоряет обработку больших страниц.
- Для очистки текста от лишних пробелов используйте .strip() и join() при объединении нескольких элементов.
- Сохраняйте результаты сразу в списки или словари для последующей обработки или экспорта в CSV/JSON.
lxml подходит для проектов, где требуется высокая скорость и точная фильтрация HTML-структуры. Комбинация XPath и методов очистки текста позволяет быстро получить нужный контент без лишней разметки.
Извлечение текста из таблиц и списков HTML
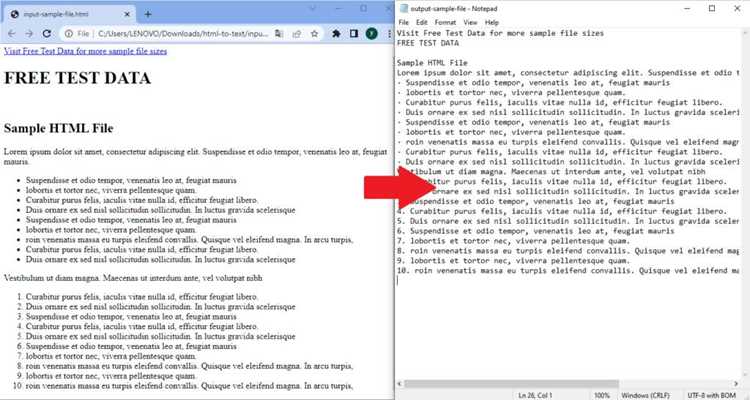
Для извлечения текста из таблиц и списков удобно использовать BeautifulSoup или lxml. В таблицах информация структурирована в tr и td, а в списках – в ul/li или ol/li. Основная задача – пройтись по каждому элементу и получить текст без HTML-тегов.
Пример работы с таблицами:
- Выбираем все строки: rows = soup.find_all(‘tr’).
- Проходим по каждой строке и извлекаем ячейки: cells = [td.get_text(strip=True) for td in row.find_all(‘td’)].
- Сохраняем данные в список или CSV для дальнейшего анализа.
Для списков:
- Выбираем элементы списка: items = soup.find_all(‘li’).
- Извлекаем текст с удалением лишних пробелов: text_items = [item.get_text(strip=True) for item in items].
- Если списки вложенные, рекурсивно обходим подсписки, чтобы сохранить иерархию.
При использовании lxml применяют XPath:
- Таблицы: tree.xpath(‘//table/tr/td/text()’) возвращает все ячейки.
- Списки: tree.xpath(‘//ul/li/text()’) или tree.xpath(‘//ol/li/text()’) извлекает все элементы.
Для точного анализа важно сразу удалять лишние символы и объединять текст из нескольких ячеек или элементов списка в одну структуру данных.
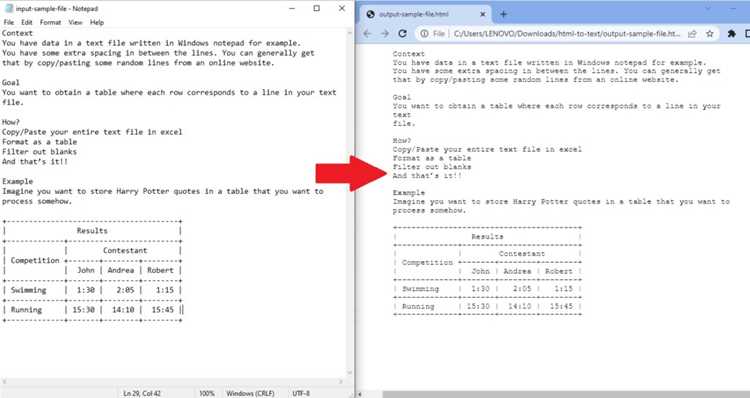
Удаление лишних пробелов и символов при парсинге текста
При извлечении текста из HTML часто остаются лишние пробелы, переносы строк и специальные символы. Их удаление улучшает читаемость и упрощает дальнейшую обработку данных.
