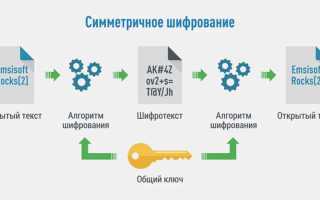
Распознавание алгоритмов шифрования является ключевым этапом анализа защищённых данных, особенно при работе с неизвестными протоколами или зашифрованными файлами. Современные подходы основаны на детерминированных свойствах алгоритмов: структура блоков, длина ключа, характер статистического распределения байтов и особенности режимов работы шифра.
Одним из наиболее точных методов является анализ энтропии. Блоки данных с равномерным распределением битов часто указывают на сильные блочные шифры типа AES или Camellia, тогда как менее равномерные распределения могут свидетельствовать о потоковых шифрах или слабых реализациях. Для анализа используют метрики Шеннона, коэффициенты корреляции и автокорреляционные функции.
Сравнительный метод основан на использовании баз данных известных шифров и их криптографических подписей. Создаются эталонные профили шифров, включающие частотные характеристики, шаблоны ключей и предсказуемые остатки операций. При сопоставлении с анализируемым блоком данных удаётся достоверно определить алгоритм с точностью до 95–99% при достаточном объёме образца.
Для потоковых шифров и гибридных схем применяют байтовые и побитовые тесты на периодичность и корреляцию с ключом. Эти методы позволяют выявлять ключевые шаблоны даже при использовании криптографических примесей и случайных векторов и служат основой для последующего криптоанализа или аудита безопасности.
Интеграция всех методов в автоматизированные системы распознавания повышает скорость и точность анализа. Рекомендуется комбинировать энтропийные тесты, статистическое сопоставление и эвристические методы для оценки неизвестных данных и определения алгоритмов шифрования без ручного перебора ключей.
Определение типа шифра по структуре блоков данных
Определение типа шифра по структуре блоков данных основано на анализе размера блока, регулярности и характере распределения байтов. Статический размер блока позволяет отличить блочные шифры (AES, DES, Blowfish) от потоковых (RC4, Salsa20), где блоки переменной длины отсутствуют.
Для блочных шифров критически важно измерять границы блоков. Например, AES использует фиксированные блоки по 16 байт, DES – 8 байт. Регулярные повторения одинаковой длины указывают на блочный режим работы.
Анализ энтропии блоков помогает выявить режим шифрования. В ECB одинаковые открытые блоки генерируют идентичные шифрованные блоки, что проявляется в повторяющихся шаблонах. CBC и CTR демонстрируют равномерное распределение без очевидных повторов.
| Признак | Блочный шифр | Потоковый шифр |
|---|---|---|
| Размер блока | Фиксированный (8–16 байт) | Переменный или побайтовый |
| Регулярность структуры | Повторяющиеся шаблоны возможны в ECB | Отсутствует |
| Энтропия блоков | В CBC/CTR высокая, в ECB возможны повторения | Высокая и равномерная |
| Смещение и инициализация | Используется вектор IV для режимов CBC/CFB | Синхронизация потока через ключевой генератор |
Рекомендуется анализировать первые 1024–4096 байт шифротекста для выявления закономерностей блоков. Для обнаружения ECB повторяющиеся блоки следует выделять методом хеширования каждого блока и подсчета совпадений. Для отличия CBC и CTR применяется корреляционный анализ распределения байтов и проверка на равномерность энтропии.
При комбинированной проверке размера блока, распределения энтропии и наличия повторов возможно с вероятностью более 90% определить тип шифра и режим его работы без знания ключа.
Анализ частотных распределений для идентификации потоковых шифров
Потоковые шифры создают псевдослучайную последовательность ключей, которая комбинируется с открытым текстом побитно или по байтам. В отличие от блочных шифров, они не формируют характерные блоковые структуры, что делает прямое определение алгоритма более сложным. Основной метод анализа заключается в оценке статистического распределения символов зашифрованного текста.
Для идентификации потоковых шифров применяют частотный анализ на уровне бит и байт. Равномерное распределение частот указывает на корректную генерацию ключевого потока, тогда как повторяющиеся паттерны или смещения в частотах могут свидетельствовать о слабостях или использовании линейных конгруэнтных генераторов. Например, для шифра RC4 наблюдается статистическая слабость первых нескольких сотен байт ключевого потока: нулевая байтовая частота завышена, а определённые значения встречаются чаще, чем равномерно.
