Поиск самого длинного слова в строке часто требуется при обработке текстов, анализе данных или подготовке отчетов. В Python это можно сделать за несколько шагов с использованием стандартных методов строк и встроенных функций. Например, метод split() позволяет разделить текст на отдельные слова без подключения дополнительных библиотек.
Для сравнения длины слов удобно использовать функцию len(). Она возвращает количество символов в слове, включая буквы и цифры. При необходимости можно предварительно удалить знаки препинания с помощью str.strip() или регулярных выражений, чтобы длина учитывала только буквенные символы.
Кроме цикла перебора слов, Python позволяет найти максимальное значение с помощью max() с аргументом key=len. Этот способ сокращает код и делает его более читаемым, особенно при обработке длинных текстов. Такой подход применим как к коротким строкам, так и к целым файлам с текстовыми данными.
Важно предусмотреть обработку пустых строк или нескольких подряд идущих пробелов. Использование strip() и проверка if word предотвращает ошибки при вычислении длины слов и гарантирует корректный результат даже в сложных случаях.
Разделение строки на отдельные слова
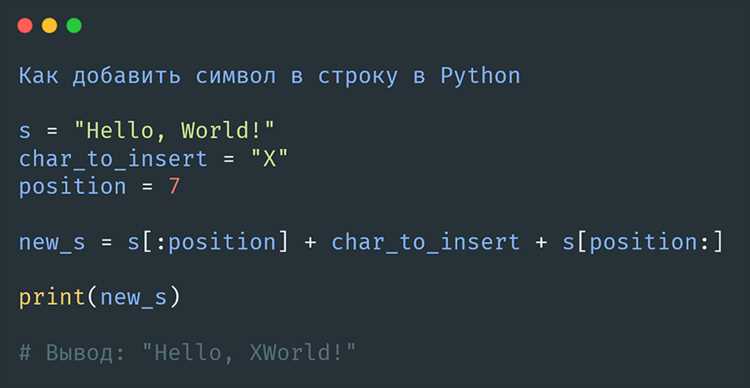
В Python для получения отдельных слов из строки используется метод split(). По умолчанию он разделяет текст по пробелам, но можно указать любой разделитель. Например:
text = "Python упрощает обработку текстов"
words = text.split()
В результате переменная words будет содержать список: [‘Python’, ‘упрощает’, ‘обработку’, ‘текстов’].
Если строка содержит знаки препинания, их можно удалить до разделения:
import string
text = "Python, упрощает обработку текстов!"
clean_text = text.translate(str.maketrans('', '', string.punctuation))
words = clean_text.split()
Рекомендации при разделении строки:
- Использовать strip() для удаления пробелов в начале и конце строки.
- Применять split() без аргументов для корректной обработки нескольких пробелов.
- При необходимости учитывать другие символы-разделители, например tab или точку с запятой, указав их в split().
Для сложных случаев, когда слова разделяются разными символами или содержат цифры и спецсимволы, лучше использовать регулярные выражения:
import re
text = "Python-обработка;текстов,данных"
words = re.findall(r'\w+', text)
Этот подход извлечет все последовательности букв и цифр, игнорируя разделители и знаки препинания.
Использование цикла для перебора слов
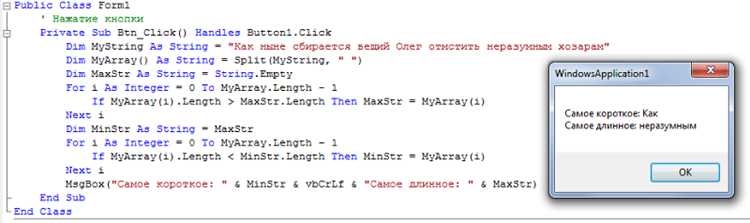
Для поиска самого длинного слова можно пройтись по списку слов с помощью цикла for. Каждый элемент проверяется на длину с помощью функции len() и сравнивается с текущим максимумом.
Пример реализации:
text = "Python упрощает обработку текстов"
words = text.split()
max_word = ""
max_length = 0
for word in words:
if len(word) > max_length:
max_length = len(word)
max_word = word
Рекомендации при переборе слов:
- Удалять лишние пробелы с помощью strip(), чтобы не учитывать пустые строки.
