Содержание статьи

Создание базы данных в SQL начинается с выбора подходящей системы управления базами данных (СУБД). Разные СУБД поддерживают различные типы данных, ограничения и индексы, поэтому важно заранее определить требования проекта и совместимость с выбранной платформой.
После выбора СУБД следующим шагом является проектирование структуры базы данных. Каждая таблица должна иметь четко определенные поля с соответствующими типами данных, чтобы минимизировать ошибки при вводе и обеспечить правильное хранение информации. Первичный ключ помогает идентифицировать записи уникально и ускоряет поиск данных.
Настройка связей между таблицами с помощью внешних ключей обеспечивает целостность данных. Это позволяет создавать запросы, объединяющие информацию из нескольких таблиц, и предотвращает случайное удаление или изменение связанных записей.
Важным этапом является тестирование структуры базы данных. Вставка контрольных записей и проверка индексов позволяет убедиться, что запросы возвращают корректные результаты, а ограничения работают правильно, предотвращая дублирование и нарушение связей.
Выбор типа базы данных и СУБД для проекта
Перед созданием базы данных необходимо определить тип хранения информации: реляционный или нереляционный. Реляционные базы данных используют таблицы с четкой структурой и поддерживают SQL-запросы, а нереляционные (NoSQL) подходят для гибкой схемы и больших объемов данных без жесткой структуры.
Выбор СУБД зависит от требований проекта по скорости, масштабируемости и совместимости. Популярные реляционные СУБД включают:
| СУБД | Особенности | Применение |
|---|---|---|
| MySQL | Открытый исходный код, поддержка транзакций, репликация | Веб-приложения, малые и средние проекты |
| PostgreSQL | Расширяемость, сложные запросы, поддержка JSON и индексов | Проекты с аналитикой, финансовые системы |
| Microsoft SQL Server | Интеграция с Windows, инструменты BI, высокие требования к лицензированию | Корпоративные решения, системы управления данными |
| Oracle Database | Поддержка больших объемов данных, надежность, масштабируемость | Крупные корпоративные системы, критические приложения |
Для нереляционных баз данных можно использовать MongoDB, Redis или Cassandra. Они подходят для хранения JSON-документов, кэшей и данных с высокой скоростью записи.
При выборе СУБД важно учитывать требования к резервному копированию, восстановлению, типам индексов и поддержке транзакций. Составление таблицы сравнения СУБД по этим параметрам поможет принять обоснованное решение и избежать проблем при дальнейшем масштабировании проекта.
Создание новой базы данных с указанием кодировки и настроек
Создание базы данных начинается с указания имени и выбора кодировки символов. Для проектов с русскоязычными данными рекомендуется использовать UTF-8, чтобы обеспечить корректное хранение и отображение текстовой информации.
В SQL синтаксис для создания базы данных включает ключевое слово CREATE DATABASE с параметрами кодировки и сопутствующих настроек. Например, MySQL позволяет задать кодировку через CHARACTER SET и правила сортировки через COLLATE.
Дополнительно можно указать параметры хранения и расположения файлов данных и журналов транзакций. В PostgreSQL используются параметры TABLESPACE для определения физического местоположения таблиц, а в SQL Server – ON PRIMARY для указания файловой группы.
После создания базы данных важно проверить примененные настройки с помощью системных запросов. В MySQL команда SHOW CREATE DATABASE позволяет убедиться в корректной кодировке и правилах сортировки. В PostgreSQL используется \l+ для отображения списка баз с их характеристиками.
Настройка базы данных на этом этапе определяет корректность хранения информации, совместимость с приложениями и упрощает дальнейшее проектирование таблиц и индексов.
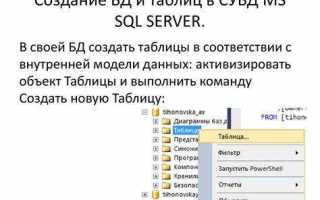
Проектирование структуры таблиц и определение ключей
Проектирование таблиц начинается с определения сущностей и их атрибутов. Каждая таблица должна содержать столбцы с конкретными типами данных: INT для чисел, VARCHAR для текста, DATE для дат. Это позволяет экономить место и ускоряет выполнение запросов.