Основные методы очистки:
| Метод | Описание | Пример |
|---|---|---|
| .strip() | Удаляет пробелы и переносы строк в начале и конце строки | text = element.get_text().strip() |
| re.sub() | Заменяет или удаляет символы по регулярному выражению | text = re.sub(r’\s+’, ‘ ‘, text) – объединяет последовательности пробелов в один |
| .replace() | Удаляет конкретные символы, например неразрывные пробелы или табуляцию | text = text.replace(‘\xa0’, ‘ ‘) |
Для структурированных данных из таблиц и списков рекомендуется очищать текст сразу после извлечения каждой ячейки или элемента списка. Это позволяет сохранить корректную структуру данных и избежать накопления лишних символов при сохранении в CSV или JSON.
Сравнение подходов: BeautifulSoup против регулярных выражений
BeautifulSoup работает с деревом тегов HTML, что позволяет точно выбирать элементы по имени тега, атрибутам или вложенности. Преимущество заключается в стабильности: даже при изменении порядка тегов структура данных сохраняется. Для извлечения текста из блоков с определенными классами или ID применяются методы find, find_all и select, а очистка текста выполняется через .get_text(strip=True).
Регулярные выражения оперируют непосредственно текстом HTML и подходят для поиска конкретных шаблонов, например, ссылок, заголовков или email. Они быстрее для простых задач, но чувствительны к изменениям структуры и вложенности тегов. Для точного извлечения рекомендуется использовать жадные и ленивые квантификаторы и комбинировать с re.sub() для удаления лишних тегов.
Практическая рекомендация:
- Использовать BeautifulSoup для сложной структуры и вложенных элементов, когда важна корректность данных.
- Применять регулярные выражения для быстрого извлечения повторяющихся паттернов или при фильтрации конкретного контента внутри HTML.
- Комбинировать оба подхода: сначала отфильтровать блоки с помощью BeautifulSoup, затем точечно выбрать текст с помощью регулярных выражений.
Сохранение извлеченного текста в файлы или базы данных
После отделения текста из HTML важно корректно сохранить данные для последующего анализа или обработки. В Python чаще используют запись в текстовые файлы, CSV или базы данных.
Для текстовых файлов применяют стандартную функцию open с режимом ‘w’ или ‘a’:
with open(‘output.txt’, ‘w’, encoding=’utf-8′) as f: f.write(text). Это позволяет сохранить как отдельные строки, так и объединенные блоки текста.
CSV-файлы удобны для структурированных данных, например таблиц:
import csv
with open(‘output.csv’, ‘w’, newline=», encoding=’utf-8′) as csvfile:
writer = csv.writer(csvfile)
for row in data:
writer.writerow(row)
Для баз данных используют sqlite3 или другие SQL-библиотеки. Пример:
import sqlite3
conn = sqlite3.connect(‘data.db’)
cursor = conn.cursor()
cursor.execute(‘CREATE TABLE IF NOT EXISTS content (text TEXT)’)
cursor.executemany(‘INSERT INTO content (text) VALUES (?)’, [(t,) for t in data])
conn.commit()
conn.close()
Рекомендации:
- Сохранять текст сразу после парсинга, чтобы избежать потери данных.
- Использовать UTF-8 для корректного отображения символов.
- Для больших объемов данных предпочтительнее базы данных, так как они позволяют быстро фильтровать и обновлять записи.
Обработка динамического HTML с использованием Selenium
Сайты с динамическим контентом формируют HTML с помощью JavaScript, что делает невозможным извлечение текста обычными парсерами. Selenium позволяет управлять браузером и получить готовый HTML после выполнения скриптов.
Установка и базовый запуск:
pip install selenium
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘https://example.com’)
После загрузки страницы извлекается HTML:
html_content = driver.page_source, который затем можно передавать в BeautifulSoup или lxml для дальнейшего отделения текста.
