Содержание статьи

Apache Lucene представляет собой библиотеку для полнотекстового поиска, написанную на Java. Она позволяет создавать поисковые индексы, обеспечивающие быстрый доступ к текстовым данным объемом от десятков мегабайт до сотен гигабайт. Lucene не является самостоятельным поисковым сервером, но служит ядром многих систем, включая Elasticsearch и Apache Solr.
Индексирование в Lucene строится на основе обратного индекса, где каждому слову сопоставляется список документов, в которых оно встречается. Это позволяет значительно ускорить поиск по сравнению с последовательным сканированием текста. Библиотека поддерживает работу с токенизаторами, стеммерами и фильтрами, что обеспечивает точное выделение значимых слов и игнорирование служебных символов или стоп-слов.
Поиск выполняется через построение запросов, которые анализируются и сопоставляются с индексом. Lucene использует алгоритм TF-IDF и в более новых версиях BM25 для ранжирования результатов, что позволяет отдавать приоритет документам с более релевантным содержанием. Важно учитывать, что корректная настройка анализаторов и структуры индекса напрямую влияет на точность и скорость поиска.
Кроме базового поиска, Lucene позволяет реализовать фильтры, слияние сегментов индекса, обновление и удаление документов без полной пересборки индекса. Это делает его пригодным для интеграции в приложения с динамическими данными и высокой нагрузкой на поиск.
Архитектура Lucene и её ключевые модули
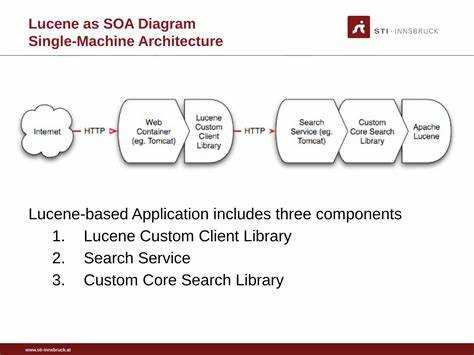
Lucene построен на модульной архитектуре, включающей индексатор, поисковый движок и анализаторы текста. Индексатор отвечает за преобразование документов в структурированные сегменты, которые сохраняются в виде обратного индекса. Каждый сегмент содержит postings list – список документов для каждого терма, что ускоряет поиск и ранжирование.
Поисковый движок обрабатывает запросы, сопоставляет их с индексом и формирует результаты с учетом алгоритмов TF-IDF или BM25. Модуль ранжирования учитывает частоту термов в документах и их распространенность по всему индексу, что повышает релевантность выдачи.
Анализаторы текста выполняют токенизацию, стемминг и фильтрацию стоп-слов. Правильный выбор анализатора зависит от языка документа и целей поиска: для английского текста часто используют StandardAnalyzer, для русского – SnowballAnalyzer с поддержкой морфологии. Анализаторы влияют на точность индексации и поиск по фразам.
Дополнительно Lucene содержит модуль управления сегментами, который обрабатывает слияние, обновление и удаление документов. Это позволяет поддерживать индекс в актуальном состоянии без полной пересборки и уменьшает нагрузку на диск и оперативную память при больших объемах данных.
Процесс создания индекса для текстовых данных

Создание индекса в Lucene начинается с подготовки документов. Каждый документ представляет собой набор полей, содержащих текст, числовые значения или метаданные. Для текстовых полей применяется анализатор, который разделяет текст на токены, выполняет приведение к нижнему регистру, стемминг и удаление стоп-слов. Этот этап критичен для корректной работы поиска по словоформам и фразам.
После анализа каждого документа Lucene формирует сегменты, содержащие обратный индекс. Обратный индекс связывает каждый терм с идентификаторами документов и их позициями, что обеспечивает быстрый поиск. Рекомендуется структурировать поля с учетом типов запросов: например, отдельные поля для заголовков, основного текста и тегов позволяют точнее ранжировать результаты.
Индексация поддерживает пакетное добавление документов для ускорения обработки больших объемов данных. Использование IndexWriter с параметрами буферизации и слияния сегментов снижает нагрузку на диск и улучшает скорость создания индекса. После завершения добавления документов выполняется commit, фиксирующий изменения в индексе и делая их доступными для поисковых запросов.
Для больших коллекций рекомендуется периодически проводить оптимизацию индекса – слияние мелких сегментов в более крупные. Это уменьшает количество операций чтения при поиске и сокращает время отклика, особенно при интенсивных запросах и динамическом обновлении данных.
Структура обратного индекса и хранение документов
Обратный индекс в Lucene строится на основе термов, каждому из которых соответствует список документов, где он встречается, и позиции в тексте. Такая структура позволяет мгновенно находить документы по отдельным словам и их комбинациям, а также выполнять поиск по фразам и близости слов.
Документы хранятся в сегментах, которые представляют собой независимые части индекса. Каждый сегмент содержит postings list для термов, метаданные полей и информацию о позиции токенов. Сегменты неизменяемы после записи, что упрощает многопоточный доступ и повышает стабильность индекса.
Для оптимизации поиска Lucene использует компрессию и кодирование списков документов и частот термов. Это снижает объем занимаемого диска и ускоряет чтение данных. Рекомендуется правильно разделять поля документов и указывать тип хранения: stored для извлекаемых значений и indexed для поиска, чтобы избежать избыточного расхода памяти.
Слияние сегментов выполняется автоматически при добавлении новых документов. Этот процесс уменьшает количество обращений к диску при поиске и улучшает производительность при больших индексах. Для крупных коллекций рекомендуется настраивать параметры слияния с учетом частоты обновлений и размера сегментов.
Обработка поисковых запросов и алгоритмы ранжирования

