Содержание статьи

Microsoft SQL Server предоставляет набор инструментов для управления реляционными базами данных, включая создание таблиц, определение связей между ними и настройку ограничений целостности. Система поддерживает T-SQL для выполнения сложных запросов, позволяя быстро фильтровать, группировать и агрегировать данные.
Функции резервного копирования и восстановления позволяют настроить регулярное создание копий баз данных с указанием полного, дифференциального и транзакционного логов. Это обеспечивает защиту данных при сбоях и упрощает восстановление отдельных объектов или всей базы.
Для ускорения обработки запросов SQL Server предлагает индексы различных типов: кластерные, некластерные, полнотекстовые. Планировщик запросов автоматически выбирает оптимальный путь выполнения, что сокращает время отклика даже при работе с миллионами записей.
Система поддерживает транзакции с полной изоляцией, позволяя управлять блокировками и предотвращать конфликты между параллельными операциями. Встроенные функции для обработки строк, чисел и дат упрощают преобразование данных и выполнение вычислений без необходимости писать сложные скрипты.
Мониторинг производительности ведется через динамические представления и журналы событий, что позволяет отслеживать загрузку процессора, использование памяти и активность отдельных запросов. Это дает возможность своевременно оптимизировать базы и предотвращать узкие места в работе системы.
Управление базами данных и создание таблиц

В Microsoft SQL Server создание базы данных начинается с указания имени, местоположения файлов данных и журналов транзакций, а также размеров и настроек автозаполнения. Рекомендуется сразу определять primary filegroup для хранения ключевых таблиц и log file на отдельном диске для ускорения записи транзакций.
При проектировании таблиц важно определять тип данных для каждого столбца, учитывая размер и диапазон значений. Например, использование INT вместо BIGINT для небольших числовых полей снижает нагрузку на хранение и повышает скорость обработки запросов.
Для обеспечения целостности данных следует применять PRIMARY KEY и FOREIGN KEY, а также ограничения UNIQUE и CHECK. Это предотвращает дублирование записей и нарушение логических связей между таблицами.
SQL Server поддерживает создание индексов сразу при создании таблицы, что ускоряет выборку данных по ключевым полям. Для крупных таблиц рекомендуется использовать кластерные индексы на столбцах с часто выполняемыми сортировками и фильтрациями.
Управление базами данных включает регулярный контроль размеров файлов, проверку целостности через DBCC CHECKDB и настройку параметров автосжатия. Эти действия предотвращают рост фрагментации и обеспечивают стабильную работу системы при интенсивной нагрузке.
Настройка резервного копирования и восстановления данных

В Microsoft SQL Server резервное копирование реализуется через полные, дифференциальные и транзакционные логи. Полное резервное копирование сохраняет всю базу данных, дифференциальное – только изменения с момента последнего полного бэкапа, транзакционные логи фиксируют последовательность изменений.
Рекомендуется создавать план резервного копирования с учетом объема данных и времени восстановления. Для крупных баз данных с активными транзакциями лучше комбинировать полный бэкап раз в неделю и дифференциальный – ежедневно, а логи – каждые 15–30 минут.
Для контроля состояния резервных копий удобно использовать таблицу с ключевыми параметрами:
| Тип бэкапа | Частота | Хранилище | Рекомендуемый размер |
|---|---|---|---|
| Полный | Раз в неделю | Локальный диск + сетевое хранилище | 100–500 ГБ (в зависимости от базы) |
| Дифференциальный | Ежедневно | Сетевое хранилище | 5–50 ГБ |
| Транзакционный лог | Каждые 15–30 минут | Локальный SSD | 100–500 МБ на интервал |
Восстановление базы выполняется с использованием последовательного применения полного, дифференциального бэкапа и транзакционных логов. Важно проверять совместимость версий и состояния файлов, чтобы избежать ошибок восстановления.
Оптимизация запросов с помощью индексов и планов выполнения
Microsoft SQL Server использует кластерные и некластерные индексы для ускорения поиска и сортировки данных. Кластерный индекс формирует физический порядок строк таблицы, что ускоряет выборку по ключевым полям. Некластерный индекс создает отдельную структуру с указателями на строки, что полезно для часто используемых фильтров и соединений.
Для анализа производительности запросов применяется Execution Plan. Он показывает порядок операций, используемые индексы и оценочную стоимость выполнения. Рекомендуется проверять планы для запросов с медленной выборкой и заменять полные сканирования таблиц на индексированные операции.
