Содержание статьи

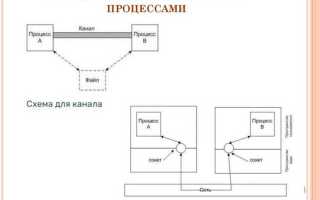
Pipe – это низкоуровневый канал передачи данных между процессами, обеспечивающий последовательный поток байтов от отправителя к получателю. В системах Linux и Unix pipe создаётся через системный вызов pipe(), который возвращает два файловых дескриптора: для чтения и записи. Такой механизм эффективен для передачи больших объёмов данных без обращения к диску и с минимальной задержкой.
Размер стандартного буфера pipe в Linux составляет 65536 байт. При достижении этого объёма процесс записи приостанавливается до освобождения пространства на стороне чтения. Эффективная стратегия работы с pipe включает разбиение больших блоков данных на фрагменты меньшего размера, что снижает вероятность блокировки и ускоряет обмен между процессами.
Использование pipe актуально для организации конвейеров командной строки, передачи логов в реальном времени и обмена потоками данных между микросервисами. В случаях, когда процессы не имеют прямого родительского соединения, рекомендуется применять именованные pipe (FIFO), которые позволяют поддерживать постоянный канал передачи данных без создания временных файлов.
Для повышения надёжности обмена необходимо контролировать закрытие дескрипторов после завершения передачи и учитывать возможные ошибки записи или чтения. Применение комбинации анонимных и именованных pipe позволяет строить гибкие системы межпроцессного взаимодействия с минимальными накладными расходами и высокой производительностью.
Процессы, способные обмениваться данными через pipe
Процессы, использующие pipe, должны находиться в тесной синхронизации: процесс-отправитель записывает данные в конец pipe, а процесс-получатель считывает их с начала. Несоблюдение порядка чтения и записи может привести к блокировке или потере данных.
Для эффективного обмена через pipe рекомендуется использовать буферы фиксированного размера, например 4 КБ, что соответствует стандартному размеру страницы в большинстве систем и уменьшает вероятность частичного чтения данных.
Pipe поддерживает только однонаправленную передачу данных. Если требуется двунаправный обмен, следует создавать два pipe – один для каждого направления, либо использовать именованный pipe (FIFO), который позволяет соединять процессы независимо от их иерархии.
Процессы-потомки, создаваемые через fork(), автоматически наследуют дескрипторы pipe, что облегчает организацию потоков данных между родителем и потомками без дополнительного открытия файлов.
При передаче больших объемов информации через pipe важно контролировать заполнение буфера. В POSIX-системах стандартный размер pipe ограничен 64 КБ; превышение этого лимита вызывает блокировку записи до освобождения места в буфере.
Практическая рекомендация: закрывать неиспользуемые концы pipe в каждом процессе. Например, процесс-читатель должен закрыть дескриптор записи, чтобы избежать ложного ожидания конца данных, а процесс-записчик – дескриптор чтения. Это обеспечивает корректное завершение обмена и предотвращает дедлоки.
Создание анонимного pipe между двумя процессами в Linux

Анонимный pipe создаётся системным вызовом pipe(), который возвращает два файловых дескриптора: fd[0] для чтения и fd[1] для записи; после fork() родитель и дочерний процесс наследуют оба конца канала, поэтому сразу закрывают неиспользуемые дескрипторы, иначе read() не получит EOF. Канал работает как однонаправленный буфер ядра (обычно 65536 байт, проверяется через /proc/sys/fs/pipe-max-size); запись блокируется при переполнении, чтение – при отсутствии данных, если дескриптор не переведён в O_NONBLOCK через fcntl(). Для передачи структурированных данных фиксируют размер сообщений или добавляют префикс длины; атомарность гарантируется только для записей до PIPE_BUF (минимум 4096 байт). Проверяйте коды возврата read()/write(): 0 – конец потока, -1 с EPIPE – запись в закрытый канал, EINTR – повтор вызова.