Первичный ключ (PRIMARY KEY) назначается столбцу или группе столбцов для уникальной идентификации записей. Чаще всего используется автоинкрементное целое число, но допустимо применять комбинацию значимых полей для сложных ключей.
Для столбцов, которые ссылаются на другие таблицы, задаются внешние ключи (FOREIGN KEY). Это обеспечивает целостность данных: записи нельзя удалить или изменить без учета связанных значений. Важно продумать каскадное удаление и обновление через параметры ON DELETE и ON UPDATE.
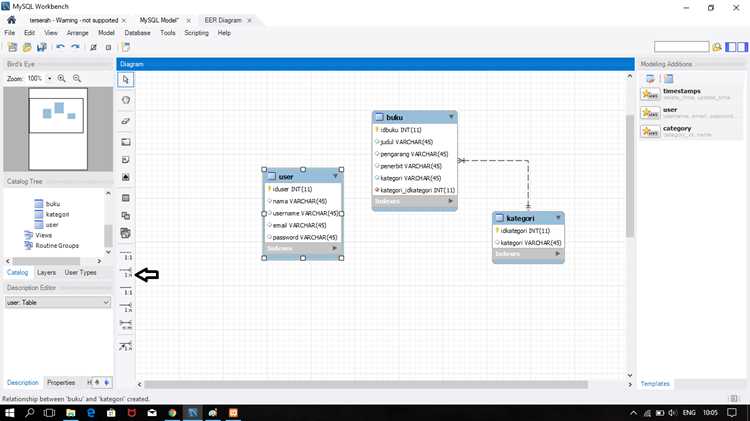
Перед созданием таблиц рекомендуется составить схему в виде диаграммы, обозначив связи между сущностями, типы данных и ключи. Такой подход облегчает корректировку структуры и предотвращает дублирование или потерю информации при масштабировании базы данных.
Добавление столбцов и указание типов данных
При создании таблицы каждый столбец следует определить с точным типом данных. INT и BIGINT подходят для числовых идентификаторов, DECIMAL или NUMERIC – для финансовых значений, VARCHAR(n) – для текстовой информации ограниченной длины, TEXT – для длинных текстов, а DATE и TIMESTAMP – для хранения дат и времени.
Для корректного хранения и поиска данных важно учитывать размер и ограничения столбцов. Например, VARCHAR(50) экономит пространство по сравнению с VARCHAR(255), а NOT NULL предотвращает появление пустых значений в критически важных полях.
Добавление столбцов после создания таблицы выполняется командой ALTER TABLE. При этом можно сразу задать тип данных и ограничения. Например, ALTER TABLE users ADD COLUMN email VARCHAR(100) NOT NULL UNIQUE позволяет создать столбец для уникальных адресов электронной почты.
Выбор подходящего типа данных напрямую влияет на производительность запросов, точность вычислений и требования к памяти. Рекомендуется заранее планировать структуру столбцов и их ограничения перед заполнением таблицы данными.
Настройка связей между таблицами через внешние ключи
Внешние ключи (FOREIGN KEY) обеспечивают целостность данных и определяют связи между таблицами. Они связывают столбец одной таблицы с первичным ключом другой таблицы, предотвращая нарушение логической структуры данных.
Основные правила настройки внешних ключей:
- Столбец внешнего ключа должен соответствовать типу данных первичного ключа связанной таблицы.
- Назначение ON DELETE и ON UPDATE определяет поведение при удалении или изменении связанных записей. Доступны опции: CASCADE, SET NULL, RESTRICT, NO ACTION.
- Внешний ключ может ссылаться на составной первичный ключ, если требуется уникальная комбинация нескольких столбцов.