Совет по оптимизации: для колонок, используемых в условиях WHERE и JOIN, создавайте индексы с включением дополнительных столбцов через INCLUDE, чтобы снизить количество обращений к таблице. Также важно регулярно обновлять статистику индексов через UPDATE STATISTICS для корректного выбора плана выполнения.
Использование Covering Index позволяет полностью обслуживать запрос из индекса без обращения к таблице, что сокращает время выполнения при выборках больших объемов данных. Для сложных запросов с агрегациями и подзапросами стоит анализировать альтернативные пути соединений (Nested Loops, Hash Match, Merge Join) в плане выполнения.
При проектировании индексов следует учитывать частоту вставок и обновлений: слишком большое количество индексов замедляет запись данных, поэтому баланс между скоростью чтения и записью критичен для таблиц с высокой нагрузкой.
Реализация транзакций и управление блокировками
В Microsoft SQL Server транзакции обеспечивают согласованность данных при одновременной работе нескольких пользователей. Основные операции транзакции:
- BEGIN TRANSACTION – начало блока операций.
- COMMIT – фиксация изменений в базе данных.
- ROLLBACK – отмена всех изменений с момента начала транзакции.
Уровни изоляции транзакций определяют степень блокировки и возможность чтения непроверенных данных:
- READ UNCOMMITTED – чтение «грязных» данных, минимальные блокировки.
- READ COMMITTED – стандартный уровень, предотвращает чтение незавершенных изменений.
- REPEATABLE READ – блокировка прочитанных строк до завершения транзакции.
- SERIALIZABLE – максимальная изоляция, предотвращает вставку новых строк в диапазон выборки.
- SNAPSHOT – чтение данных в состоянии на момент начала транзакции без блокировок записи.
Для управления блокировками SQL Server применяет автоматическое назначение shared, exclusive и update блокировок. Рекомендуется:
- Минимизировать длительность транзакций, чтобы сократить конкуренцию за ресурсы.
- Использовать индексы для уменьшения количества строк, захватываемых блокировками.
- Контролировать взаимные блокировки (deadlocks) через SQL Server Profiler или динамические представления sys.dm_tran_locks.
Правильная организация транзакций и оптимизация блокировок повышает пропускную способность системы и предотвращает задержки при массовых обновлениях данных.
Использование встроенных функций для обработки данных
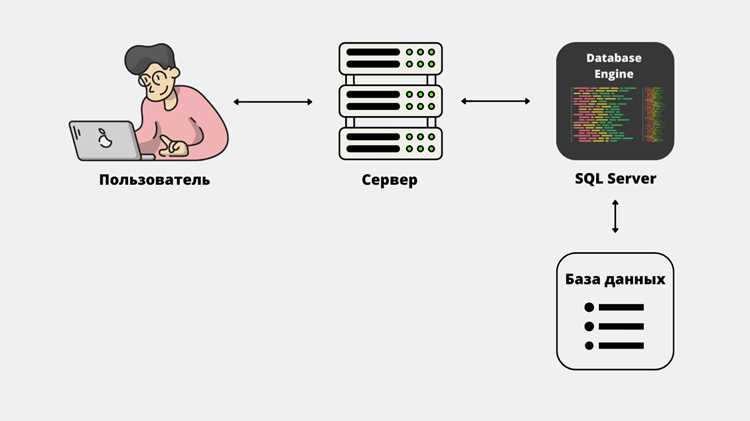
Microsoft SQL Server предоставляет набор встроенных функций для обработки строк, чисел, дат и работы с логикой. Для строковых данных часто используют LEN для определения длины, SUBSTRING для выделения подстрок, REPLACE и STUFF для модификации содержимого.
Для чисел доступны функции округления и преобразования типов: ROUND, CEILING, FLOOR, CAST и CONVERT. Эти функции позволяют контролировать точность расчетов и формат хранения данных.
Работа с датами и временем осуществляется через GETDATE, DATEADD, DATEDIFF, FORMAT и DATEPART, что упрощает вычисление интервалов, формирование отчетов по периодам и преобразование форматов.
Логические и агрегатные функции, такие как ISNULL, COALESCE, SUM, AVG, MIN и MAX, позволяют обрабатывать значения с учетом пропусков и вычислять показатели без необходимости создания дополнительных процедур.
Рекомендуется использовать встроенные функции напрямую в запросах для фильтрации и преобразования данных, что снижает нагрузку на сервер и уменьшает объем кода в пользовательских скриптах.
