Содержание статьи

Механизм опрашивателя querier применяется в системах, где требуется регулярное извлечение и обработка данных из разных источников без участия пользователя. Он выполняет роль промежуточного слоя, который формирует, отправляет и анализирует запросы, обеспечивая согласованность информации между сервисами и базами данных.
Чаще всего querier используется в платформах мониторинга, системах аналитики и сервисах сбора метрик. Его задача – быстро обрабатывать большое количество запросов и предоставлять агрегированные результаты, что особенно важно для инфраструктур, построенных на микросервисах или распределённых базах данных.
Настройка querier позволяет точно контролировать частоту опросов, типы запросов и формат ответов. Это даёт возможность балансировать нагрузку на систему и повышать точность получаемых данных без избыточных обращений к источникам. В крупных инфраструктурах этот механизм становится ключевым инструментом для поддержки стабильной работы сервисов и своевременного реагирования на изменения в данных.
Какую задачу решает механизм querier в архитектуре системы
Механизм querier решает задачу согласованного и управляемого получения данных из распределённых или разнородных источников. Он выступает посредником между компонентами системы, снимая нагрузку с основных сервисов и упрощая логику работы с хранилищами данных.
В архитектуре система с querier получает единый интерфейс для запросов, что устраняет необходимость прямого обращения приложений к каждой базе или сервису. Это снижает риск несоответствия форматов данных и повышает предсказуемость ответов при изменении инфраструктуры.
Использование querier особенно оправдано при работе с метриками, логами и временными рядами. Он агрегирует результаты, выполняет фильтрацию и предобработку перед передачей в модули визуализации или аналитики. Такая схема повышает стабильность обмена данными и позволяет масштабировать запросы без изменения клиентской логики.
При проектировании архитектуры рекомендуется выделять querier в отдельный компонент, чтобы разграничить ответственность между сбором, обработкой и хранением данных. Это облегчает отладку и делает систему более устойчивой к перегрузкам и сбоям отдельных узлов.
Принцип работы querier при обращении к источникам данных
Механизм querier функционирует как координирующий компонент, который формирует запросы к источникам данных и управляет процессом их выполнения. Он получает инструкции от пользовательских или сервисных модулей, преобразует их в формат, совместимый с конкретным типом хранилища, и обеспечивает корректную маршрутизацию запросов.
Работа querier строится на очередности шагов: подготовка запроса, отправка в источник, получение результата, нормализация данных и возврат клиенту. При этом он может применять фильтрацию, сортировку и агрегацию на уровне промежуточной обработки, сокращая объём передаваемой информации и ускоряя отклик системы.
В распределённых средах querier использует механизмы балансировки и параллельного выполнения запросов, чтобы уменьшить задержки при доступе к большим массивам данных. Он также может кэшировать результаты часто повторяющихся запросов, что снижает нагрузку на хранилища и ускоряет обработку.
При настройке рекомендуется учитывать характеристики источников – тип базы данных, поддержку индексов, частоту обновления данных. Точная конфигурация querier позволяет добиться стабильной производительности и равномерного распределения запросов по серверам.
Роль querier в распределённых и микросервисных средах
В распределённых и микросервисных системах querier обеспечивает согласованное получение данных из множества автономных сервисов. Он устраняет необходимость прямого взаимодействия компонентов с разными хранилищами и API, выступая единым посредником для выполнения запросов и агрегирования результатов.
Благодаря querier запросы могут выполняться параллельно на нескольких узлах, что снижает задержки и позволяет получать актуальные данные даже при высокой нагрузке. Этот механизм берёт на себя обработку частичных ошибок и повторные запросы, сохраняя целостность итогового ответа.
В микросервисной архитектуре querier помогает разделить ответственность между слоями данных и прикладной логикой. Он позволяет сервисам работать независимо, передавая им только результаты, необходимые для дальнейшей обработки или визуализации.
Рекомендуется выделять querier в отдельный сервис с контролем прав доступа и возможностью масштабирования по горизонтали. Это повышает устойчивость системы, упрощает балансировку трафика и минимизирует зависимость микросервисов от структуры данных.
Использование querier для оптимизации запросов и снижения нагрузки
Механизм querier снижает нагрузку на систему за счёт рациональной обработки запросов и минимизации обращений к базам данных. Он анализирует шаблоны обращений, объединяет схожие запросы и кэширует результаты, что сокращает количество прямых вызовов к источникам данных.
Оптимизация достигается через распределение запросов по времени, использование предварительно рассчитанных агрегатов и применение фильтров на уровне querier, а не хранилища. Это особенно полезно при работе с метриками и временными рядами, где объём данных может быть значительным.
| Метод оптимизации | Описание | Рекомендация по применению |
|---|---|---|
| Кэширование результатов | Сохраняет ответы на повторяющиеся запросы | Настраивать срок жизни кэша в зависимости от частоты обновления данных |
| Группировка запросов | Объединяет идентичные обращения разных клиентов | Включать при высокой конкуренции запросов к одним таблицам |
| Фильтрация на уровне querier | Отбрасывает лишние данные до запроса в хранилище | Использовать для сокращения трафика между сервисами |
| Планировщик запросов | Распределяет выполнение во времени | Применять для снижения пиковых нагрузок на базы данных |
При правильной конфигурации querier позволяет перераспределить вычислительные ресурсы, повысить стабильность работы сервисов и уменьшить затраты на масштабирование инфраструктуры.
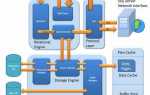
Как querier взаимодействует с кэшем и слоями хранения данных

