Содержание статьи

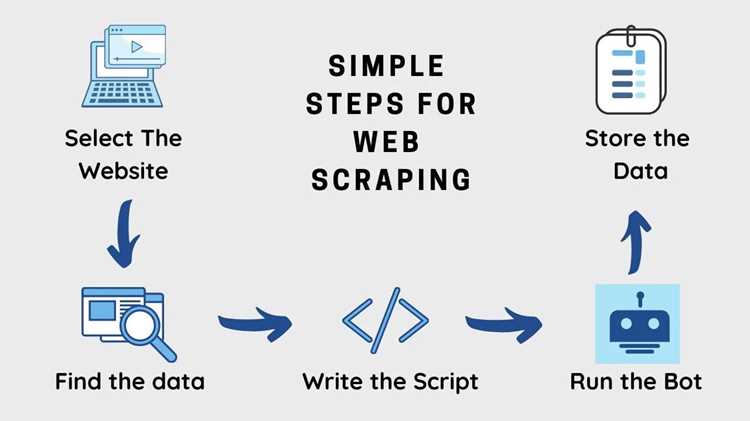
Web scraping позволяет извлекать структурированные данные с веб-страниц без ручного копирования информации. Для начала важно определить целевые сайты и тип данных: таблицы, списки, изображения или текстовые блоки. Четкое понимание структуры страницы ускоряет процесс и снижает вероятность ошибок при парсинге.
Основной инструмент для работы с web scraping в Python – библиотека BeautifulSoup для разбора HTML и requests для выполнения HTTP-запросов. Для динамических сайтов часто используют Selenium или Playwright, чтобы управлять браузером и получать контент, загружаемый через JavaScript.
При сборе данных важно учитывать ограничения сайтов: лимиты на количество запросов, правила использования API и требования к User-Agent. Использование задержек между запросами и смена прокси помогают избежать блокировок и поддерживать стабильный сбор данных.
Собранную информацию удобнее сохранять в формате CSV, JSON или базы данных. Правильная структура хранения облегчает последующую обработку и анализ, а также упрощает автоматизацию регулярного обновления данных.
Выбор инструментов для web scraping
Для web scraping выбор инструментов зависит от структуры сайта и типа данных. Для статических страниц подходит BeautifulSoup в сочетании с requests, что позволяет быстро извлекать текстовые данные, таблицы и списки. Для динамических сайтов с подгружаемым JavaScript используют Selenium или Playwright, которые эмулируют действия пользователя в браузере.
Существует также ряд специализированных библиотек и фреймворков, упрощающих сбор больших объёмов данных и управление запросами:
| Инструмент | Описание | Применение |
|---|---|---|
| BeautifulSoup | Разбор HTML и XML | Извлечение текста, таблиц и ссылок со статических страниц |
| requests | HTTP-запросы | Получение HTML-кода страниц и API данных |
| Selenium | Автоматизация браузера | Парсинг динамических сайтов и взаимодействие с формами |
| Playwright | Современная альтернатива Selenium | Парсинг сайтов с сложной подгрузкой контента и многопоточность |
| Scrapy | Фреймворк для скрапинга | Сбор больших объёмов данных с поддержкой очередей и хранения в базах |
При выборе инструментов следует учитывать: сложность страницы, необходимость работы с JavaScript, объём данных и требования к автоматизации. Комбинация библиотек часто даёт лучший результат, например, requests + BeautifulSoup для получения HTML и Selenium для элементов, которые подгружаются динамически.
Работа с HTML и DOM структурой страницы
HTML-страница состоит из элементов, объединённых в дерево DOM. Для извлечения данных важно понимать теги, атрибуты и иерархию. Основные теги для скрапинга: div, span, table, ul, li, a и img. Атрибуты id и class позволяют точно выбрать нужные элементы.
Для навигации по DOM удобно использовать методы поиска элементов: find(), find_all() в BeautifulSoup или querySelector и querySelectorAll в Selenium. XPath и CSS-селекторы позволяют выбирать элементы по сложным условиям, например, по вложенности или тексту.
Важно анализировать структуру страницы перед парсингом. Если данные находятся в таблицах, нужно учитывать строки (tr) и ячейки (td, th). Для списков извлекают элементы li внутри ul или ol. Элементы с динамическим контентом могут появляться после выполнения скриптов, что требует использования браузерных инструментов.