Мониторинг производительности и ведение журналов событий
Microsoft SQL Server предоставляет встроенные инструменты для мониторинга нагрузки на сервер и анализа работы баз данных. Основные показатели включают CPU usage, memory utilization, количество активных соединений и время ожидания блокировок.
Для анализа запросов и выявления узких мест применяются Dynamic Management Views (DMV), такие как sys.dm_exec_requests для текущих операций и sys.dm_exec_query_stats для статистики выполнения запросов. Эти данные позволяют выявлять медленные запросы и оптимизировать индексы.
Журналы событий ведутся через SQL Server Error Log и Windows Event Log. Рекомендуется настраивать циклическое хранение логов и включать фильтры по типу событий: ошибки, предупреждения, информационные сообщения.
Для постоянного мониторинга используют SQL Server Profiler и Extended Events. Они позволяют отслеживать выполнение конкретных процедур, блокировки, deadlock и длительные транзакции, что помогает своевременно принимать меры по оптимизации.
Регулярный анализ журналов и показателей производительности обеспечивает стабильную работу системы, предотвращает перегрузку ресурсов и позволяет планировать масштабирование базы данных при увеличении нагрузки.
Вопрос-ответ:
Какие типы резервного копирования поддерживает Microsoft SQL Server и когда их лучше использовать?
SQL Server позволяет создавать полные, дифференциальные и транзакционные резервные копии. Полное копирование сохраняет всю базу и подходит для еженедельного бэкапа. Дифференциальное фиксирует изменения с момента последнего полного бэкапа, что удобно для ежедневного восстановления. Транзакционные логи фиксируют последовательность изменений, позволяя восстановить базу до конкретного момента времени при сбое.
Как правильно выбирать тип индекса для ускорения запросов?
Для столбцов, по которым выполняется сортировка или поиск, лучше использовать кластерный индекс — он формирует физический порядок строк в таблице. Некластерные индексы подходят для часто фильтруемых или соединяемых полей, их можно создавать с включением дополнительных столбцов через INCLUDE, чтобы минимизировать обращения к таблице. Перед созданием индекса анализируют планы выполнения запросов и распределение данных.
Что такое уровни изоляции транзакций и как их правильно применять?
Уровни изоляции определяют, какие данные видит транзакция во время выполнения и какие блокировки накладываются. READ UNCOMMITTED позволяет читать незавершённые изменения, READ COMMITTED предотвращает это чтение, REPEATABLE READ фиксирует прочитанные строки до конца транзакции, SERIALIZABLE блокирует диапазоны выборки, а SNAPSHOT предоставляет данные в состоянии на начало транзакции без блокировок. Выбор уровня зависит от необходимости консистентности данных и нагрузки на сервер.
Какие встроенные функции SQL Server полезны для работы с датами и временем?
Для работы с датами и временем используют GETDATE() для получения текущей даты, DATEADD() для добавления интервалов, DATEDIFF() для вычисления разницы между датами, DATEPART() для извлечения части даты, и FORMAT() для преобразования формата. Эти функции упрощают анализ периодов, формирование отчетов и вычисление интервалов между событиями.
Какие инструменты SQL Server помогают отслеживать производительность базы данных?
SQL Server предоставляет Dynamic Management Views, например sys.dm_exec_requests для текущих операций и sys.dm_exec_query_stats для анализа выполнения запросов. Дополнительно можно использовать SQL Server Profiler и Extended Events для отслеживания медленных запросов, блокировок и deadlock. Error Log и Windows Event Log фиксируют ошибки и события, что помогает контролировать нагрузку и планировать оптимизацию.
Как в Microsoft SQL Server настроить план резервного копирования для крупной базы данных с минимизацией времени простоя?
Для крупной базы данных стоит использовать комбинированный подход: полный бэкап раз в неделю, дифференциальный ежедневно и резервное копирование транзакционных логов каждые 15–30 минут. Полный бэкап обеспечивает сохранность всей базы, дифференциальный фиксирует только изменения, а логи позволяют восстановить базу до конкретного момента. Для снижения времени простоя рекомендуется хранить полные бэкапы на сетевом хранилище, а дифференциальные и логи — на быстром локальном SSD. Также полезно использовать сжатие бэкапов и проверять их целостность через RESTORE VERIFYONLY. Планирование с учетом времени наибольшей нагрузки помогает не перегружать сервер во время рабочего периода.