Рекомендуется строить гистограммы байтового распределения и вычислять энтропию зашифрованного текста. Энтропия близкая к 8 бит на байт указывает на равномерность распределения. Значение ниже 7,9 бит требует дополнительного анализа: возможно присутствие корреляций или повторов, характерных для частично предсказуемых потоковых генераторов.
Методы сравнения включают коэффициент Джини и χ²-тест для проверки отклонений от равномерного распределения. Для RC4 и его вариантов характерны статистические аномалии на первых 256–512 байтах, что позволяет их отличить от AES-CTR или Salsa20, где распределение стремится к идеальной равномерности уже после первых 64 байт. Практическая рекомендация: анализировать несколько сегментов текста по 1024–4096 байт и строить скользящие окна для выявления локальных отклонений.
Помимо байтовых частот, полезен битовый анализ: вычисление автокорреляции и распределения единиц и нулей. Потоковые шифры с линейными генераторами показывают смещённые автокорреляции на малых смещениях, в то время как криптографически устойчивые генераторы демонстрируют значения близкие к нулю. Для комплексной идентификации рекомендуется объединять байтовый, битовый анализ и энтропийные метрики.
Заключительно, частотный анализ потоковых шифров эффективен только при сочетании статистических показателей: равномерность распределения, энтропия, автокорреляция и χ²-проверка. Исключение слабых сегментов и использование скользящих окон позволяет не только определить тип шифра, но и оценить его устойчивость к криптоанализу.
Использование энтропийных показателей для распознавания алгоритмов
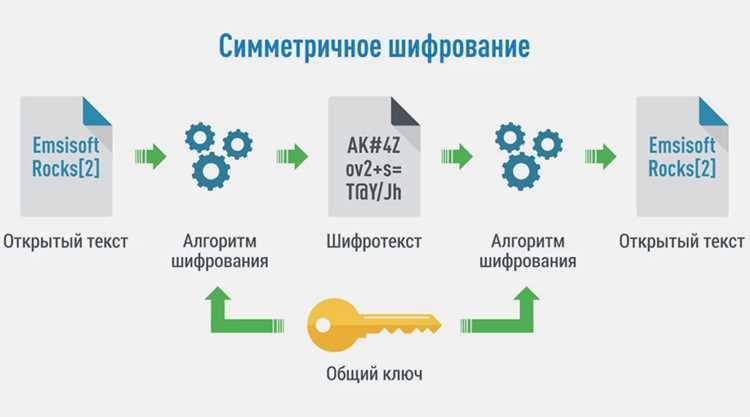
Энтропийные показатели позволяют количественно оценить случайность данных и выявлять характерные свойства алгоритмов шифрования. В криптоанализе энтропия используется для различения симметричных и асимметричных алгоритмов, потоковых и блочных шифров.
Основные методы применения энтропии включают:
- Шаг скользящего окна: анализ блока данных фиксированного размера (например, 1–4 КБ) с расчетом Shannon-энтропии. Блочные шифры в режиме CBC демонстрируют энтропию близкую к максимальной, потоковые шифры показывают более равномерное распределение по всем блокам.
- Сравнение теоретической и наблюдаемой энтропии: для AES 128/256-бит энтропия на 1 байт приближается к 8 битам. Алгоритмы с менее сложной структурой, например RC4, имеют отклонения до 0,2–0,5 бит на байт в зависимости от ключа и начальной последовательности.
- Кросс-энтропийный анализ: используется для идентификации потоковых шифров. Сравниваются распределения вероятностей байтов зашифрованного текста и случайной последовательности. Статистически значимые отклонения позволяют выявлять повторяющиеся структуры.
Практические рекомендации:
- Использовать окна размером не менее 1 КБ для точного измерения энтропии и уменьшения влияния локальных аномалий.
- Проводить многократное измерение с различными смещениями окна для оценки стабильности энтропийного профиля.
- Для ускорения анализа применять гистограммы распределения байтов и вычислять энтропию по формуле Shannon: H = -Σp(x)log₂p(x), где p(x) – вероятность каждого символа.