| Параметр | Значение/рекомендация |
|---|---|
| PIPE_BUF | ≥4096 байт; записи меньшего размера атомарны |
| Тип канала | Однонаправленный; для двустороннего обмена создают два pipe() |
| Блокировки | По умолчанию блокирующий режим; используйте O_NONBLOCK при необходимости |
| Наследование | После fork() закрывайте лишние концы для корректного EOF |
| Сигналы | SIGPIPE при записи без читателя; обрабатывайте или игнорируйте |
Практическая схема: вызывается pipe(), затем fork(); в дочернем процессе закрывается конец записи и выполняется чтение циклом с обработкой частичных чтений, в родительском – закрывается конец чтения и выполняется пакетная запись с контролем возврата и ретраями при EINTR; для запуска внешней программы применяют dup2() для переназначения STDIN/STDOUT на соответствующие дескрипторы и затем execve(). Для повышения пропускной способности объединяйте мелкие записи в буферы, избегайте частых системных вызовов, при больших потоках данных используйте splice() или vmsplice() для zero-copy между pipe и файловыми дескрипторами. Отладка: strace -e trace=read,write,close выявляет утечки дескрипторов; lsof подтверждает закрытие концов; poll()/epoll() предотвращают активное ожидание и позволяют обслуживать несколько каналов одновременно.
Передача текстовых и бинарных данных через pipe
Pipe обеспечивает последовательный поток данных между процессами, что позволяет передавать как текстовую, так и бинарную информацию без использования промежуточных файлов. Для текстовых данных оптимально использовать кодировку UTF-8, так как она поддерживается практически всеми современными системами и предотвращает проблемы с символами за пределами ASCII.
При передаче бинарных данных важно учитывать, что стандартные функции чтения текста могут искажать содержимое из-за интерпретации байтов как символов. Рекомендуется использовать функции побайтного или блочного чтения и записи, чтобы сохранить исходную структуру данных. Например, в UNIX-системах read() и write() обеспечивают корректную работу с любыми байтами.
Для эффективного обмена данными через pipe нужно предусмотреть буферизацию. Размер буфера зависит от объема передаваемой информации и скорости работы процессов. Слишком маленький буфер приведет к частым системным вызовам, а слишком большой – к ненужной задержке из-за накопления данных. Практически оптимальными считаются блоки по 4–16 КБ.
Синхронизация потоков особенно важна при передаче бинарных файлов. Если один процесс пишет быстрее, чем другой читает, может произойти потеря данных или блокировка. Решением является использование неблокирующего режима pipe или select/poll для контроля готовности к чтению и записи.
Для текстовых потоков часто применяют стандартные функции форматирования, такие как printf или fprintf, которые упрощают структурирование данных и позволяют добавлять разделители между сообщениями. Это удобно, например, для логирования или передачи команд между приложениями.
При работе с бинарными данными полезно использовать маркеры длины перед каждым блоком информации. Это позволяет получающему процессу точно определить размер ожидаемого блока и избежать частичного чтения или переполнения буфера. Рекомендуется сочетать маркеры с контрольной суммой для проверки целостности переданных данных.