Для точного извлечения текста используют методы .text или .get_text(), а для ссылок и изображений – .get(‘href’) и .get(‘src’). Регулярные выражения помогают очистить данные от лишних символов или объединить текст из нескольких элементов.
Использование библиотек для запросов к сайтам

Для получения HTML-кода страниц и API данных применяют библиотеки, которые управляют HTTP-запросами. Основные библиотеки в Python:
- requests – простая и надёжная библиотека для выполнения GET и POST-запросов.
- httpx – поддерживает асинхронные запросы и HTTP/2, подходит для больших объёмов данных.
- urllib – встроенный модуль Python для базовых запросов и работы с URL.
При работе с запросами рекомендуется:
- Указывать заголовки User-Agent, чтобы сайт корректно обрабатывал запросы.
- Обрабатывать коды ответа сервера: 200 – успешный запрос, 403 – запрет доступа, 404 – страница не найдена.
- Использовать сессии (requests.Session()) для сохранения cookies и авторизации.
- Вводить задержки между запросами, чтобы не перегружать сервер.
- Работать с параметрами URL через словари (params) для упрощения динамических запросов.
Для API данных удобно использовать JSON-ответы: библиотека requests позволяет получать словарь Python через .json(), что ускоряет обработку и интеграцию в парсер.
Парсинг данных с помощью Python
Для парсинга HTML в Python используют библиотеки BeautifulSoup, lxml и html.parser. BeautifulSoup удобна для извлечения текста, таблиц, списков и ссылок благодаря методам find(), find_all() и select().
Пример извлечения таблицы:
1. Загружаем HTML с помощью requests.get().
2. Создаём объект BeautifulSoup: soup = BeautifulSoup(html, ‘lxml’).
3. Находим таблицу: table = soup.find(‘table’, {‘id’:’data’}).
4. Проходим по строкам: for row in table.find_all(‘tr’) и извлекаем ячейки через td.get_text().
Для обработки списков используют ul и ol с li, а для ссылок – атрибут href. Динамический контент парсят через Selenium или Playwright, управляя браузером и ожидая появления элементов методом WebDriverWait.
Регулярные выражения помогают фильтровать и нормализовать данные, например, извлекать только числа, даты или email-адреса. Совмещение BeautifulSoup и re позволяет получать точные и структурированные данные для последующего сохранения или анализа.
Обработка таблиц и списков на страницах
Таблицы на веб-страницах содержат строки tr и ячейки td или заголовки th. Для извлечения данных используют методы find_all(‘tr’) и find_all(‘td’), предварительно выбирая таблицу по id или class. Если встречаются объединённые ячейки (rowspan или colspan), их необходимо учитывать при формировании структуры данных.
Списки представлены тегами ul, ol и li. Извлечение элементов выполняется через find_all(‘li’) или CSS-селекторы. Вложенные списки обрабатываются рекурсивно, чтобы сохранить иерархию элементов и их порядок.
Практические рекомендации:
- Очищать текст от лишних пробелов и HTML-тегов с помощью .strip() и регулярных выражений.
- Преобразовывать числовые данные в int или float для анализа и сортировки.
- Использовать библиотеку pandas для конвертации таблиц в DataFrame и последующего экспорта в CSV или Excel.
- Для динамических таблиц и списков применять Selenium или Playwright с ожиданием появления элементов через WebDriverWait.
Структурированное хранение извлечённых данных облегчает дальнейший анализ и объединение информации с разных страниц или сайтов.
Сохранение собранной информации в файлы
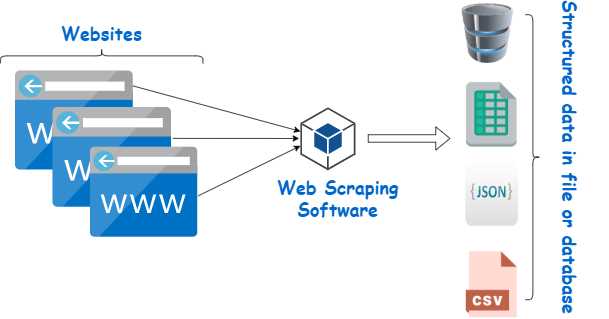
Для хранения данных после парсинга применяют форматы CSV, JSON и Excel. CSV подходит для таблиц и списков с фиксированной структурой, JSON – для вложенных и иерархических данных, Excel удобен для последующего анализа в офисных приложениях.