- Игнорировать знаки препинания с помощью str.strip(string.punctuation), если важно сравнивать только буквы.
- Сохранять два значения: текущее максимальное слово и его длину, чтобы избежать повторного вычисления len() для каждого слова.
Этот метод подходит для коротких и средних строк, а также хорошо интегрируется с дополнительными проверками, например, фильтрацией по минимальной длине слова или исключением чисел.
Сравнение длины слов при поиске максимального
Чтобы определить самое длинное слово, каждое слово из списка проверяется по длине с помощью функции len(). Сравнение проводится с текущим максимальным значением, которое обновляется при нахождении более длинного слова.
Пример подхода с циклом:
words = ["Python", "упрощает", "обработку", "текстов"]
max_word = words[0]
for word in words[1:]:
if len(word) > len(max_word):
max_word = word
Советы для корректного сравнения:
- Удалять лишние пробелы и знаки препинания перед сравнением, чтобы длина отражала только буквы.
- При необходимости учитывать несколько слов одинаковой максимальной длины, сохранять их в отдельный список.
- Использовать переменную для хранения длины текущего максимального слова, чтобы не вычислять len() повторно для каждого сравнения.
Такой метод позволяет быстро и точно определить самое длинное слово в любой строке, обеспечивая стабильный результат даже при наличии специальных символов или чисел.
Применение функции max с ключом len
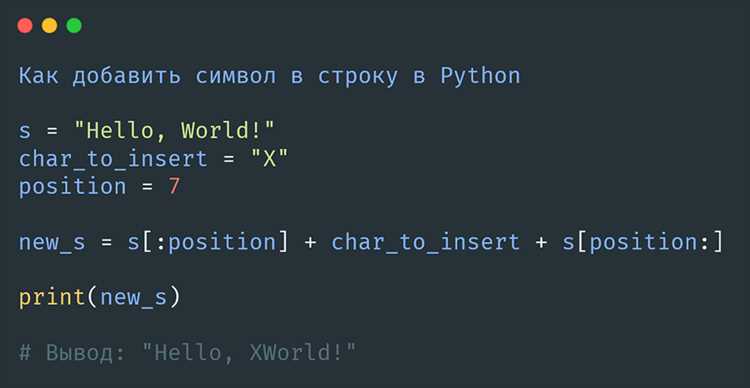
Функция max позволяет найти элемент с наибольшим значением по заданному критерию. В случае поиска самого длинного слова в строке ключом выступает функция len.
Пример базового использования:
text = "Python упрощает обработку строк"
words = text.split()
longest_word = max(words, key=len)
Разбор работы:
text.split() разбивает строку на слова по пробелам.max(words, key=len) сравнивает длину каждого слова и возвращает слово с наибольшей длиной.
Особенности применения:
- Если строка пустая,
max вызовет ошибку. Используйте проверку: if words:.
- Для игнорирования знаков препинания подключите
str.strip или регулярные выражения: re.findall(r'\w+', text).
- При нескольких словах одинаковой максимальной длины
max вернет первое встреченное слово.
Вариант с обработкой пунктуации и пустых строк:
import re
text = "Python, упрощает обработку строк!"
words = re.findall(r'\w+', text)
longest_word = max(words, key=len) if words else ""
Использование key=len экономит ресурсы, так как max проходит по списку один раз, вычисляя длину каждого слова на лету, без необходимости создания дополнительного списка длин.
Игнорирование знаков препинания в словах
При поиске самого длинного слова важно исключить влияние знаков препинания, чтобы длина учитывала только буквы и цифры.
Пример с использованием str.strip для удаления знаков в начале и конце слова:
text = "Python, упрощает обработку строк!"
words = [word.strip(".,!?") for word in text.split()]
longest_word = max(words, key=len)
Использование регулярных выражений позволяет полностью игнорировать все небуквенные символы:
import re
text = "Python, упрощает обработку строк!"
words = re.findall(r'\w+', text)
longest_word = max(words, key=len)
Рекомендации:
- Для простых случаев достаточно
str.strip, если знаки препинания ограничены концами слов.