Пример создания внешнего ключа:
- Создание таблицы родителя: CREATE TABLE departments (id INT PRIMARY KEY, name VARCHAR(50))
- Создание таблицы дочерней и назначение внешнего ключа: CREATE TABLE employees (id INT PRIMARY KEY, name VARCHAR(50), department_id INT, FOREIGN KEY (department_id) REFERENCES departments(id) ON DELETE CASCADE)
Использование внешних ключей позволяет строить запросы с JOIN, объединяя данные из разных таблиц без нарушения целостности. Это облегчает масштабирование базы данных и предотвращает появление несогласованных записей.
Вставка и проверка первых записей в таблицы
После создания таблиц необходимо заполнить их первыми записями для проверки структуры и связей. Используется команда INSERT INTO, указывающая целевую таблицу, список столбцов и значения.
Рекомендации по вставке данных:
- Вставляйте контрольные записи для всех таблиц, чтобы проверить работу внешних ключей.
- Используйте явное указание столбцов: INSERT INTO employees (id, name, department_id) VALUES (1, ‘Иванов’, 10), чтобы избежать ошибок при изменении структуры таблицы.
- Для массовой вставки можно применять несколько значений через запятую.
Проверка корректности записей выполняется с помощью команды SELECT:
- Просмотр всех данных: SELECT * FROM employees
- Фильтрация по условиям: SELECT name FROM employees WHERE department_id = 10
- Проверка связей через JOIN: SELECT e.name, d.name FROM employees e JOIN departments d ON e.department_id = d.id
Регулярная проверка после вставки записей позволяет убедиться, что типы данных и ограничения работают правильно, а внешние ключи поддерживают целостность между таблицами.
Создание индексов и ограничений для контроля данных
Индексы ускоряют выполнение запросов, позволяя СУБД быстро находить записи. Создаются с помощью команды CREATE INDEX и могут быть одно- или многоколонными. Например, CREATE INDEX idx_employee_name ON employees(name) ускоряет поиск сотрудников по имени.
Ограничения (CONSTRAINTS) обеспечивают контроль корректности данных. Основные типы ограничений:
- PRIMARY KEY – уникальная идентификация записей.
- UNIQUE – предотвращает дублирование значений в столбце.
- NOT NULL – запрещает пустые значения.
- CHECK – задает условие для допустимых значений, например, CHECK (salary >= 0).
- FOREIGN KEY – поддерживает целостность данных между таблицами.
Правильное применение индексов и ограничений снижает вероятность ошибок при вводе данных, ускоряет запросы и облегчает масштабирование базы. Рекомендуется индексировать столбцы, используемые в условиях WHERE и JOIN, а ограничения применять к критически важным полям.
Вопрос-ответ:
Как выбрать подходящую СУБД для проекта?
Выбор СУБД зависит от объема данных, структуры информации и требуемой производительности. Реляционные СУБД, такие как MySQL или PostgreSQL, подходят для таблиц с четкой схемой и поддержкой SQL-запросов. Если данные неструктурированные или изменяются часто, можно использовать NoSQL решения вроде MongoDB. При выборе учитывают возможности резервного копирования, индексов и поддержки транзакций.
Как определить структуру таблиц перед созданием базы данных?
Структура таблиц формируется на основе сущностей и их атрибутов. Каждая таблица должна иметь уникальный идентификатор (PRIMARY KEY), а столбцы должны быть назначены с конкретными типами данных. Рекомендуется заранее спроектировать связи между таблицами через внешние ключи и предусмотреть ограничения для контроля значений.
Какие ошибки чаще всего возникают при вставке первых записей?
Основные ошибки включают нарушение ограничений NOT NULL и FOREIGN KEY, несоответствие типов данных и дублирование уникальных значений. Чтобы избежать проблем, рекомендуется указывать столбцы при вставке, проверять корректность связей и выполнять выборку через SELECT для контроля результатов.
Зачем создавать индексы и ограничения в таблицах?
Индексы ускоряют поиск и сортировку данных, особенно по столбцам, используемым в фильтрах и соединениях. Ограничения контролируют ввод данных: UNIQUE исключает дубли, CHECK задает допустимые значения, FOREIGN KEY поддерживает целостность между таблицами. Их правильное использование уменьшает количество ошибок и упрощает обработку больших объемов информации.