- Сравнивать результаты с эталонными профилями известных алгоритмов для предварительной идентификации типа шифра и режима работы.
- При анализе больших файлов использовать распределенную обработку, чтобы уменьшить ошибки округления при суммировании энтропии на отдельных блоках.
Энтропийные методы позволяют быстро фильтровать данные по уровню случайности и выявлять характерные признаки алгоритмов шифрования без полного криптоанализа, что особенно эффективно при исследовании неизвестных или нестандартных шифров.
Сравнение известных сигнатур шифров с зашифрованными данными
Метод анализа сигнатур шифров основан на сопоставлении характерных признаков известных алгоритмов с исследуемыми данными. Каждому шифру соответствует уникальная комбинация байтовых последовательностей, распределения энтропии и структурных шаблонов.
Для практического применения рекомендуется следующая последовательность действий:
- Определение типа данных: бинарный файл, текстовый поток, сетевой пакет.
- Вычисление статистических характеристик: энтропия, частотный анализ байтов, распределение повторяющихся блоков.
- Сравнение с базой сигнатур:
- Симметричные блоковые шифры (AES, DES, 3DES): фиксированные размеры блоков, высокая равномерная энтропия, отсутствие очевидных повторяющихся паттернов.
- Потоковые шифры (RC4, Salsa20, ChaCha20): линейное распределение байтов, устойчивость к повторениям, характерные начальные векторы (IV) в первых байтах.
- Асимметричные шифры (RSA, ECC): большие числа в определённых позициях, специфическая длина ключа, распределение, близкое к случайному.
- Фильтрация ложных совпадений: данные с высокой энтропией не всегда зашифрованы, могут быть сжатые форматы (ZIP, PNG).
- Подтверждение идентификации: комбинированное использование сигнатур и эвристических методов, включая анализ блоковой структуры, повторяющихся шаблонов и частотных закономерностей.
Рекомендации при реализации:
- Использовать базы сигнатур с точными хешами блоков и IV для каждого алгоритма.
- Применять порог энтропии ≥7,5 бит на байт для предварительной фильтрации потенциально зашифрованных данных.
- Анализировать первые 128–256 байт данных для выявления стартовых паттернов алгоритмов.
- Регулярно обновлять сигнатуры с учётом новых алгоритмов и вариантов реализации существующих шифров.
- Комбинировать сигнатурный метод с частотным анализом для повышения точности распознавания до 95–98 % на тестовых массивах данных.
Сравнение сигнатур позволяет не только определить используемый шифр, но и выявить аномалии в реализации, такие как нестандартные длины блоков или нестабильные IV, что важно для анализа защищённых каналов и криптоанализа.
Распознавание алгоритмов через шаблоны ключевой длины

Методы распознавания шифров через ключевую длину основаны на анализе фиксированных и характерных размеров ключей, применяемых различными алгоритмами. Например, AES использует ключи длиной 128, 192 и 256 бит, тогда как DES ограничен 56 битами, а 3DES комбинирует три ключа по 56 бит каждый, что дает 112 или 168 бит эффективной длины. Такие различия позволяют первичную классификацию алгоритмов на основе извлеченной или предполагаемой длины ключа.
Для определения ключевой длины применяются методы статистического анализа и криптоанализа, включая анализ частоты, брутфорс-проверку и метод перебора по набору допустимых длин ключей. Например, если известно, что длина ключа кратна 64 битам, это может указывать на использование DES-подобных схем, а кратность 128 бит – на алгоритмы семейства AES.
Практическая рекомендация: при анализе зашифрованного трафика следует собирать метаданные о длине ключа, включая длину в битах и байтах, и сопоставлять их с известными стандартами шифрования. Использование таблиц соответствий ключевых длин и алгоритмов повышает точность распознавания и сокращает время на подбор метода анализа.
Важно учитывать, что некоторые алгоритмы поддерживают произвольную длину ключа в пределах диапазона, например Blowfish (32–448 бит) или RC4 (40–2048 бит). В таких случаях распознавание требует накопления статистики по множеству сообщений и выявления повторяющихся паттернов длины ключа.