Использование pipe для взаимодействия родительского и дочернего процесса
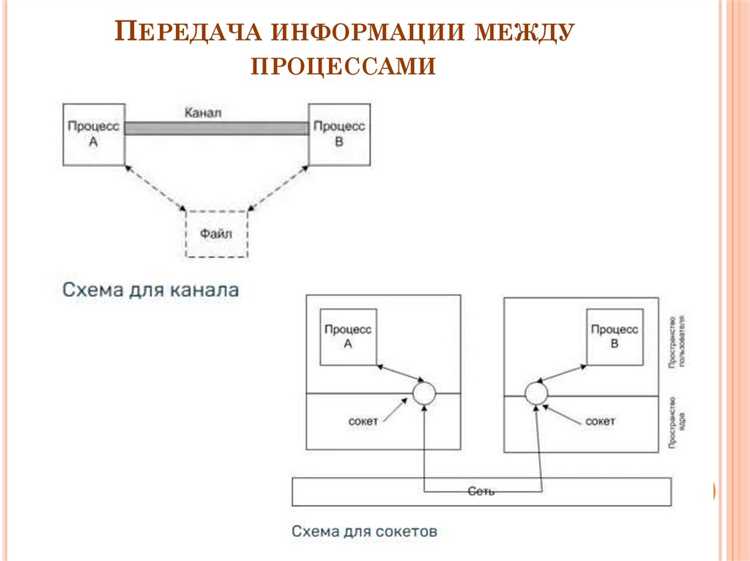
Pipe обеспечивает односторонний канал передачи данных между родительским и дочерним процессом, создавая буфер фиксированного размера в памяти ядра. Обычно используется системный вызов pipe(), который возвращает два дескриптора: для чтения и записи. Родительский процесс закрывает ненужный конец pipe, чтобы избежать блокировок при чтении или записи.
При создании дочернего процесса через fork() оба процесса наследуют дескрипторы pipe. Чтобы родитель мог отправлять данные дочернему процессу, он использует дескриптор записи, а дочерний – дескриптор чтения. Рекомендуется сразу закрывать противоположный конец в каждом процессе, чтобы предотвратить неопределённое поведение при EOF.
Для передачи больших объемов данных важно учитывать размер буфера pipe, который в Linux обычно составляет 64 КБ. Если родительский процесс пытается записать больше данных, чем может вместить буфер, он будет заблокирован до освобождения места дочерним процессом. Это позволяет реализовать механизм синхронизации без дополнительных примитивов.
Чтение из pipe следует выполнять с контролем возвратного значения функции read(). Она может вернуть меньше байт, чем запрашивалось, даже если передача не завершена. Поэтому необходимо использовать цикл с накоплением данных, особенно при взаимодействии с бинарными потоками или структурированными сообщениями.
Для передачи текстовой информации удобнее использовать буферизированное чтение с fgets() или аналогами, открывая дескриптор pipe через fdopen(). Это упрощает обработку строк и снижает вероятность ошибок при некорректном завершении передачи.
Pipe также применим для передачи сигналов состояния. Например, дочерний процесс может отправлять короткие уведомления о прогрессе через небольшие сообщения, а родительский процесс – реагировать на них без использования сложных межпроцессных блокировок. Такой подход повышает отзывчивость системных приложений.
Важно помнить о закрытии всех дескрипторов после завершения передачи. Если родитель или дочерний процесс оставит открытый конец pipe, функция read() никогда не вернет EOF, что может привести к зависанию. Практика показывает, что строгий контроль открытия и закрытия pipe значительно повышает надежность взаимодействия процессов.
Обработка блокировок и переполнения буфера pipe
При использовании pipe каждый канал имеет фиксированный размер буфера, обычно от 4 КБ до 64 КБ в современных Linux-системах. Если процесс-писатель превышает доступный объем буфера, запись блокируется до освобождения пространства читающим процессом.
Чтобы избежать блокировки, рекомендуется использовать неблокирующий режим. Флаги O_NONBLOCK для системных вызовов write и read позволяют процессу продолжать выполнение даже при полном или пустом буфере, возвращая ошибку EAGAIN вместо зависания.
При переполнении буфера возможна потеря данных, если не обработать сигнал SIGPIPE. Этот сигнал посылается процессу, пытающемуся записать в pipe, когда чтение уже завершено. Игнорирование SIGPIPE или установка собственного обработчика предотвращает аварийное завершение процесса.
Один из практических методов управления переполнением – использование select или poll. Эти системные вызовы позволяют проверять готовность pipe к чтению и записи, минимизируя блокировки и повышая отзывчивость многопоточных приложений.
Для больших объемов данных целесообразно разделять запись на блоки, размер которых меньше половины буфера pipe. Такой подход обеспечивает непрерывный поток данных и снижает риск блокировки писателя.
