Python предоставляет несколько библиотек для загрузки изображений с веб-страниц. Наиболее популярными являются requests для получения HTML-кода и файлов, а также BeautifulSoup для анализа структуры страницы и извлечения ссылок на изображения. Использование этих инструментов позволяет автоматически получать медиафайлы без ручного копирования ссылок.
Для точного скачивания изображения важно проверять его URL и расширение файла. Большинство современных сайтов используют форматы .jpg, .png и .webp. При работе с динамическими страницами можно дополнительно использовать Selenium, чтобы дождаться полной загрузки контента перед извлечением ссылок.
Сохранение изображений требует указания корректного пути на локальном компьютере. Для этого в Python применяются функции open() и os.path, которые позволяют создавать папки, проверять существование файлов и предотвращать перезапись. Такой подход помогает структурировать коллекцию скачанных изображений и ускоряет последующую работу с ними.
При массовой загрузке изображений важно учитывать ограничения сайта, чтобы не нарушать его правила. Рекомендуется использовать таймеры между запросами и проверку статуса ответа сервера, чтобы исключить скачивание пустых или поврежденных файлов. Такой подход повышает надежность скриптов и предотвращает блокировки со стороны сайта.
Установка необходимых библиотек для загрузки изображений
Для скачивания изображений с веб-сайтов в Python чаще всего используют requests и BeautifulSoup. Установку выполняют через pip: pip install requests beautifulsoup4. Это обеспечивает возможность получать HTML-код страницы и извлекать ссылки на медиафайлы.
Если планируется работа с динамическими страницами, где контент подгружается через JavaScript, дополнительно потребуется Selenium и драйвер для браузера, например, ChromeDriver. Установка выполняется командой pip install selenium, после чего нужно указать путь к драйверу в скрипте.
Для удобного сохранения и обработки изображений можно использовать Pillow. Она позволяет не только сохранять файлы, но и конвертировать форматы и изменять размеры. Установка выполняется через pip install pillow.
Рекомендуется создавать виртуальное окружение для проекта через python -m venv env и активировать его перед установкой библиотек. Это предотвращает конфликты версий и сохраняет зависимости проекта локальными.
Получение HTML-кода страницы с помощью requests
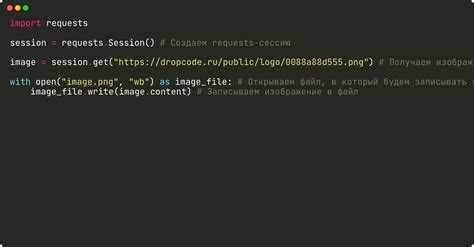
Библиотека requests позволяет получать HTML-код веб-страницы простым HTTP-запросом. Для этого используется функция requests.get(url), где url – адрес страницы. Ответ хранится в объекте Response, а HTML доступен через атрибут text.
Для корректного получения кода с сайтов, требующих заголовки, можно указать User-Agent в параметре headers. Например, таблица ниже показывает базовый пример настройки запроса:
| Параметр | Описание | Пример |
|---|---|---|
| url | Адрес страницы для запроса | https://example.com |
| headers | HTTP-заголовки, которые сервер ожидает | {‘User-Agent’: ‘Mozilla/5.0’} |
| timeout | Время ожидания ответа сервера в секундах | 10 |
После выполнения запроса следует проверять статус-код ответа через response.status_code. Значение 200 означает успешное получение HTML. Любые коды 4xx или 5xx требуют обработки ошибок или повторного запроса.
Для больших страниц рекомендуется сохранять HTML в файл с помощью open(), чтобы не перегружать оперативную память при последующем анализе содержимого.
Извлечение ссылок на изображения через BeautifulSoup
Для извлечения ссылок на изображения используют BeautifulSoup. После получения HTML создают объект soup = BeautifulSoup(html, ‘html.parser’). Все теги изображений находятся через soup.find_all(‘img’), а URL извлекается из атрибута src.
Если ссылка относительная, её объединяют с доменом сайта через urllib.parse.urljoin(base_url, src). Это гарантирует корректное формирование полного URL для скачивания.