Lucene обрабатывает поисковые запросы через построение Query-объектов, которые анализируются с помощью того же анализатора, что использовался при индексировании. Это позволяет корректно сопоставлять формы слов и учитывать токенизацию фраз.
Основные этапы обработки запроса:
- Токенизация и нормализация входного текста;
- Построение логической структуры запроса с операторами AND, OR, NOT;
- Сопоставление термов с postings list обратного индекса;
- Формирование промежуточного списка документов, подходящих под запрос;
- Ранжирование и сортировка результатов.
Для оценки релевантности Lucene применяет алгоритмы:
- TF-IDF – учитывает частоту терма в документе (TF) и обратную частоту терма в индексе (IDF), выделяя документы, где слова встречаются чаще и реже в других документах;
- BM25 – более современный алгоритм, учитывающий длину документа и нормализацию частоты термов, повышающий точность ранжирования для длинных текстов;
- Дополнительные бусты для отдельных полей или типов документов, которые позволяют приоритетизировать заголовки, теги или авторитетные источники.
Для сложных сценариев поиска Lucene поддерживает комбинированные запросы, фильтры по диапазонам числовых полей и дат, а также фасетный поиск, что позволяет гибко управлять выдачей и учитывать пользовательские критерии без повторного индексирования.
Использование фильтров и анализаторов текста

Анализаторы текста в Lucene преобразуют исходный контент в токены и нормализуют их для индексации и поиска. Каждый анализатор состоит из цепочки токенизаторов и фильтров, которые могут выполнять:
- разделение текста на слова и фразы;
- приведение к нижнему регистру и удаление пунктуации;
- стемминг для сокращения слов к корневой форме;
- удаление стоп-слов, не влияющих на релевантность;
- нормализацию специальных символов и диакритики.
Фильтры позволяют настраивать обработку текста под конкретные задачи. Например, LengthFilter удаляет слишком короткие или длинные токены, а SynonymFilter расширяет поиск за счет синонимов. Правильная комбинация фильтров повышает точность поиска и снижает количество нерелевантных результатов.
При работе с разными языками рекомендуется использовать анализаторы, поддерживающие морфологию и особенности конкретного языка. Для русского текста подходит SnowballAnalyzer с поддержкой стемминга, для английского – StandardAnalyzer. Важно сохранять одинаковую конфигурацию анализатора при индексировании и поиске, чтобы термы корректно сопоставлялись.
Фильтры также применяются для динамических запросов, например, для удаления чувствительных слов или привязки к определенным категориям документов. Это позволяет адаптировать поиск под изменяющиеся требования без пересборки индекса.
Обновление, удаление и поддержка индекса