Пример сохранения в CSV с использованием Python:
1. Импортировать модуль: import csv.
2. Создать файл и объект writer: with open(‘data.csv’, ‘w’, newline=») as file: writer = csv.writer(file).
3. Записать заголовки: writer.writerow([‘Название’, ‘Цена’, ‘Ссылка’]).
4. Записать строки данных: writer.writerow([title, price, url]).
Для JSON используют import json и json.dump(data, file, ensure_ascii=False) для сохранения вложенных структур без потери символов. В Excel данные сохраняют через pandas.DataFrame.to_excel(‘data.xlsx’, index=False).
Рекомендации:
- Проверять корректность кодировки UTF-8, чтобы избежать ошибок при открытии файлов.
- Использовать уникальные имена файлов при регулярном сборе данных для предотвращения перезаписи.
- При больших объёмах данных применять пакетное сохранение по частям.
- Структурировать поля в соответствии с типами данных для упрощения последующего анализа.
Обход защит и ограничений сайтов
Многие сайты ограничивают количество запросов и блокируют подозрительную активность. Для обхода применяют имитацию реального пользователя: указывают заголовки User-Agent, используют cookies и поддерживают сессии через requests.Session() или Selenium.
Для распределения нагрузки применяют задержки между запросами (time.sleep()) и случайный интервал. Использование прокси-серверов позволяет менять IP-адреса и обходить географические ограничения.
JavaScript-защиты и динамический контент обрабатывают через браузерные движки Selenium или Playwright, выполняя скрипты и ожидая появления элементов с помощью WebDriverWait.
Рекомендации по обходу ограничений:
- Не превышать разумное количество запросов, чтобы избежать блокировки.
- Использовать случайный порядок посещения страниц и чередовать User-Agent.
- Хранить и обновлять cookies для авторизованных сессий.
- Для сложных защит применять headless-браузеры с имитацией движений мыши и прокрутки.
Соблюдение этих методов снижает риск блокировок и обеспечивает стабильный сбор данных без нарушения правил сайта.
Автоматизация сбора данных по расписанию
Автоматизация позволяет регулярно получать обновлённые данные без ручного запуска скриптов. В Linux для этого используют cron, а в Windows – Планировщик задач.
Пример настройки в Linux:
- Открыть crontab: crontab -e.
- Добавить строку: 0 6 * * * /usr/bin/python3 /path/to/scraper.py для ежедневного запуска в 6:00.
- Проверить корректность выполнения: grep CRON /var/log/syslog.
Для Windows:
- Создать задачу в Планировщике задач.
- Указать путь к Python и скрипту.
- Настроить расписание запуска и условия выполнения.
Рекомендации при автоматизации:
- Добавлять логирование с указанием времени запуска и количества собранных записей.
- Обрабатывать ошибки и исключения, чтобы скрипт продолжал работу при сбоях.
- Использовать блокировку одновременных запусков, чтобы предотвратить дублирование данных.
- Хранить файлы с результатами в отдельных папках по дате для упрощения анализа.
Вопрос-ответ:
Какие библиотеки Python лучше использовать для парсинга статических страниц?
Для статических страниц удобны библиотеки requests и BeautifulSoup. Requests позволяет получить HTML-код страницы через GET-запрос, а BeautifulSoup помогает извлекать текст, таблицы, списки и ссылки. Для анализа сложных структур лучше использовать парсер lxml, который быстрее обрабатывает большие объёмы HTML.
Как получить данные с сайтов, где контент подгружается через JavaScript?
В таких случаях обычные HTTP-запросы не дают результата, так как содержимое создаётся скриптами на стороне клиента. Решение — использовать браузерные движки через Selenium или Playwright. Они позволяют запускать страницу, ожидать появления элементов с помощью WebDriverWait и получать актуальный HTML с динамическим контентом.
Как правильно обрабатывать таблицы с объединёнными ячейками на страницах?
Таблицы с rowspan и colspan требуют учёта объединённых ячеек при формировании структуры данных. Обычно при парсинге создают список списков, вставляя повторяющиеся значения для объединённых ячеек. Это позволяет сохранить корректное соответствие столбцов и строк при сохранении в CSV или DataFrame.