Если pipe используется между процессами с разными приоритетами, важно учитывать, что приоритеты планировщика могут влиять на скорость освобождения буфера. Использование real-time приоритетов для критичных чтений помогает поддерживать стабильность передачи данных.
В случаях, когда частое блокирование невозможно избежать, рекомендуется внедрять очередь промежуточного хранения данных в памяти или на диске. Это снижает нагрузку на pipe и позволяет асинхронно обрабатывать входящие данные без потери информации.
Для отладки проблем с блокировками можно включить трассировку системных вызовов через strace. Анализ последовательности read/write выявляет узкие места и позволяет оптимизировать размер блоков, порядок обработки и распределение потоков между писателем и читателем.
Вопрос-ответ:
Что такое pipe и как процессы могут через него обмениваться информацией?
Pipe — это механизм, который позволяет одному процессу передавать данные другому в виде непрерывного потока. Один процесс пишет информацию в pipe, а другой читает её. Этот способ обмена особенно полезен для упрощения взаимодействия между процессами без необходимости создания сложных структур или файлов для передачи данных.
Какие типы pipe существуют и чем они отличаются друг от друга?
Существуют два основных типа pipe: анонимные и именованные. Анонимные pipe обычно применяются для связи между родительским и дочерним процессом и исчезают после завершения работы процессов. Именованные pipe создаются в файловой системе и могут использоваться разными процессами, даже не связанными родством. Именованные pipe позволяют обмениваться данными более гибко и длительно.
Как синхронизируется обмен данными между процессами через pipe?
Обмен через pipe происходит последовательно: процесс-писатель помещает данные в буфер, а процесс-читалец извлекает их. Если буфер пуст, читающий процесс ожидает появления данных; если буфер заполнен, писатель приостанавливается. Такая синхронизация встроена в механизм pipe и позволяет избежать потери или смешивания информации без использования дополнительных средств.
Можно ли использовать pipe для обмена большими объёмами информации между процессами?
Да, pipe способен передавать значительные объёмы данных, но есть ограничения, связанные с размером внутреннего буфера. Если данных больше, чем может вместить буфер, процесс-писатель приостанавливается до освобождения места. Для передачи больших объёмов часто применяют разбиение данных на блоки и последовательную передачу, чтобы процесс-получатель успевал их обрабатывать.
В каких ситуациях использование pipe более удобно, чем запись в файлы или использование сокетов?
Pipe удобен, когда нужно быстро передать поток данных между процессами на одном компьютере без создания промежуточных файлов. Он работает напрямую через память операционной системы, что ускоряет обмен. Сокеты обычно применяются для сетевого взаимодействия или для связи процессов на разных машинах, а файлы подходят для долговременного хранения, но менее эффективны для мгновенной передачи больших потоков информации.
Каким образом два процесса могут обмениваться информацией через pipe в Unix-системах?
В Unix-подобных системах pipe создаёт временный канал между процессами, позволяя одному процессу передавать данные напрямую другому. Обычно один процесс записывает информацию в конец pipe, а другой читает её с начала. Pipe поддерживает последовательную передачу данных, поэтому порядок байтов сохраняется. Такой механизм упрощает взаимодействие между программами без необходимости использования файлов или сетевых соединений. Существуют как именованные, так и анонимные каналы: анонимные подходят для обмена между процессами с общим родителем, а именованные могут использоваться для коммуникации между разными процессами, не имеющими прямой иерархической связи.
В чём разница между блокирующим и неблокирующим чтением из pipe?
При блокирующем чтении процесс приостанавливается до тех пор, пока в pipe не появятся данные для чтения. Это удобно, когда процесс может ждать, но не требует активной проверки состояния канала. Неблокирующее чтение позволяет процессу проверять наличие данных и продолжать выполнение, если их пока нет, что полезно для программ с несколькими параллельными задачами или интерактивными интерфейсами. При этом необходимо обрабатывать ситуацию, когда pipe пуст, чтобы избежать ошибок или излишней нагрузки на процессор. Выбор между этими режимами зависит от логики программы и способа организации обмена информацией.