Практические рекомендации:
| Задача | Решение с Selenium |
|---|---|
| Дождаться загрузки динамического контента | Использовать WebDriverWait с условием presence_of_element_located |
| Извлечение текста из скрытых элементов | Применять element.text после скролла или клика, если элемент становится видимым |
| Сбор нескольких страниц | Навигация через driver.find_element().click() или изменение URL, с повторным извлечением page_source |
Использование Selenium обеспечивает точное получение текста с любых сайтов, независимо от загрузки контента через JavaScript. Для больших проектов рекомендуется закрывать браузер после парсинга с помощью driver.quit(), чтобы экономить ресурсы.
Вопрос-ответ:
Какие библиотеки Python лучше использовать для извлечения текста из HTML?
Для парсинга HTML чаще всего применяют BeautifulSoup и lxml. BeautifulSoup удобна для работы с небольшими страницами и предоставляет методы find, find_all и select для точного выбора тегов и блоков текста. Lxml обеспечивает более высокую скорость обработки больших документов и позволяет использовать XPath для точной фильтрации элементов.
Можно ли отделять текст из HTML с помощью регулярных выражений?
Да, регулярные выражения подходят для выборочного извлечения текстовых фрагментов, например, ссылок, заголовков или элементов с конкретным классом. Для этого используют функции re.findall и re.sub. Важно применять ленивые квантификаторы и фильтровать ненужные теги, иначе регулярка может захватить лишний текст.
Как извлекать текст из таблиц и списков HTML?
В таблицах текст находится внутри тегов tr и td, в списках — в ul/li или ol/li. С помощью BeautifulSoup можно пройтись по каждому элементу и вызвать .get_text(strip=True), чтобы убрать лишние пробелы. Lxml позволяет использовать XPath, например, ‘//table/tr/td/text()’ для таблиц и ‘//ul/li/text()’ для списков, что ускоряет извлечение.
Как обрабатывать динамический контент на сайтах?
Если HTML формируется через JavaScript, обычный парсер не даст всех данных. В таких случаях применяют Selenium, который управляет браузером, ожидает загрузки элементов и получает финальный HTML через driver.page_source. После этого текст можно отделять привычными методами BeautifulSoup или lxml. Для страниц с постраничной навигацией используют переход по ссылкам через клики или изменение URL.
Какие способы очистки текста после парсинга считаются надежными?
После извлечения текста важно удалить лишние пробелы, переносы строк и специальные символы. Для этого применяют .strip(), re.sub(r’\s+’, ‘ ‘, text) и .replace() для конкретных символов, например, неразрывных пробелов. При работе с таблицами и списками рекомендуется очищать текст сразу после извлечения каждой ячейки или элемента списка, чтобы сохранить корректную структуру данных для CSV или базы данных.
Как выбрать подход между BeautifulSoup и регулярными выражениями для извлечения текста из HTML?
Если структура HTML стабильная и важна точность, лучше использовать BeautifulSoup. Она позволяет выбирать элементы по тегам, классам и вложенности, а текст можно сразу очищать через .get_text(strip=True). Регулярные выражения удобны для быстрого извлечения повторяющихся шаблонов, например, ссылок или email, но чувствительны к изменению структуры и вложенности тегов. В сложных случаях можно сначала отфильтровать блоки через BeautifulSoup, а затем извлечь текст по шаблону с помощью регулярных выражений.
Какие методы подходят для работы с динамическим контентом на веб-страницах?
Для страниц, где HTML формируется JavaScript, используют Selenium. Он запускает браузер, ожидает загрузки нужных элементов через WebDriverWait и получает финальный HTML через driver.page_source. После этого текст можно извлекать привычными методами BeautifulSoup или lxml. Для навигации по нескольким страницам применяют клики по кнопкам или изменение URL, а текст сохраняют сразу после парсинга, чтобы избежать потери данных.