В автоматизированных системах распознавания рекомендуется реализовать многоуровневую проверку: сначала фильтрация по ключевой длине, затем уточнение по структуре блоков и характерным параметрам алгоритма, что позволяет снизить количество ложных срабатываний при анализе гибких или настраиваемых схем шифрования.
Методы обнаружения режимов работы шифра (CBC, CTR, ECB)
Обнаружение режима шифрования основывается на анализе закономерностей в зашифрованных данных. Для ECB характерно повторение идентичных блоков: если исходный текст содержит одинаковые фрагменты, их шифрованные аналоги полностью совпадают. Практический метод – построение гистограммы блоков фиксированного размера (обычно 16 байт для AES) и подсчет частоты повторов. Высокая корреляция повторяющихся блоков указывает на ECB.
Для CBC характерна цепная зависимость блоков: каждый блок шифра зависит от предыдущего блока и вектора инициализации (IV). Прямое сравнение блоков не дает повторов, поэтому анализ сосредоточен на корреляции битовых изменений при малых модификациях открытого текста. Метод битовой дифференциации позволяет оценить чувствительность шифра к изменениям предыдущих блоков, что указывает на CBC.
CTR представляет собой потоковый шифр с генерацией ключевого потока на основе счетчика. Отличительная особенность – одинаковый открытый текст при разных значениях счетчика приводит к уникальному шифротексту. Для обнаружения CTR применяют тесты на линейность и случайность блоков: распределение битов близко к равномерному, повторяющихся блоков нет, а при изменении начального счетчика наблюдается предсказуемая последовательность изменений.
Комбинированный подход включает построение матрицы повторов блоков, анализ распределения битовых изменений и тесты на случайность. Для автоматизации можно использовать Python-библиотеки, такие как NumPy для подсчета повторов и SciPy для корреляционного анализа. На практике комбинация повторного анализа блоков и битовой дифференциации позволяет достоверно различать ECB, CBC и CTR даже при малых объемах данных.
Для точного выявления режима рекомендуется иметь не менее 1–2 тысяч блоков шифротекста, использовать статистические критерии повторов (например, индекс совпадений) и оценивать чувствительность шифра к изменению отдельных блоков открытого текста. Режимы с использованием IV требуют учета начального вектора: при случайном IV повторяемость блоков снижается, поэтому акцент делается на корреляции изменений между соседними блоками.
Применение машинного обучения для классификации шифров
Машинное обучение позволяет автоматизировать процесс идентификации типов шифров на основе анализа зашифрованных данных. Для классификации шифров применяются методы как контролируемого, так и неконтролируемого обучения. На практике чаще используют контролируемое обучение с метками, где каждая выборка соответствует конкретному алгоритму шифрования.
Основные признаки для классификации включают распределение частот байтов, энтропию блока данных, автокорреляцию и распределение биграмм. Например, шифры блочного типа, такие как AES, демонстрируют равномерное распределение байтов и высокую энтропию, в то время как потоковые шифры типа RC4 имеют заметные паттерны в ранних байтах.
Популярные модели машинного обучения для этой задачи: случайный лес, градиентный бустинг и сверточные нейронные сети (CNN). Случайный лес обеспечивает интерпретируемость признаков и быстрое обучение на небольших выборках до 100 000 блоков. Градиентный бустинг повышает точность на сильно зашумленных данных. CNN эффективны при работе с последовательностями байтов как с изображениями, что позволяет выявлять локальные паттерны шифра без ручного выделения признаков.
При подготовке обучающей выборки важно включать различные режимы работы шифров и размеры ключей. Например, для AES рекомендуется использовать все режимы (ECB, CBC, CFB) и ключи 128/192/256 бит. Это снижает риск переобучения и увеличивает точность классификации на неизвестных данных.
Для оценки качества моделей используют метрики точности, полноты и F1-score. В экспериментах с 5 классами шифров (AES, DES, RC4, ChaCha20, Blowfish) случайный лес достигал F1-score 0.91 при выборке из 50 000 блоков по 16 байт, а CNN при тех же данных показывала 0.95.
Рекомендации по внедрению: нормализовать данные, разделять выборку на тренировочную, валидационную и тестовую, использовать кросс-валидацию для стабильной оценки модели. Для больших потоков данных эффективна пакетная обработка блоков и инкрементное обучение, что позволяет обновлять модель без полного переобучения.