Для фильтрации изображений по формату используют проверку расширения: .jpg, .png, .webp. Такой подход предотвращает скачивание ненужных файлов и упрощает последующую обработку.
На современных сайтах часто применяются атрибуты data-src или data-lazy для отложенной загрузки. В скрипте следует проверять эти поля и использовать их при отсутствии данных в src, чтобы извлечь все актуальные изображения.
Скачивание изображения по URL с помощью urllib

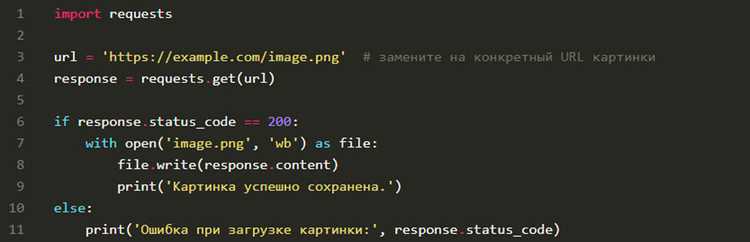
Для загрузки изображений с конкретного URL в Python используют модуль urllib.request. Основная функция – urllib.request.urlretrieve(url, filename), где url – адрес изображения, а filename – путь для сохранения на локальном диске.
При работе с несколькими изображениями рекомендуется формировать уникальные имена файлов, например, добавляя порядковый номер или хэш из URL. Это предотвращает перезапись уже сохранённых файлов.
Для сайтов с ограничениями на частоту запросов полезно использовать таймеры через time.sleep(), чтобы сделать паузы между скачиваниями и снизить риск блокировки.
Перед сохранением изображения проверяют его размер и статус-код ответа сервера через urllib.request.urlopen(url).getcode(). Код 200 подтверждает корректность ссылки, а меньшие размеры файлов или ошибки 4xx/5xx указывают на недоступность изображения.
Сохранение изображения в нужной папке на компьютере
Для организации скачанных изображений рекомендуется создавать отдельные папки с помощью модуля os. Функция os.makedirs(path, exist_ok=True) создаёт директорию и поддиректории, если они ещё не существуют.
Рекомендуемые шаги при сохранении изображений:
- Определить базовую папку для хранения, например images/.
- Создать подкатегории по сайту или дате скачивания для упрощения поиска.
- Формировать уникальные имена файлов, используя порядковые номера или часть URL.
- Использовать полный путь при записи файла через open(path, ‘wb’) для бинарного сохранения.
Пример последовательности действий:
- Проверка существования папки через os.path.exists().
- Создание директории при отсутствии.
- Открытие файла в бинарном режиме ‘wb’.
- Запись содержимого изображения из переменной response.content или файла, полученного через urllib.
Такой подход обеспечивает структурированное хранение изображений, предотвращает перезапись и упрощает автоматизированную обработку скачанных файлов.
Обработка ошибок при загрузке изображений
При скачивании изображений важно проверять статус ответа сервера. В requests это response.status_code, а в urllib – исключения URLError и HTTPError. Код 200 подтверждает успешное получение, 4xx и 5xx указывают на ошибки.
Рекомендуется использовать конструкцию try…except для перехвата ошибок:
- Поймать ConnectionError при проблемах с сетью.
- Перехватывать Timeout для длительных задержек сервера.
- Обрабатывать HTTPError для некорректных URL или ограничений сайта.
Для повторных попыток загрузки используют циклы с ограничением числа попыток и задержками через time.sleep(). Это снижает вероятность блокировки и увеличивает шанс успешного скачивания.
При массовой загрузке изображений полезно вести лог ошибок в отдельный файл, фиксируя URL и тип ошибки. Такая практика помогает быстро выявлять недоступные или повреждённые файлы без прерывания работы скрипта.
Автоматизация скачивания нескольких изображений с сайта
Для автоматического скачивания нескольких изображений используют циклы по списку ссылок, полученных через BeautifulSoup или заранее подготовленный массив URL. Каждый URL проверяют на корректность и формат перед загрузкой.
Примерная последовательность действий:
- Создать список ссылок на изображения.