- Для текста с внутренними знаками, дефисами или апострофами лучше использовать
re.findall(r'\w+', text).
- Регулярные выражения позволяют корректно обрабатывать слова с цифрами и буквами одновременно.
Обработка пустых строк и пробелов
При поиске самого длинного слова важно корректно обрабатывать строки, содержащие только пробелы или пустые значения, чтобы избежать ошибок.
Проверка перед применением max:
text = " "
words = text.split()
longest_word = max(words, key=len) if words else ""
Для удаления лишних пробелов внутри строки можно использовать метод split(), который автоматически игнорирует последовательные пробелы.
Сравнение разных подходов:
Метод
Описание
Результат для пустой строки
text.split()Разделяет строку на слова по пробелам, игнорирует пустые элементы
Пустой список
text.strip()Удаляет пробелы в начале и конце строки
Пустая строка
if words:Проверка наличия слов перед вызовом max
Предотвращает ошибку
Для текстов с множественными пробелами между словами split() корректно разбивает их на отдельные элементы, исключая пустые строки, что упрощает поиск самого длинного слова.
После вычисления самого длинного слова важно корректно вывести результат и проверить работу алгоритма на разных строках.
text = "Python упрощает обработку строк"
words = text.split()
longest_word = max(words, key=len) if words else ""
print("Самое длинное слово:", longest_word)
Для проверки нескольких вариантов можно использовать список тестовых строк:
test_texts = [
"Python упрощает обработку строк",
" ",
"Короткие слова a aa aaa",
"Слово-с-подчеркиванием"
]
for text in test_texts:
words = text.split()
longest_word = max(words, key=len) if words else ""
print(f"Строка: {text!r} → Длинное слово: {longest_word}")
Рекомендации:
- Добавляйте проверку пустых списков
if words, чтобы избежать ошибок при пустых строках.
- Для строк с одинаковой максимальной длиной
max вернет первое встреченное слово.
- Можно расширить проверку с помощью регулярных выражений, чтобы исключить знаки препинания перед сравнением.
Вопрос-ответ:
Как найти самое длинное слово в строке с пробелами и пустыми словами?
Для строк с пробелами или пустыми значениями сначала используйте метод split(), который разбивает текст на список слов и автоматически игнорирует лишние пробелы. После этого применяйте max(words, key=len) для поиска слова с наибольшей длиной. Перед вызовом max полезно проверять, что список не пустой: if words. Например:
text = " "
words = text.split()
longest = max(words, key=len) if words else ""
В результате для пустой строки функция вернет пустую строку.
Можно ли учитывать слова с дефисами или апострофами при поиске самого длинного слова?
Если слова содержат дефисы или апострофы, метод split() разделит строку только по пробелам, сохраняя такие символы внутри слов. Для удаления нежелательных знаков препинания используйте регулярные выражения: re.findall(r'\w+', text). Это позволит корректно вычислять длину слов, игнорируя знаки препинания, но сохраняя буквы и цифры.
Что делать, если несколько слов имеют одинаковую максимальную длину?
Функция max возвращает первое встреченное слово с максимальной длиной. Если нужно получить все слова с одинаковой длиной, сначала определите длину самого длинного слова: max_len = max(len(word) for word in words), а затем выберите все слова с этой длиной: long_words = [word for word in words if len(word) == max_len]. Это позволяет работать с несколькими вариантами.
Как корректно вывести результат для нескольких строк с разной структурой текста?
Для проверки разных текстов создайте список строк и используйте цикл. Внутри цикла разбивайте строку на слова и применяйте max с ключом len. Можно оформить вывод с помощью f-строк для удобного отображения:
for text in texts:
words = text.split()
longest = max(words, key=len) if words else ""
print(f"Строка: {text!r} → Длинное слово: {longest}")
Как игнорировать знаки препинания при поиске самого длинного слова?
Для игнорирования знаков препинания используйте метод str.strip для удаления символов в начале и конце слова или регулярные выражения для более точной очистки. Пример с re.findall:
import re
words = re.findall(r'\w+', text)
longest = max(words, key=len)
Этот подход позволяет исключить все небуквенные символы и корректно определить длину слова.