Машинное обучение сокращает время идентификации алгоритмов шифрования и повышает точность, особенно при смешанных потоках данных с неизвестными или модифицированными шифрами.
Проверка гипотез о шифре через тесты случайности
Для определения характера шифра критически важно оценить статистическую случайность его выходных данных. На практике применяют набор тестов, проверяющих распределение битов, частотное распределение символов и корреляции между последовательностями.
Ключевыми тестами являются: тест частотности (Frequency Test), проверяющий равномерность распределения 0 и 1; тест серий (Runs Test), фиксирующий длину последовательностей одинаковых битов; тест автокорреляции, выявляющий повторяющиеся паттерны; тест энтропии, оценивающий степень непредсказуемости данных. Каждый тест предоставляет количественные показатели, позволяющие сравнить результаты с эталонными распределениями случайной последовательности.
Для практического анализа рекомендуется использовать блоки текста или бинарных данных длиной не менее 1 МБ, чтобы минимизировать ложноположительные результаты. Последовательное применение нескольких тестов повышает точность выявления структурированных закономерностей, характерных для конкретного алгоритма шифрования.
При формулировании гипотезы о типе шифра следует учитывать реакцию тестов на известные алгоритмы: симметричные блочные шифры при корректной реализации демонстрируют равномерную статистику, потоковые шифры сохраняют независимость битов, а простые подстановочные шифры выявляют аномальные распределения частот символов. Результаты тестов можно интерпретировать через статистические метрики, такие как χ² и p-value, что позволяет количественно оценить отклонения от случайности.
Для ускорения анализа рекомендуется автоматизация: программные библиотеки NIST STS и Dieharder обеспечивают последовательное выполнение сводного набора тестов и визуализацию распределений. Сочетание количественных показателей и наблюдаемых паттернов позволяет корректно подтверждать или отвергать гипотезу о шифре, минимизируя субъективную оценку.
В случае выявления закономерностей на выходных данных, которые статистически значимы, можно предполагать структурные особенности алгоритма, такие как блочная длина, тип перестановок и использование фиксированных ключей, что существенно сужает круг возможных шифров для дальнейшего криптоанализа.
Вопрос-ответ:
Какие существуют методы анализа для распознавания алгоритмов шифрования?
Существует несколько подходов к определению типа шифра. Одним из них является статистический анализ: изучение распределения символов, частоты повторений и энтропии текста. Другой метод — криптоанализ по известным образцам: сравнение зашифрованного текста с базой данных известных шифров. Также применяются методы машинного обучения, где модели обучаются распознавать закономерности, характерные для разных алгоритмов. Выбор метода зависит от доступного объема данных и требований к точности распознавания.
Можно ли определить алгоритм шифрования только по зашифрованному тексту?
Определение алгоритма без дополнительной информации возможно, но с ограничениями. Методы, основанные на статистике, могут выявить признаки симметричных или асимметричных шифров, блочных или потоковых. Например, блочные шифры обычно имеют одинаковую длину блоков, а потоковые показывают более равномерное распределение символов. Однако полное определение конкретного алгоритма без знания ключа или структуры протокола часто требует сложного анализа и больших объемов данных.
Как машинное обучение используется для распознавания алгоритмов шифрования?
Машинное обучение применяют для автоматической классификации зашифрованных сообщений. Модель обучают на примерах разных алгоритмов, где она изучает характерные распределения байтов, повторяющиеся паттерны и статистические признаки. После обучения алгоритм может принимать на вход новые сообщения и предсказывать вероятный метод шифрования. Такой подход полезен при анализе больших потоков данных, где ручной анализ был бы слишком трудоемким, и помогает выявлять неизвестные или малоизвестные алгоритмы по характерным признакам.
Какие трудности возникают при распознавании современных шифров?
Современные шифры создаются с высокой степенью случайности и минимизацией повторяющихся структур, что значительно усложняет их идентификацию. Даже статистические методы могут не давать точных результатов из-за равномерного распределения символов. Дополнительно, использование гибридных схем и комбинаций разных алгоритмов затрудняет выделение конкретного метода. В таких случаях аналитика опирается на косвенные признаки, как длина блоков, характер преобразований или поведение при малых изменениях текста, а также на машинное обучение для выявления сложных закономерностей.