Lucene использует сегментированную структуру индекса, что позволяет обновлять и удалять документы без полной пересборки. Каждый сегмент неизменяем после записи, поэтому операции обновления фактически выполняются как удаление старой версии и добавление новой.
Основные методы поддержки индекса:
- Добавление документов через IndexWriter с буферизацией и commit для фиксации изменений;
- Удаление документов по уникальному идентификатору или запросу через IndexWriter.deleteDocuments;
- Обновление документов как комбинация удаления и повторного добавления с новым содержимым;
- Слияние сегментов, выполняемое автоматически или вручную для уменьшения числа сегментов и ускорения поиска;
- Оптимизация хранения путем удаления пустых сегментов и очистки удаленных документов для экономии дискового пространства.
При динамических данных рекомендуется контролировать частоту commit и параметры слияния, чтобы балансировать скорость индексации и доступность результатов. Для больших коллекций эффективным является использование пакетного обновления документов и периодической оптимизации сегментов.
Примеры внедрения Lucene в реальные приложения
Apache Lucene используется в проектах, где требуется полнотекстовый поиск и высокая производительность при обработке больших объемов данных. Примеры внедрения включают корпоративные системы, веб-поиск и специализированные приложения для анализа документов.
Ниже представлены конкретные сценарии применения Lucene:
| Приложение | Описание внедрения | Рекомендации по использованию |
|---|---|---|
| Elasticsearch | Использует Lucene как движок для индексации и поиска данных, поддерживает масштабирование и кластеризацию. | Рекомендуется настраивать анализаторы и маппинги полей для ускорения поиска и повышения точности результатов. |
| Apache Solr | Обеспечивает веб-поиск и интеграцию с базами данных, поддерживает фильтры, фасеты и автозаполнение. | Использовать Lucene-индексы с правильно настроенными фильтрами и boost для отдельных полей. |
| Корпоративные системы документооборота | Индексация внутренних документов, электронных писем и отчетов для быстрого поиска и аналитики. | Разделять документы на поля: заголовки, содержание, метаданные для точного ранжирования результатов. |
| Поиск по сайту | Интеграция Lucene для реализации поиска по страницам, блогам и форумам с поддержкой фразового поиска и подсветки результатов. | Использовать кэширование запросов и периодическое обновление индекса для ускорения отклика. |
| Научные и юридические базы данных | Индексация статей, патентов и правовых документов с поддержкой сложных запросов и фильтров по категориям. | Применять специализированные анализаторы и синонимические фильтры для повышения релевантности. |
Вопрос-ответ:
Что такое Apache Lucene и для чего он используется?
Apache Lucene — это библиотека на Java для полнотекстового поиска. Она позволяет создавать индекс для текстовых данных и быстро находить нужные документы по ключевым словам, фразам или их комбинациям. Lucene применяют в поисковых системах, корпоративных порталах и приложениях с большими объемами текстовой информации.
Как работает обратный индекс в Lucene?
Обратный индекс строится так, что каждому слову сопоставляется список документов, где оно встречается, с указанием позиций. Это позволяет быстро находить все документы, содержащие заданный термин, и поддерживать поиск по фразам. Такая структура уменьшает количество операций чтения и ускоряет выдачу результатов.
Какие алгоритмы ранжирования использует Lucene?
Lucene применяет TF-IDF и BM25 для оценки релевантности документов. TF-IDF учитывает частоту слова в документе и редкость его в индексе. BM25 дополнительно нормализует длину документа и уменьшает влияние слишком частых слов, что повышает точность выдачи при длинных текстах или больших коллекциях данных.
Как настроить анализаторы и фильтры для поиска на русском языке?
Для русского текста часто используют SnowballAnalyzer или аналогичные, поддерживающие стемминг и морфологию. Фильтры помогают удалять стоп-слова, приводить слова к единой форме и обрабатывать синонимы. Важно, чтобы анализатор при индексировании совпадал с анализатором при поиске, иначе термы не будут корректно сопоставляться.
Можно ли обновлять и удалять документы в индексе Lucene без полной пересборки?
Да, Lucene поддерживает удаление и обновление документов через IndexWriter. Обновление выполняется как удаление старой версии и добавление новой. Сегменты неизменяемы после записи, поэтому изменения фиксируются через commit, а слияние сегментов уменьшает количество мелких сегментов и повышает скорость поиска.
Как Lucene обеспечивает быстрый поиск по большим коллекциям текстовых данных?
Lucene использует обратный индекс, где каждому слову сопоставлен список документов и позиции, в которых оно встречается. Это позволяет находить нужные документы без полного сканирования всех файлов. При добавлении новых документов создаются сегменты, а старые остаются неизменными, что обеспечивает стабильный доступ к данным. Алгоритмы ранжирования, такие как TF-IDF и BM25, помогают сортировать результаты по релевантности, а анализаторы и фильтры нормализуют текст, учитывая морфологию и стоп-слова. Такой подход позволяет масштабировать поиск на десятки и сотни гигабайт текстов и получать ответы за миллисекунды даже при сложных запросах.