- Перебирать ссылки в цикле for.
- Скачивать изображение через urllib.request.urlretrieve() или requests.get() с записью в файл.
- Формировать уникальные имена файлов для предотвращения перезаписи.
- Обрабатывать ошибки через try…except, фиксируя неудачные загрузки в лог.
- Добавлять паузы time.sleep() между запросами, чтобы избежать блокировки со стороны сайта.
Для больших сайтов полезно комбинировать цикл с проверкой существования файла через os.path.exists(). Это позволяет возобновлять процесс скачивания без повторной загрузки уже сохранённых изображений.
Вопрос-ответ:
Как установить библиотеки для скачивания изображений с сайта?
Для работы с изображениями в Python понадобятся requests и BeautifulSoup. Их можно установить через команду pip install requests beautifulsoup4. Если планируется работа с динамическими страницами, где контент подгружается через JavaScript, дополнительно потребуется Selenium и соответствующий драйвер браузера, например ChromeDriver. Для обработки изображений и изменения формата используют Pillow, которая устанавливается командой pip install pillow. Создание виртуального окружения через python -m venv env поможет избежать конфликтов между библиотеками.
Как получить HTML-код страницы для дальнейшего поиска изображений?
Для загрузки HTML используют библиотеку requests. Простейший способ — выполнить response = requests.get(url), где url — адрес страницы. HTML содержится в response.text. Если сайт проверяет заголовки, стоит указать User-Agent через headers, например {‘User-Agent’: ‘Mozilla/5.0’}. Проверка response.status_code позволяет убедиться, что запрос успешен (код 200), а ошибки 4xx или 5xx требуют дополнительной обработки.
Каким образом извлечь все ссылки на изображения с веб-страницы?
После получения HTML создают объект BeautifulSoup: soup = BeautifulSoup(html, ‘html.parser’). Для поиска всех изображений используют soup.find_all(‘img’). URL берут из атрибута src. Если ссылка относительная, её объединяют с доменом сайта через urllib.parse.urljoin(base_url, src). На некоторых сайтах изображения подгружаются через data-src или data-lazy, поэтому стоит проверять эти атрибуты. Для фильтрации применяют проверку расширений: .jpg, .png, .webp.
Как безопасно скачать изображение по URL и сохранить его на компьютере?
Для скачивания используют urllib.request.urlretrieve(url, filename) или requests.get(url) с записью содержимого в бинарный файл open(filename, ‘wb’). Файлы лучше сохранять в отдельной папке, создаваемой через os.makedirs(path, exist_ok=True). Для предотвращения перезаписи формируют уникальные имена файлов, добавляя порядковые номера или часть URL. Перед сохранением полезно проверять статус-код ответа сервера и размер файла, чтобы исключить пустые или поврежденные изображения.
Как организовать автоматическое скачивание нескольких изображений с сайта?
Создайте список ссылок на изображения и перебирайте его в цикле for. Каждое изображение скачивают через urllib или requests, сохраняют с уникальным именем и фиксируют ошибки через try…except. Для снижения нагрузки на сервер и предотвращения блокировок между запросами используют time.sleep(). Проверка существования файла через os.path.exists() позволяет возобновлять загрузку без повторного скачивания уже сохранённых изображений. Логи ошибок помогают анализировать недоступные или повреждённые файлы.
Как правильно обрабатывать ошибки при массовой загрузке изображений с сайта?
При загрузке большого количества изображений важно предусмотреть возможные ошибки сети и ограничения сервера. В Python используют конструкцию try…except для перехвата исключений, таких как ConnectionError, Timeout и HTTPError. Рекомендуется проверять статус-код ответа сервера перед сохранением файла: код 200 подтверждает успешное получение, 4xx и 5xx сигнализируют о проблемах. Для повторных попыток загрузки можно использовать цикл с ограничением числа попыток и задержками через time.sleep(). Если скачивание нескольких файлов идёт последовательно, полезно вести лог ошибок с указанием URL и типа ошибки. Это помогает выявлять недоступные изображения без прерывания работы скрипта и ускоряет исправление проблем при повторной загрузке.