Механизм querier использует кэш как промежуточный слой между приложением и источниками данных, чтобы сократить количество прямых обращений к хранилищу. При выполнении запроса он сначала проверяет наличие результата в кэше. Если данные найдены, ответ возвращается немедленно, без участия базы данных.
Когда запрашиваемая информация отсутствует в кэше, querier формирует обращение к источнику, получает результат и сохраняет его в кэше с заданным временем жизни. Такой подход снижает задержки при повторных запросах и стабилизирует нагрузку на дисковые системы и сетевые интерфейсы.
В многоуровневых архитектурах querier может взаимодействовать с несколькими слоями хранения: оперативной памятью, временными буферами и долговременными хранилищами. Это позволяет выбирать оптимальный источник данных в зависимости от частоты доступа и актуальности информации.
При настройке рекомендуется чётко разграничивать кэширование метаданных и содержательных данных, чтобы избежать избыточного хранения. Также следует контролировать размер кэша и политику очистки, так как переполнение может привести к снижению производительности и увеличению времени отклика.
Примеры применения querier в системах мониторинга и аналитики

В системах мониторинга querier используется для сбора метрик с серверов, контейнеров и сетевых устройств. Он выполняет периодические запросы к источникам данных, агрегирует результаты и передаёт их в панели визуализации, обеспечивая актуальность показателей нагрузки, доступности и производительности.
В аналитических платформах querier помогает объединять данные из разнородных баз: SQL, NoSQL и временных рядов. Он формирует единый поток информации для построения отчетов и дашбордов, сокращая время обработки и исключая необходимость ручного объединения данных.
Пример конкретного применения – обработка логов веб-сервисов. Querier собирает события, фильтрует по уровню критичности и агрегирует по временным интервалам. Итоговая таблица позволяет оперативно выявлять аномалии и сбои без избыточной нагрузки на хранилище.
При внедрении рекомендуется настраивать частоту опроса и размер пакетов данных с учётом производительности системы и объема информации. Это позволяет сохранить баланс между точностью аналитики и нагрузкой на инфраструктуру.
Ограничения и типичные ошибки при использовании querier

Механизм querier имеет ряд ограничений, которые необходимо учитывать при проектировании систем. Неправильная настройка может привести к увеличению задержек, перегрузке источников данных и искажению результатов.
- Чрезмерная частота опроса. Частые запросы к источникам без учёта нагрузки вызывают деградацию производительности и рост времени отклика.
- Игнорирование кэширования. Отсутствие кэширования повторяющихся запросов увеличивает количество обращений к базам и нагрузку на сеть.
- Неправильная агрегация данных. Суммирование и фильтрация на уровне клиента вместо querier приводит к избыточным объёмам передаваемой информации.
- Неучёт структуры данных источников. Форматы и индексы, не поддерживаемые базой, могут вызвать ошибки или замедление выполнения запросов.
- Отсутствие контроля ошибок. Некорректная обработка недоступных источников приводит к потере данных и нарушению целостности результатов.
Для минимизации проблем рекомендуется:
- Настраивать частоту запросов с учётом возможностей источников данных.
- Внедрять кэширование и использовать предварительно рассчитанные агрегаты.
- Планировать схемы фильтрации и агрегации на уровне querier, а не клиента.
- Проверять совместимость форматов и индексов перед подключением новых источников.
- Реализовать обработку ошибок и повторные попытки выполнения запросов.
Соблюдение этих правил позволяет снизить риски перегрузки и повысить надёжность работы системы при использовании querier.
Вопрос-ответ:
Для чего конкретно используется механизм опрашивателя querier?
Механизм querier предназначен для автоматического получения данных из разных источников, их нормализации и передачи в приложения или аналитические системы. Он позволяет объединять информацию из нескольких баз и сервисов, сокращая необходимость ручного взаимодействия с каждым источником.
Как querier помогает уменьшить нагрузку на базу данных?
Querier применяет кэширование и агрегацию данных на промежуточном уровне, что снижает количество прямых обращений к источнику. Кроме того, он может объединять похожие запросы от разных клиентов и выполнять их пакетно, распределяя нагрузку равномерно во времени.
В каких системах чаще всего используется querier?
Механизм чаще применяется в платформах мониторинга, системах аналитики, сервисах обработки логов и метрик. Он собирает информацию с серверов, сетевых устройств и приложений, преобразует её в удобный формат и передает в панели визуализации или аналитические отчёты.
Как querier взаимодействует с кэшем и различными слоями хранения данных?
При обращении к данным querier сначала проверяет кэш, чтобы использовать уже полученные результаты. Если данных нет, он отправляет запрос в источник, нормализует ответ и сохраняет результат в кэше с заданным временем жизни. В многоуровневых системах querier может обращаться к оперативной памяти, временным буферам и долговременным хранилищам, выбирая оптимальный источник в зависимости от частоты доступа и актуальности информации.
Какие ошибки чаще всего возникают при настройке и использовании querier?
Типичные ошибки включают слишком частые запросы к источникам, отсутствие кэширования, неправильную агрегацию данных, игнорирование особенностей структуры баз и отсутствие обработки ошибок. Эти проблемы приводят к увеличению задержек, перегрузке серверов и потере точности данных.
Каким образом querier упрощает работу с распределёнными данными?
Механизм querier обеспечивает единый интерфейс для доступа к разнородным источникам данных. Он объединяет результаты запросов из разных баз и сервисов, выполняет нормализацию формата и предоставляет агрегированные данные приложениям или аналитическим системам. Это сокращает необходимость прямого взаимодействия с каждым источником и упрощает интеграцию компонентов.
В каких случаях использование querier особенно полезно?
Querier полезен в системах мониторинга, аналитики и обработки больших потоков данных, где требуется частый и регулярный сбор информации из разных источников. Он позволяет кэшировать часто запрашиваемые данные, распределять запросы по времени и выполнять предварительную агрегацию, снижая нагрузку на базу и ускоряя получение результатов.